
Before Starting..
2017년 NLP를 포함한 지금까지의 딥러닝의 판도를 뒤집어엎는 혁신적인 모델인 'Transformer'가 제안되었다. 이번 포스팅에서 다뤄볼 내용은 Transformer에 대한 자세한 내용이 아니기에 따로 깊이 알아보지는 않겠지만, 이번 포스팅을 이해하기 위해서는 이 모델의 사이즈에 대해서는 알아둘 필요가 있다. Transformer의 사이즈는 465M 개의 파라미터를 가지는 모델이었다. 하지만, 불과 3년 만에 이 사이즈가 정말 작게 느껴지게 할 만큼 큰 사이즈의 모델인 GPT-3(175B)가 나오게 되었다. 그리고 현재까지도 이보다 더 큰 모델들은 계속 나오고 있다. LM의 사이즈가 이렇게 점점 커지게 된 이유는 무엇일까? 그 이유는 Kaplan et al. 2020을 보면 알 수 있다. 그렇다면 이렇게 모델의 사이즈를 계속 늘려가는 것이 모델의 성능을 개선시키기 위한 궁극적인 방법인 것일까? 후속 연구들에 의하면 또 그렇지만은 않다고 한다(Hoffman et al. 2022, Zhou et al. 2023). 이번 포스팅에서는 LM의 scaling law의 변천사에 대해서 한 번 알아보도록 하겠다!
What is the scaling law? 🤔📈
이번 포스팅에서 자세하게 다뤄볼 내용은 scaling law인데, 이 scaling law에 대해서 잘 모르고 있다면 크나큰 낭패이니, 간단하게 짚고 넘어가 보도록 하겠다.
Scaling law는 직역해보면, '규모 증가의 법칙'이라고 해석할 수 있다. 실제 의미도 이름과 크게 다르지 않은데, 간단하게 설명하면 어떤 요소의 수에 변화를 가했을 때 다른 요소가 변화하는 관계라고 생각하면 된다. 실제로 scaling law는 다양한 과학 분야에 사용되는 용어인데, 이것을 컴퓨터 과학에도 적용할 수 있다. 우리가 이번 포스팅에서 다루고자 하는 scaling law는 LM의 scaling law라고 볼 수 있는데, 이때는 'LM의 요소들의 변화에 따른 성능 변화의 법칙'이라고 생각하면 된다.
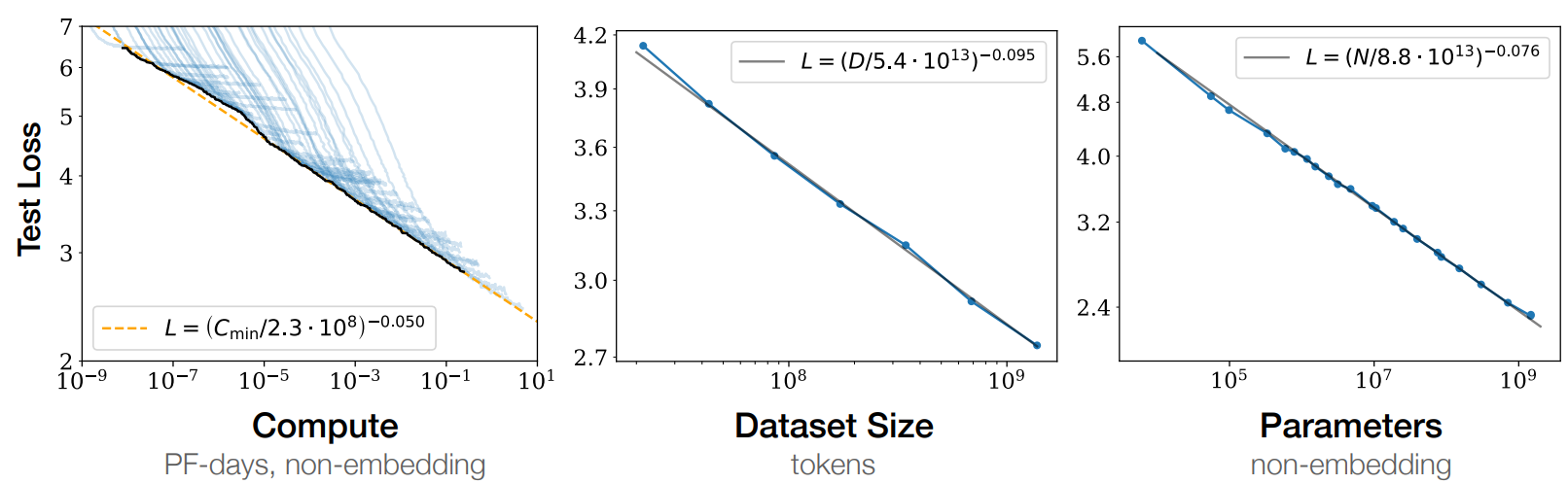
위의 그림은 Kaplan et al. 2020에서 보여주는 scaling law의 예시이다. 여기에서는 scaling law를 compute budget, dataset size, parameters에 변화를 줬을 때 test loss의 변화로 나타내었다. 이를 정리해 보면, LM의 scaling law라는 것은 'LM의 dataset size와 parameter 같은 요소에 변화를 줬을 때 모델의 성능이 어떻게 변하는가' 라고 해석할 수 있다!
