
The overview of this paper
open-domain instruction과 함께 LLM을 학습시키는 것은 상당한 성공을 가져왔다. 이 논문에서는 사람 대신에 LLM을 사용해서 다양한 레벨의 복잡도를 가지는 많은 양의 instruction data를 생성하기 위한 방안을 보여준다. 초기 instruction set와 함께 시작해서, 이 instruction set를 Evol-instruct를 사용해서 더욱 복잡한 instruction으로 step-by-step 작성하였다. 그다음에, 모든 생성된 instruction 데이터를 LLaMA를 fine-tune 하기 위해 섞었다. 이렇게 해서 나온 모델이 바로 WizardLM이다.
Human Evaluation & Vicuna Evaluation은 Evol-Instruct의 instruction이 human-created instruction보다 우수하다는 것을 보여준다.

Table of Contents
1. Introduction
2. Approach
3. Experiment
1. Introduction
LLM은 종종 instruction을 따르거나 사용자에 의해 명시된 목표를 따르는데 어려움을 겪는다. 이로 인해 LLM의 유용성과 활용성은 제한되고 만다.
최근의 NLP 연구들은 이 LLM을 closed-domain instruction에서 학습시키고자 하였다. 하지만, 이러한 closed-domain instruction은 다음의 2가지 주요 결점을 가지고 있다.
- NLP dataset의 모든 샘플은 오직 소수의 일반적인 instruction만을 공유해서, 심각한 다양성 제한을 겪음
- 이 데이터셋에 속한 instruction은 대게 하나의 task에 대해서만 질문함
이 논문에서는 다양한 difficulty level의 open-domain을 자동적으로 mass-produce하기 위해 사람 대신에 LLM을 사용한 새로운 method로 LLM의 성능을 개선시킨 Evol-Instruct를 소개하였다. 그림 1은 Evol-Instruct의 실행 예시를 보여준다. 간단한 초기 instruction에서 시작해서, Evol-Instruct는 더욱 복잡하거나 새로운 instruction을 생성하기 위한 간단한 instruction을 업그레이드하기 위해 In-depth Evolving 또는 In-breadth Evolving 중에 랜덤 하게 선택한다. In-depth Evolving은 다음의 5가지의 operation을 포함하고 있다: add constraints, deepening, concretizing, increase reasoning steps, complicate input. In-breadth Evolving은 변화 과정으로, 예를 들어 주어진 instruction에 기반해서 완전히 새로운 instruction 생성하는 등의 변환이다. 이러한 6개의 operation은 LLM을 구체적 prompt와 함께 prompting 함으로써 구현된다. evolved instruction은 LLM으로부터 생성되기 때문에 가끔 진화에 실패하기도 한다. 그래서, failed instruction을 필터링하기 위해 Elimination Evolving 이라 불리는 instruction eliminator를 사용한다. 이 프로세스를 다양한 복잡도를 함유하는 충분한 instruction data를 수집할 때까지 반복한다.

논문에서는 Evol-Instruct를 입증하기 위해 LLaMA를 evolved instruction과 함께 fine-tune 하고, 그 결과 instruction tuning에서 기존의 SoTA(Alpaca & VIcuna)와 비슷한 성능을 보여줬다. 논문에서는 Alpaca의 training data에 Evol-Instruct를 거친 후 얻은 250K 개의 instruction data에서 LLaMA 7B 모델을 학습시켰는데, 그 모델이 바로 WizardLM이다. 이전 instruction-following test dataset의 difficult instruction의 낮은 비율 때문에, 논문에서는 Evol-Instruct testset이라 부르는 새로운 difficulty-balanced test dataset을 만들었다. 논문의 contribution은 다음과 같다:
- Evol-Instruct의 instruction은 human-created ShareGPT 보다 우수함. LLaMA 7B를 fine-tuning 하기 위해 Vicuna와 동일한 양의 Evol-Instruct 데이터(70K)를 사용하면 WizardLM이 Vicuna를 훨씬 능가한다. 게다가, GPT-4 평가에서 Alpaca와 Vicuna 보다 나은 응답 퀄리티를 달성한다.
- 라벨러는 복잡한 test instruction 하에서 ChatGPT의 output보다 WizardLM의 output을 더 선호함. Evol-Instruct testset에서, WizardLM은 ChatGPT 보다 떨어지는 성능을 보여줬으나, Evol-Instruct test set의 high-difficulty 섹션에서 WizardLM은 ChatGPT를 능가하였다. 이것은 human annotator 또한 WizardLM의 output을 ChatGPT의 output을 어려운 question에서 더 선호한다는 의미이다.
2. Approach