Parameters matter most! (2020) 💻
LM의 scaling law를 처음으로 소개하고 제안한 것은 2020년 OpenAI에서 내놓은 논문인 Kaplan, Jared, et al. 'Scaling laws for neural language models.' (2020)이다. 이 논문에서는 LM의 성능이 모델 파라미터의 수, 데이터 크기, 연산 능력과 관련이 있다고 주장한다. 그래서 과연 어떤 요소들이 더 중요하고 덜 중요한지 파악하기 위해 여러 가지 실험을 통해 LM의 scaling law를 밝혀낸다.
이 논문에서 밝혀낸 scaling law는 다음의 그림과 같다.
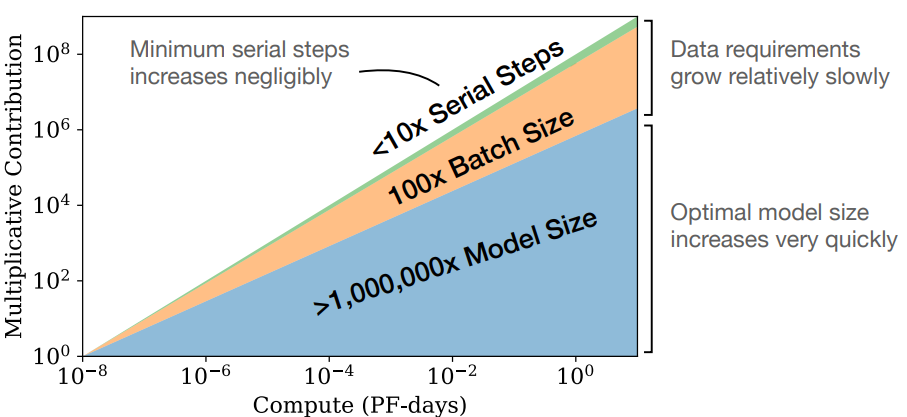
위의 그림은 뭔가 복잡하게 생겼지만, 지레 겁먹을 필요는 없다. 사실 그 속 뜻은 매우 간단하고 명료하기 때문이다. 우선 위 그림이 나오게 된 경위는 더 많은 compute budget을 사용할 때 model size, batch size, training step의 사이즈를 어떻게 늘리는 것이 효과적일까를 알아보기 위해 그려진 것이다. 위의 그림을 보면 알 수 있듯이 model size가 가장 중요하고, 그 다음에 batch size, 마지막으로 training step 순으로 loss 성능에 영향을 미치는 것을 알 수 있다.
이렇게만 말하면 이 논문에서 말하고자 하는 것에 대해서 잘 이해가 가지 않을 것이다. 결국에 이 논문에서 하고자 했던 말을 논문의 Discussion에 있는 한 문장을 인용해서 말해보고자 한다.
'Big models may be more important than big data.'
위의 그림에서도 모델 사이즈가 더 중요하다는 것을 보여줬던 것처럼, 이 논문에서 실험을 통해 밝혀낸 사실은 '큰 모델이 많은 양의 데이터보다 중요하다' 라는 사실이다.
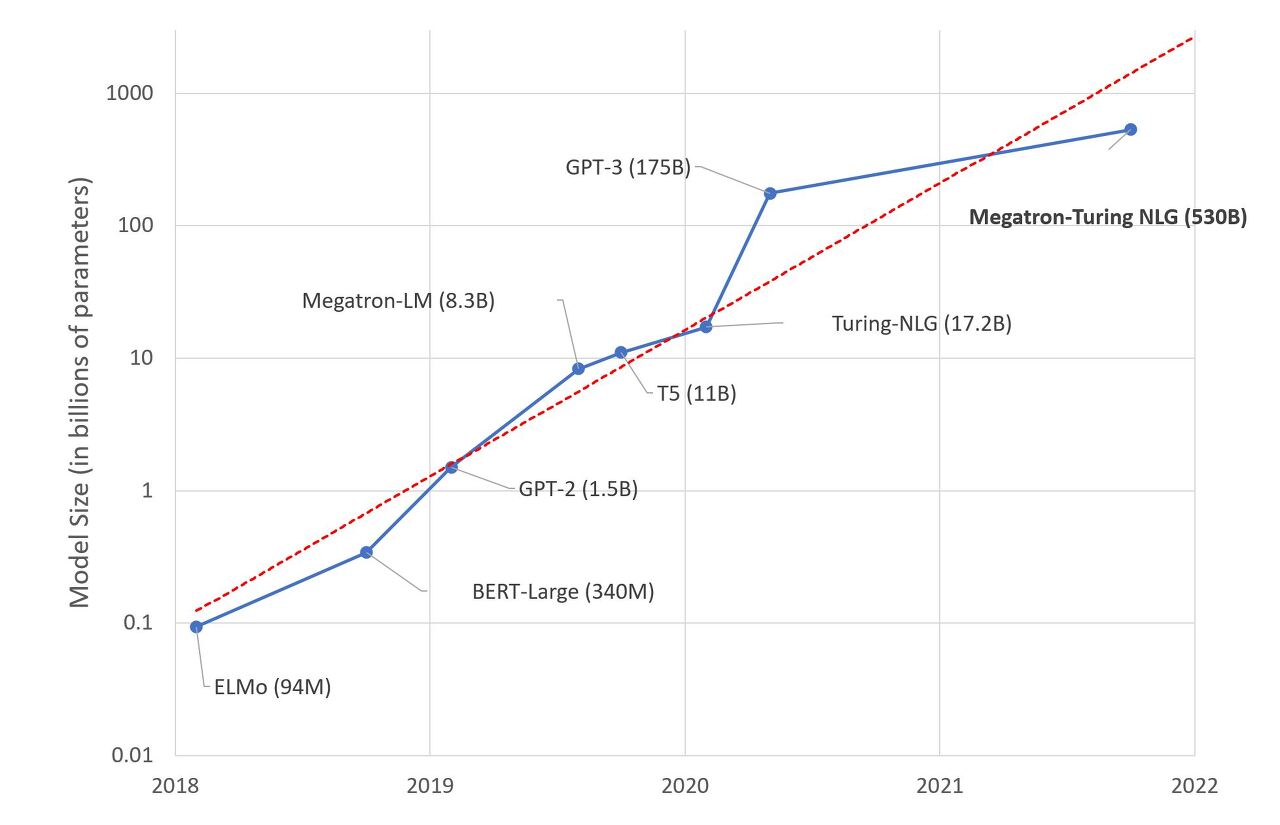
이러한 발견을 기반으로 하여 OpenAI는 같은 년도 5월에 기존의 모델보다 10배가량 커진 1,750억 개의 파라미터를 가지는 LM인 'GPT-3'를 소개하게 된다. 그 이후로도 약 2년 간 LM의 사이즈가 커지는 트렌드는 다음의 그래프처럼 계속된다.
Not only parameters but also data are too important! (2022) 📜