2-1. Definition of Instruction Data Evolution
논문에서는 주어진 초기 instruction dataset $D^{(0)} = (I_{k}^{(0)}, R_{k}^{(0)})_{1 \leq k \leq N}$로부터 진화를 시작한다. 여기서 $I_{k}^{(0)}$은 $D^{(0)}$의 $k$번째 instruction이고, $R_{k}^{(0)}$는 $k$번째 instruction에 대한 해당 응답이고, $N$은 $D^{(0)}$에서 샘플의 수이다. LLM Instruction evolution prompt를 적용함으로써 $I^{(t)}$를 $I^{(t+1)}$로 업그레이드 하였다. 그다음에 LLM을 사용해서 새롭게 진화된 $I^{(t+1)}$에 대한 해당 응답 $R^{t+1}$을 생성하였다. 이렇게 해서 진화된 instruction dataset $D^{t+1}$을 얻을 수 있었다.
2-2. Automatic Instruction Data Evolution
instruction evolution을 위한 pipeline은 다음의 3개의 스텝으로 구성되어 있다.
- instruction evolving
- response generation
- elimination evolving
Instruction Evolution. 논문에서는 difficulty level을 개선시키고 풍부함과 다양성을 확장시키는 방식을 통해 반복적으로 초기 isntruction 데이터셋을 진화시킬 수 있다. 논문에서는 evolved instruction 데이터셋을 만든 후에, instruction evolver를 활용해서 각 fetched instruction을 진화시키고, instruction elimination을 사용해서 진화가 실패했는지 아닌지를 확인한다. 성공적으로 진화된 instruction은 pool에 추가되는 반면, 성공적이지 못한 instruction은 다시 되돌아가서 다음 진화 epoch에 성공되길 바란다.
Instruction Evolver. Instruction Evolver는 2가지 유형으로 instruction을 진화시키기 위한 prompt를 사용한다: in-depth evolving & in-breadth evolving.
Prompts of In-Depth Evolving. In-Depth Evolving은 5가지 유형의 prompt를 통해 instruction을 더욱 복잡하고 어렵게 만듦으로써 향상시킨다: add constraints, deepening, concretizing, increase reasoning steps, complicate input. In-Depth Evolving prompt의 핵심 부분은 "너의 목표는 주어진 prompt를 유명 AI 시스템을 조근 더 다루기 힘들게 만들도록 더욱 복잡한 버전으로 재작성하는 것이다. 하지만, 재작성된 prompt는 사람에 의해 합리적이고, 이해 가능하고, 응답될 수 있어야 한다."이다. 논문에서는 LM이 합리적이고 AI에 의해 임의로 상상되지 않는 어려운 instruction을 생성하도록 요구한다. 또한 instruction set를 극도로 복잡한 instruction으로 채우는 것을 피하기 위해 점진적 어려움 증가를 필수적으로 해야 한다. 다음은 'add constrainrs'의 prompt 예시이다.

그리고 복잡한 input에 대해, in-context demonstration을 사용할 것이다. 다음이 그 예시이다.

Prompts of In-Breadth Evolving. In-Breadth Evolving은 토픽 범위, 스킬 범위, 전반적인 데이터셋 다양성을 향상시키는데 초점을 둔다. 논문에서는 이를 위해 주어진 instruction에 기반해서 완전히 새로운 instruction을 생성하기 위한 prompt를 고안하였다. 그리고 새로운 instruction은 더욱 long-tail 해야 한다. 다음은 In-Breadth Evolving prompt의 예시이다.