Kaplan et al. 2020의 scaling law는 발표 이후 향후 2년 동안 다양한 연구들에서 광범위하게 사용되며, LM의 scaling trend를 모델 사이즈를 늘리는 방향으로 이끌게 되었다. 하지만, 과연 Kaplan et al. 2020에서 발표한 scaling law가 완벽한 scaling law 였을까? 이러한 의구심은 또 한 번 새로운 scaling law를 제안하는 논문인 Hoffmann, Jordan, et al. 'Training compute-optimal large language models.' (2022)의 발표를 이끌게 되었다. 이 논문에서는 이전의 모델 사이즈 중심적 scaling law를 실험을 통해 비판하면서 좀 더 나은 개선 방안을 제시한다. 여기서 살짝 웃긴 사실은 첫 번째 scaling law도 OpenAI에서 발표한 논문인데, 두 번째 scaling law도 OpenAI에서 발표한 논문이라는 점이다. 🤣
이 논문에서는 주어진 compute budget에서 LM을 학습시키기 위한 최적의 모델 사이즈 & 토큰의 수를 조사하였다. 그 결과 Kaplan et al. 2020의 scaling law를 따르는 모델들은 상당히 under-train 되어 있다는 사실을 발견하였다. 한 마디로 모델의 사이즈만 키우는 것이 모델의 성능 향상을 위한 정답은 아니라는 것이다. 그렇다면 어떠한 방식으로 scaling을 해야 더 나은 성능을 가지는 모델을 만들 수 있는 것일까? 이 질문에 대답하기 위해 논문에서는 다음과 같은 질문에 답하고자 하였다.
'고정된 FLOPs budget이 주어지면, 모델 사이즈와 training token의 수를 어떻게 trade-off 해야 할까?'
이 질문에 대한 대답을 구하기 위해 논문에서는 여러 가지 관점에서 실험을 진행하는데 자세한 내용은 이 포스팅에서 다루지 않도록 하겠다.(자세한 내용이 궁금하다면 Chinchilla review를 참고하길 바람) 결과적으로 이 논문에서 실험을 통해 얻게 되는 하나의 그래프가 있다. 이 그래프는 아래의 그림과 같다.
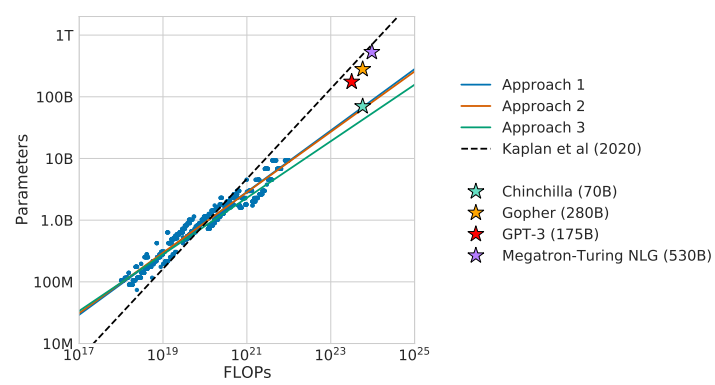
위의 그래프는 Kaplan의 scaling law와 논문에서 제안한 3가지 approach의 scaling law를 보여주고 있다. 기존의 scaling law는 좀 더 경사가 있는 scaling law를 보여주면서 파라미터 수의 증가에 대한 중요성을 보여주지만, 이 논문의 approach들을 보면 파라미터를 너무 많이 증가시킬 필요는 없다는 것을 보여주고 있다. 실제로 논문의 approach들이 제안하는 scaling law는 다음의 표와 같다.
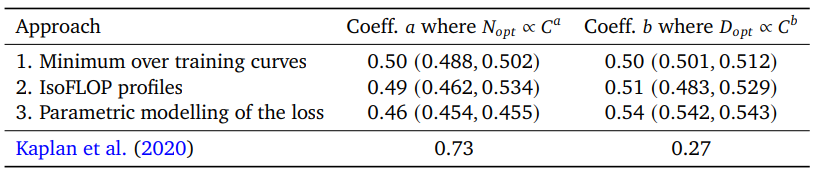
위의 표를 보면 알 수 있듯이 Kaplan의 scaling law는 파라미터 수의 증가를 되게 중요하게 생각하지만, 논문의 approach들을 보면 굳이 그럴 필요 없이 파라미터 수와 데이터의 수를 같은 비율로 증가시키는 것이 더 효과적이라는 것을 보여준다. 이러한 사실을 검증하기 위해 논문에서는 지금까지의 모델들보다 훨씬 더 작은 사이즈의 70B 개의 파라미터 모델에 기존 300B 개의 토큰보다 훨씬 많은 1.4T개의 토큰을 가지는 데이터에서 학습시킴으로써 4배 큰 Gopher 모델보다 뛰어난 성능을 보여줬다! 😲
Less Is Better: LIB..?? LIMA!! (2023) 🤣
이렇게 해서 Kaplan et al. 2020, Hoffman et al. 2022에서 제안한 scaling law까지 알아봤다. 처음의 scaling law에서는 파라미터를 증가시키는 것이 모델의 성능 향상에 중요하다는 것을 제안하였고, 그다음의 scaling law에서는 파라미터만을 늘리는 것은 상당히 under-train 하게 되고, 파라미터를 늘리기보다는 데이터의 수를 늘리는 것이 더 중요하다고 주장하였다. 이렇게 해서 LM의 scaling law는 총 2번의 변화를 거치게 되었다. 그리고 이번에 소개할 논문이 필자는 3번째 scaling law가 될 수 있다고 생각한다. 물론 지금까지는 pre-training data와 모델 사이즈의 관계를 분석하였고, 지금 소개하려는 논문은 fine-tuning data에 대해서 분석을 하기 때문에 살짝 다른 감이 있지만, 비슷한 맥락이라고 생각하여 소개하려 한다! 😁
이번에 소개할 논문은 Meta에서 2023년에 발표한 따끈따끈한 논문인 Zhou, Chunting, et al. 'LIMA: Less Is More for Alignment.' (2023) 이다. 이 논문의 제목을 보면 짐작할 수 있듯이 이 논문에서는 데이터의 양이 그렇게 많을 필요도 없다고 주장한다. 아 물론 여기서 말하는 데이터는 fine-tuning에 사용하는 데이터를 말하는 것이다. 😁 물론 그렇다고 아무렇게나 선택한 데이터에서도 좋은 성능을 보여준다는 얘기는 아니고, LIMA만의 기준으로 선택된 데이터에서 좋은 성능을 보여준다는 것이다. 그래서 실제로 단 1,000개의 instruction data를 사용해서 모델을 fine-tune 하고도 상당히 좋은 성능을 보여준다. 자세한 내용에 대해서 알아보자! (여기서는 간략하게 살펴보는데 더욱 구체적인 내용이 궁금하다면 LIMA review를 확인하길 바람)
'모델의 지식과 능력은 대부분 pre-training 중에 학습된다. 그리고 fine-tuning은 사용자와
상호작용을 할 때 사용되는 포맷의 하위 분포를 가르치는 것임'
LIMA 논문에서는 모델은 이미 pre-training 중에 대부분의 지식과 능력을 학습하게 되고, fine-tuning은 모델이 사용자들과 상호작용 하기 위한 스타일 또는 형식을 학습하는 간단한 프로세스일 수도 있다고 가정하였다. 그래서 실제 사용자 prompt와 high-quality reponse에 가까운 1,000개의 example을 엄선하여 LLaMA-65B를 fine-tune 하여 'LIMA'를 만들어 내고, 여러 모델들과 비교해본다. 그래서 다음과 같은 데이터셋들에서 샘플링을 통해 1,000개의 prompt & response 데이터셋을 수집하였다.
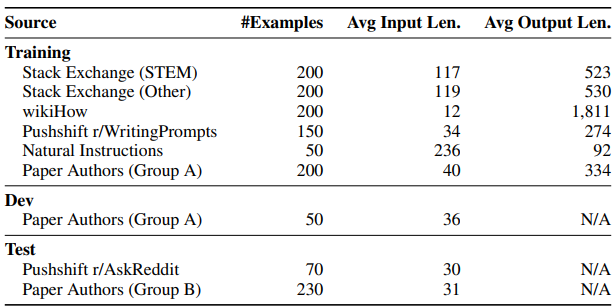
위의 1,000개의 데이터를 사용해서 fine-tuning 하여 LIMA를 얻게 되었다. 그렇다면 이제 실제로 이 LIMA가 좋은 성능을 보여주는지 검증을 거쳐야 할 시간이다! LIMA는 human evaluation과 model evaluation을 모두 거치는데 아래 그림의 왼쪽이 human preference evaluation, 오른쪽이 GPT-4 preference evaluation의 결과이다.