Response Generation. 논문에서는 evolved instruction에 해당하는 응답을 생성하기 위해 evolution을 위한 LLM과 똑같은 모델을 사용하였다. 생성 prompt는 "<Here is instruction.>"이다.
Elimination Evolving. 논문에서는 다음의 4가지 상황을 evolution failure로 분류하였다:
- evolved instruction이 기존의 것과 비교해서 어떠한 정보 획득도 제공하지 않음
- evolved instruction이 LLM의 응답을 생성하는데 어렵게 만듦
- LLM에 의해 생성된 응답이 오직 구두점과 불용어만을 포함
- evolved instruction은 evolution prompt로부터 확실히 몇 단어를 카피함
2-3. Finetuning the LLM on the Evolved Instructions
모든 evolution이 끝나면, 초기 instruction dataset + evolved instruction data를 합쳤다. 이 프로세싱은 데이텃세에서 difficulty level의 분포를 보장해 주는 방식으로 합쳐진다. 논문에서는 fine-tuned model이 open-domain instruction을 다룰 수 있다는 것을 보장하기 위해 이전 instruction tuning 연구의 복잡하거나 다양한 prompt 사용을 피하였다.
3. Experiment
논문에서는 WizardLM, Alpaca, Vicuna, ChatGPT를 Evol-Instruct & Vicuna testset에서 automatic & human evaluation을 모두 사용해서 평가하였다.
3-1. Testset build
논문에서는 다양한 소스의 real-world human instruction을 포함하는 Evol-instruct testset을 수집하였다. 그림 3a는 testset에서 인스턴스와 스킬의 분포를 묘사한다. Evol-Instruct testset에서 각각의 instance는 구체적 스킬에 대한 instruction이다. 논문에서는 Vicuna testset에 비해 Evol-Instruct testset은 서로 다른 레벨의 어려움과 복잡도를 가지는 instruction을 포함하는 더욱 균일한 분포를 가진다는 것을 발견하였다. 이에 반해, Vicuna & Alpaca는 낮은 어려움과 복잡도를 가지는 instruction을 주로 포함한다. 이것은 이 2개의 corpus가 평가를 더욱 복잡하고 필요로 하는 시나리오에서 평가를 할 수 없다는 것을 가리킨다.

3-2. Human Evaluation
WizardLM을 평가하기 위해, 논문에서는 Evol-Instruct testset에서 human evaluation을 수행하였다. 그리고 win rate를 측정하기 위해, 모델의 각 쌍 간에 win, lost, tie의 빈도를 비교하였다.
Main Results. 실험의 결과는 그림 4에 나타나있다. WizardLM은 Alpaca & Vicuna-7B보다 상당히 나은 결과를 달성하였다. 이것은 Evol-Instruct의 효과를 설명해준다.

Performance on high-difficulty. 그림 4c는 WizardLM이 high-difficulty instruction에서 human labeler에 의해 ChatGPT보다 더 선호되는 경우가 많았음을 가리킨다.
3-3. GPT-4 automatic evaluation
논문에서는 Vicuna에 의해 제안된 GPT-4에 기반한 자동 평가 프레임워크를 채택해서 ChatGPT 모델의 성능을 평가하였다. 그림 5a와 5b에서 보이는 것처럼 WizardLM은 Evol-Instruct testset에서 Alpaca와 Vicuna를 큰 마진으로 능가하였고, Vicuna testset에서는 Vicuna-7B와 유사한 성능을 보여줬다.

Performance on differenct skills. 그림 6은 Evol-Instruct testset에서 WizardLM과 ChatGPT의 스킬 레벨을 비교하였다. 결과는 Evol-Instruct testset에서 WizardLM은 평균적으로 ChatGPT 성능의 78%를 달성하였다. 그리고 17개의 스킬에서 90% 이상의 능력을 달성하였다. 하지만, ChatGPT와의 갭 때문에 WizardLM은 코딩, 수학, 추론 시나리오 등의 task에서 어려움을 겪었다.