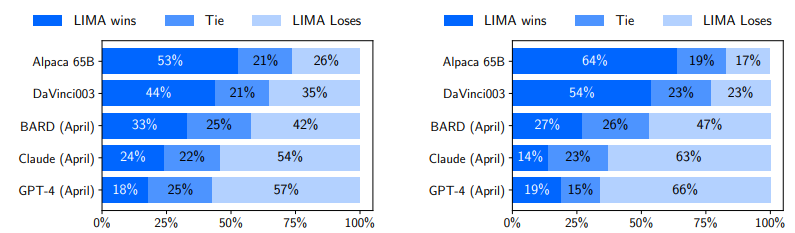
위의 그림을 보면 알 수 있듯이 LIMA는 똑같은 base model과 똑같은 사이즈의 모델을 사용하고, 더 많은 데이터를 사용하여 fine-tuning한 Alpaca 65B보다 훨씬 좋은 성능을 보여주고, 크기가 더 크고 더 많은 데이터를 사용하여 fine-tuning 한 text-davinci-003보다도 나은 성능을 보여준다. 다른 proprietary LM보다는 떨어지는 성능을 보여주지만, 그래도 따지고 보면 43%의 응답에서 GPT-4와 비슷하거나 더 나은 수준의 성능을 보여준다고 할 수 있다!
이렇듯 지금까지와는 다르게 상당히 적지만, 그만큼 좋은 퀄리티의 데이터를 사용하여 fine-tuning하는 것도 상당히 모델의 성능 향상에 도움이 된다는 것을 보여준다. 이로 인해 fine-tuning data는 실제로 그렇게 많은 양이 필요하지 않다는 것을 보여줄 수 있게 되었다. 실제로 LIMA의 이러한 concept를 베이스로 해서 모델의 성능을 개선시키거나 효율적인 method를 제안한 연구들도 있다! (Chen et al. 2023, Alshikh et al. 2023)
In the future.. ✨
이렇게 해서 지금까지 제안된 굵직굵직한 LM의 scaling law에 대해서 알아봤다. 처음에 소개된 파라미터를 중요시 여기는 Kaplan의 scaling law에서, 데이터와 파라미터의 똑같은 비율로 증가시키는 Chinchilla scaling law를 거쳐서, 마지막에는 좀 더 적지만 high-quality 데이터를 사용하여 fine-tuning 하는 LIMA까지 알아보았다. 이렇듯 LM의 scaling law는 시간이 지남에 따라 좀 더 심도 있는 연구를 통해 단점이 드러나게 되고 또 새로운 scaling law가 발표되어 간다. 따라서 지금의 scaling law도 언젠가는 단점이 지적되고 또 다른 scaling law가 발표될 것이라고 생각한다. 물론 아직 그 시점이 오지 않았기에 정확히 어떻게 더 개선된 scaling law가 제안될지는 잘 모르지만, 향후에는 모델의 성능과 cost 측면에서 좀 더 효율적이고 효과적인 scaling law가 발표되지 않을까 라는 생각을 던져본다 ㅎㅎ
포스팅을 끝까지 봐주셔서 감사하고, 이 글을 읽어주신 분들께서도 의견을 알려주셨으면 좋겠습니다! 그리고 잘못된 점이나 이상한 점 지적은 언제나 환영입니다!! 이만 포스팅을 마쳐보도록 하겠습니다! 다음에 더 좋은 글로 찾아뵙도록 하겠습니다! 😊😊
출처
https://arxiv.org/abs/2001.08361
Scaling Laws for Neural Language Models
We study empirical scaling laws for language model performance on the cross-entropy loss. The loss scales as a power-law with model size, dataset size, and the amount of compute used for training, with some trends spanning more than seven orders of magnitu
arxiv.org
https://arxiv.org/abs/2203.15556
Training Compute-Optimal Large Language Models
We investigate the optimal model size and number of tokens for training a transformer language model under a given compute budget. We find that current large language models are significantly undertrained, a consequence of the recent focus on scaling langu
arxiv.org
https://arxiv.org/abs/2305.11206
LIMA: Less Is More for Alignment
Large language models are trained in two stages: (1) unsupervised pretraining from raw text, to learn general-purpose representations, and (2) large scale instruction tuning and reinforcement learning, to better align to end tasks and user preferences. We
arxiv.org
'Insight 😎' 카테고리의 다른 글
| 당신도 Fine-tuning 할 수 있습니다! with PEFT 🤗 (0) | 2023.08.01 |
|---|---|
| ChatGPT의 성능이 안 좋아지고 있다구?!?!? 😲😲 (0) | 2023.07.31 |
| LM을 가장 최적으로 평가할 수 있는 방법은 무엇일까? 😎 (1) | 2023.07.27 |
| LM의 context window, 길어야 할까? 짧아야 할까? 📏🤨 (0) | 2023.07.26 |
| Closed-source🔒? Open-source🔓? 그게 뭔데?? 🤨🤔 (0) | 2023.07.25 |
Before Starting..
2017년 NLP를 포함한 지금까지의 딥러닝의 판도를 뒤집어엎는 혁신적인 모델인 'Transformer'가 제안되었다. 이번 포스팅에서 다뤄볼 내용은 Transformer에 대한 자세한 내용이 아니기에 따로 깊이 알아보지는 않겠지만, 이번 포스팅을 이해하기 위해서는 이 모델의 사이즈에 대해서는 알아둘 필요가 있다. Transformer의 사이즈는 465M 개의 파라미터를 가지는 모델이었다. 하지만, 불과 3년 만에 이 사이즈가 정말 작게 느껴지게 할 만큼 큰 사이즈의 모델인 GPT-3(175B)가 나오게 되었다. 그리고 현재까지도 이보다 더 큰 모델들은 계속 나오고 있다. LM의 사이즈가 이렇게 점점 커지게 된 이유는 무엇일까? 그 이유는 Kaplan et al. 2020을 보면 알 수 있다. 그렇다면 이렇게 모델의 사이즈를 계속 늘려가는 것이 모델의 성능을 개선시키기 위한 궁극적인 방법인 것일까? 후속 연구들에 의하면 또 그렇지만은 않다고 한다(Hoffman et al. 2022, Zhou et al. 2023). 이번 포스팅에서는 LM의 scaling law의 변천사에 대해서 한 번 알아보도록 하겠다!
What is the scaling law? 🤔📈
이번 포스팅에서 자세하게 다뤄볼 내용은 scaling law인데, 이 scaling law에 대해서 잘 모르고 있다면 크나큰 낭패이니, 간단하게 짚고 넘어가 보도록 하겠다.
Scaling law는 직역해보면, '규모 증가의 법칙'이라고 해석할 수 있다. 실제 의미도 이름과 크게 다르지 않은데, 간단하게 설명하면 어떤 요소의 수에 변화를 가했을 때 다른 요소가 변화하는 관계라고 생각하면 된다. 실제로 scaling law는 다양한 과학 분야에 사용되는 용어인데, 이것을 컴퓨터 과학에도 적용할 수 있다. 우리가 이번 포스팅에서 다루고자 하는 scaling law는 LM의 scaling law라고 볼 수 있는데, 이때는 'LM의 요소들의 변화에 따른 성능 변화의 법칙'이라고 생각하면 된다.
위의 그림은 Kaplan et al. 2020에서 보여주는 scaling law의 예시이다. 여기에서는 scaling law를 compute budget, dataset size, parameters에 변화를 줬을 때 test loss의 변화로 나타내었다. 이를 정리해 보면, LM의 scaling law라는 것은 'LM의 dataset size와 parameter 같은 요소에 변화를 줬을 때 모델의 성능이 어떻게 변하는가' 라고 해석할 수 있다!
Parameters matter most! (2020) 💻
LM의 scaling law를 처음으로 소개하고 제안한 것은 2020년 OpenAI에서 내놓은 논문인 Kaplan, Jared, et al. 'Scaling laws for neural language models.' (2020)이다. 이 논문에서는 LM의 성능이 모델 파라미터의 수, 데이터 크기, 연산 능력과 관련이 있다고 주장한다. 그래서 과연 어떤 요소들이 더 중요하고 덜 중요한지 파악하기 위해 여러 가지 실험을 통해 LM의 scaling law를 밝혀낸다.
이 논문에서 밝혀낸 scaling law는 다음의 그림과 같다.
위의 그림은 뭔가 복잡하게 생겼지만, 지레 겁먹을 필요는 없다. 사실 그 속 뜻은 매우 간단하고 명료하기 때문이다. 우선 위 그림이 나오게 된 경위는 더 많은 compute budget을 사용할 때 model size, batch size, training step의 사이즈를 어떻게 늘리는 것이 효과적일까를 알아보기 위해 그려진 것이다. 위의 그림을 보면 알 수 있듯이 model size가 가장 중요하고, 그 다음에 batch size, 마지막으로 training step 순으로 loss 성능에 영향을 미치는 것을 알 수 있다.
이렇게만 말하면 이 논문에서 말하고자 하는 것에 대해서 잘 이해가 가지 않을 것이다. 결국에 이 논문에서 하고자 했던 말을 논문의 Discussion에 있는 한 문장을 인용해서 말해보고자 한다.
'Big models may be more important than big data.'
위의 그림에서도 모델 사이즈가 더 중요하다는 것을 보여줬던 것처럼, 이 논문에서 실험을 통해 밝혀낸 사실은 '큰 모델이 많은 양의 데이터보다 중요하다' 라는 사실이다.
이러한 발견을 기반으로 하여 OpenAI는 같은 년도 5월에 기존의 모델보다 10배가량 커진 1,750억 개의 파라미터를 가지는 LM인 'GPT-3'를 소개하게 된다. 그 이후로도 약 2년 간 LM의 사이즈가 커지는 트렌드는 다음의 그래프처럼 계속된다.