Performance on differenct difficulty degrees. 그림 5c에 보이는 것처럼, WizardLM은 모든 difficulty level에서 Vicuna를 능가하고, easy & hard skill에서 Alpaca를 능가하였고, hard skill에서 ChatGPT의 88%에 달하는 역량을 보여줬다. 이것은 WizardLM은 복잡한 문제를 해결하고 LLM training을 위한 복잡한 데이터 수집에 드는 human effort를 줄일 수 있다는 것을 제안한다.
3-4. Discussion
In-Depth는 Human Instruction을 능가함. Evol-Instruct가 생성한 instruction은 ShareGPT의 사람 지원자에 의해 생성된 것보다 더욱 복잡하다. 그림 7은 이를 묘사한다. 게다가, instruction depth는 진화 프로세스의 각 반복과 함께 상당히 증가한다.
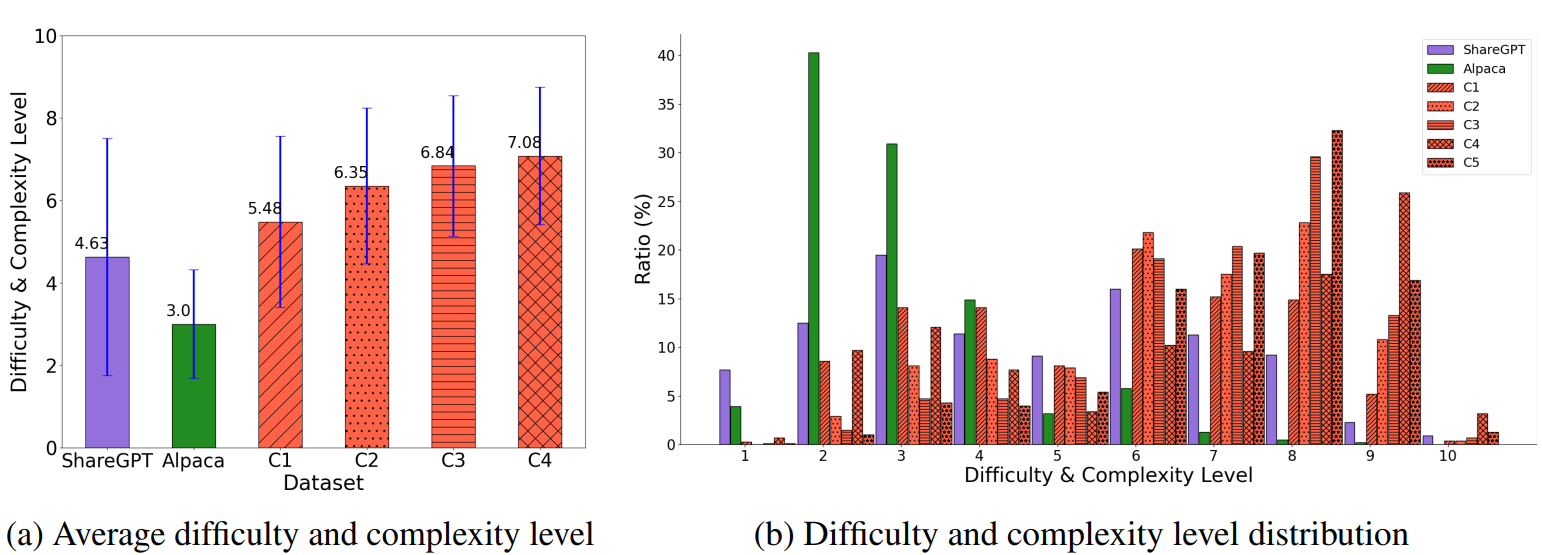
In-breadth는 Human Instruction을 능가함. ShareGPT & Alpaca와 비교해서 In-Breadth는 큰 토픽 다양성을 가리킨다.
출처
https://arxiv.org/abs/2304.12244
WizardLM: Empowering Large Language Models to Follow Complex Instructions
Training large language models (LLMs) with open-domain instruction following data brings colossal success. However, manually creating such instruction data is very time-consuming and labor-intensive. Moreover, humans may struggle to produce high-complexity
arxiv.org