Not only parameters but also data are too important! (2022) 📜
Kaplan et al. 2020의 scaling law는 발표 이후 향후 2년 동안 다양한 연구들에서 광범위하게 사용되며, LM의 scaling trend를 모델 사이즈를 늘리는 방향으로 이끌게 되었다. 하지만, 과연 Kaplan et al. 2020에서 발표한 scaling law가 완벽한 scaling law 였을까? 이러한 의구심은 또 한 번 새로운 scaling law를 제안하는 논문인 Hoffmann, Jordan, et al. 'Training compute-optimal large language models.' (2022)의 발표를 이끌게 되었다. 이 논문에서는 이전의 모델 사이즈 중심적 scaling law를 실험을 통해 비판하면서 좀 더 나은 개선 방안을 제시한다. 여기서 살짝 웃긴 사실은 첫 번째 scaling law도 OpenAI에서 발표한 논문인데, 두 번째 scaling law도 OpenAI에서 발표한 논문이라는 점이다. 🤣
이 논문에서는 주어진 compute budget에서 LM을 학습시키기 위한 최적의 모델 사이즈 & 토큰의 수를 조사하였다. 그 결과 Kaplan et al. 2020의 scaling law를 따르는 모델들은 상당히 under-train 되어 있다는 사실을 발견하였다. 한 마디로 모델의 사이즈만 키우는 것이 모델의 성능 향상을 위한 정답은 아니라는 것이다. 그렇다면 어떠한 방식으로 scaling을 해야 더 나은 성능을 가지는 모델을 만들 수 있는 것일까? 이 질문에 대답하기 위해 논문에서는 다음과 같은 질문에 답하고자 하였다.
'고정된 FLOPs budget이 주어지면, 모델 사이즈와 training token의 수를 어떻게 trade-off 해야 할까?'
이 질문에 대한 대답을 구하기 위해 논문에서는 여러 가지 관점에서 실험을 진행하는데 자세한 내용은 이 포스팅에서 다루지 않도록 하겠다.(자세한 내용이 궁금하다면 Chinchilla review를 참고하길 바람) 결과적으로 이 논문에서 실험을 통해 얻게 되는 하나의 그래프가 있다. 이 그래프는 아래의 그림과 같다.
위의 그래프는 Kaplan의 scaling law와 논문에서 제안한 3가지 approach의 scaling law를 보여주고 있다. 기존의 scaling law는 좀 더 경사가 있는 scaling law를 보여주면서 파라미터 수의 증가에 대한 중요성을 보여주지만, 이 논문의 approach들을 보면 파라미터를 너무 많이 증가시킬 필요는 없다는 것을 보여주고 있다. 실제로 논문의 approach들이 제안하는 scaling law는 다음의 표와 같다.
위의 표를 보면 알 수 있듯이 Kaplan의 scaling law는 파라미터 수의 증가를 되게 중요하게 생각하지만, 논문의 approach들을 보면 굳이 그럴 필요 없이 파라미터 수와 데이터의 수를 같은 비율로 증가시키는 것이 더 효과적이라는 것을 보여준다. 이러한 사실을 검증하기 위해 논문에서는 지금까지의 모델들보다 훨씬 더 작은 사이즈의 70B 개의 파라미터 모델에 기존 300B 개의 토큰보다 훨씬 많은 1.4T개의 토큰을 가지는 데이터에서 학습시킴으로써 4배 큰 Gopher 모델보다 뛰어난 성능을 보여줬다! 😲
Less Is Better: LIB..?? LIMA!! (2023) 🤣
이렇게 해서 Kaplan et al. 2020, Hoffman et al. 2022에서 제안한 scaling law까지 알아봤다. 처음의 scaling law에서는 파라미터를 증가시키는 것이 모델의 성능 향상에 중요하다는 것을 제안하였고, 그다음의 scaling law에서는 파라미터만을 늘리는 것은 상당히 under-train 하게 되고, 파라미터를 늘리기보다는 데이터의 수를 늘리는 것이 더 중요하다고 주장하였다. 이렇게 해서 LM의 scaling law는 총 2번의 변화를 거치게 되었다. 그리고 이번에 소개할 논문이 필자는 3번째 scaling law가 될 수 있다고 생각한다. 물론 지금까지는 pre-training data와 모델 사이즈의 관계를 분석하였고, 지금 소개하려는 논문은 fine-tuning data에 대해서 분석을 하기 때문에 살짝 다른 감이 있지만, 비슷한 맥락이라고 생각하여 소개하려 한다! 😁
이번에 소개할 논문은 Meta에서 2023년에 발표한 따끈따끈한 논문인 Zhou, Chunting, et al. 'LIMA: Less Is More for Alignment.' (2023) 이다. 이 논문의 제목을 보면 짐작할 수 있듯이 이 논문에서는 데이터의 양이 그렇게 많을 필요도 없다고 주장한다. 아 물론 여기서 말하는 데이터는 fine-tuning에 사용하는 데이터를 말하는 것이다. 😁 물론 그렇다고 아무렇게나 선택한 데이터에서도 좋은 성능을 보여준다는 얘기는 아니고, LIMA만의 기준으로 선택된 데이터에서 좋은 성능을 보여준다는 것이다. 그래서 실제로 단 1,000개의 instruction data를 사용해서 모델을 fine-tune 하고도 상당히 좋은 성능을 보여준다. 자세한 내용에 대해서 알아보자! (여기서는 간략하게 살펴보는데 더욱 구체적인 내용이 궁금하다면 LIMA review를 확인하길 바람)
'모델의 지식과 능력은 대부분 pre-training 중에 학습된다. 그리고 fine-tuning은 사용자와
상호작용을 할 때 사용되는 포맷의 하위 분포를 가르치는 것임'
LIMA 논문에서는 모델은 이미 pre-training 중에 대부분의 지식과 능력을 학습하게 되고, fine-tuning은 모델이 사용자들과 상호작용 하기 위한 스타일 또는 형식을 학습하는 간단한 프로세스일 수도 있다고 가정하였다. 그래서 실제 사용자 prompt와 high-quality reponse에 가까운 1,000개의 example을 엄선하여 LLaMA-65B를 fine-tune 하여 'LIMA'를 만들어 내고, 여러 모델들과 비교해본다. 그래서 다음과 같은 데이터셋들에서 샘플링을 통해 1,000개의 prompt & response 데이터셋을 수집하였다.
위의 1,000개의 데이터를 사용해서 fine-tuning 하여 LIMA를 얻게 되었다. 그렇다면 이제 실제로 이 LIMA가 좋은 성능을 보여주는지 검증을 거쳐야 할 시간이다! LIMA는 human evaluation과 model evaluation을 모두 거치는데 아래 그림의 왼쪽이 human preference evaluation, 오른쪽이 GPT-4 preference evaluation의 결과이다.
위의 그림을 보면 알 수 있듯이 LIMA는 똑같은 base model과 똑같은 사이즈의 모델을 사용하고, 더 많은 데이터를 사용하여 fine-tuning한 Alpaca 65B보다 훨씬 좋은 성능을 보여주고, 크기가 더 크고 더 많은 데이터를 사용하여 fine-tuning 한 text-davinci-003보다도 나은 성능을 보여준다. 다른 proprietary LM보다는 떨어지는 성능을 보여주지만, 그래도 따지고 보면 43%의 응답에서 GPT-4와 비슷하거나 더 나은 수준의 성능을 보여준다고 할 수 있다!
이렇듯 지금까지와는 다르게 상당히 적지만, 그만큼 좋은 퀄리티의 데이터를 사용하여 fine-tuning하는 것도 상당히 모델의 성능 향상에 도움이 된다는 것을 보여준다. 이로 인해 fine-tuning data는 실제로 그렇게 많은 양이 필요하지 않다는 것을 보여줄 수 있게 되었다. 실제로 LIMA의 이러한 concept를 베이스로 해서 모델의 성능을 개선시키거나 효율적인 method를 제안한 연구들도 있다! (Chen et al. 2023, Alshikh et al. 2023)
In the future.. ✨
이렇게 해서 지금까지 제안된 굵직굵직한 LM의 scaling law에 대해서 알아봤다. 처음에 소개된 파라미터를 중요시 여기는 Kaplan의 scaling law에서, 데이터와 파라미터의 똑같은 비율로 증가시키는 Chinchilla scaling law를 거쳐서, 마지막에는 좀 더 적지만 high-quality 데이터를 사용하여 fine-tuning 하는 LIMA까지 알아보았다. 이렇듯 LM의 scaling law는 시간이 지남에 따라 좀 더 심도 있는 연구를 통해 단점이 드러나게 되고 또 새로운 scaling law가 발표되어 간다. 따라서 지금의 scaling law도 언젠가는 단점이 지적되고 또 다른 scaling law가 발표될 것이라고 생각한다. 물론 아직 그 시점이 오지 않았기에 정확히 어떻게 더 개선된 scaling law가 제안될지는 잘 모르지만, 향후에는 모델의 성능과 cost 측면에서 좀 더 효율적이고 효과적인 scaling law가 발표되지 않을까 라는 생각을 던져본다 ㅎㅎ
포스팅을 끝까지 봐주셔서 감사하고, 이 글을 읽어주신 분들께서도 의견을 알려주셨으면 좋겠습니다! 그리고 잘못된 점이나 이상한 점 지적은 언제나 환영입니다!! 이만 포스팅을 마쳐보도록 하겠습니다! 다음에 더 좋은 글로 찾아뵙도록 하겠습니다! 😊😊
출처
https://arxiv.org/abs/2001.08361
Scaling Laws for Neural Language Models
We study empirical scaling laws for language model performance on the cross-entropy loss. The loss scales as a power-law with model size, dataset size, and the amount of compute used for training, with some trends spanning more than seven orders of magnitu
arxiv.org
https://arxiv.org/abs/2203.15556
Training Compute-Optimal Large Language Models
We investigate the optimal model size and number of tokens for training a transformer language model under a given compute budget. We find that current large language models are significantly undertrained, a consequence of the recent focus on scaling langu
arxiv.org
https://arxiv.org/abs/2305.11206
LIMA: Less Is More for Alignment
Large language models are trained in two stages: (1) unsupervised pretraining from raw text, to learn general-purpose representations, and (2) large scale instruction tuning and reinforcement learning, to better align to end tasks and user preferences. We
arxiv.org
'Insight 😎' 카테고리의 다른 글
| 당신도 Fine-tuning 할 수 있습니다! with PEFT 🤗 (0) | 2023.08.01 |
|---|---|
| ChatGPT의 성능이 안 좋아지고 있다구?!?!? 😲😲 (0) | 2023.07.31 |
| LM을 가장 최적으로 평가할 수 있는 방법은 무엇일까? 😎 (1) | 2023.07.27 |
| LM의 context window, 길어야 할까? 짧아야 할까? 📏🤨 (0) | 2023.07.26 |
| Closed-source🔒? Open-source🔓? 그게 뭔데?? 🤨🤔 (0) | 2023.07.25 |