
현재 딥러닝 분야에서는 데이터의 부족에 시달리고 있다. 왜냐하면 모델의 성능을 향상시키기 위해서는 더 많은 데이터가 필수적인데 이를 위해 필요한 데이터의 양은 한정적이기 때문이다. 따라서 이를 해결하기 위해 발명된 기술이 Data Augmentation이다. Data Augmentation에 대해 간략하게 설명하면 기존에 존재하는 데이터에 약간의 변형 또는 손상을 가해서 새로운 데이터를 만드는 방법이다. 이 방법은 주로 Computer VIsion 분야에서 사용되는데 NLP에도 Data Augmentation 기법이 존재한다는 사실을 알게 되고 한 번 공부해보면서 포스트를 작성하였다. 이 포스트는 다음의 블로그들을 참고하여 작성되었다.
https://neptune.ai/blog/data-augmentation-nlp
Data Augmentation in NLP: Best Practices From a Kaggle Master - neptune.ai
There are many tasks in NLP from text classification to question answering but whatever you do the amount of data you have to train your model impacts the model performance heavily. What can you do to make your dataset larger? Simple option -> Get more dat
neptune.ai
A Visual Survey of Data Augmentation in NLP
An extensive overview of text data augmentation techniques for Natural Language Processing
amitness.com
What is the difference of augmentation between vision and NLP?
vision의 augmentation과 NLP의 augmentation에는 차이점이 분명히 존재한다. 예를 들어 생각해보자. vision에서 고양이 사진이 주어졌다고 하였을 때, 비전에서 가장 흔하게 사용되는 방법인 grayscale이나 회전 등을 적용한다고 해보자. 그러면 이와 비슷하게 NLP에서도 문장내 단어의 순서를 셔플하면 augmentation 하기 이전의 문장과 똑같은 의미를 갖는 문장이 나올까? 다음의 그림을 보면 그렇지 않음을 확연하게 알 수 있다.
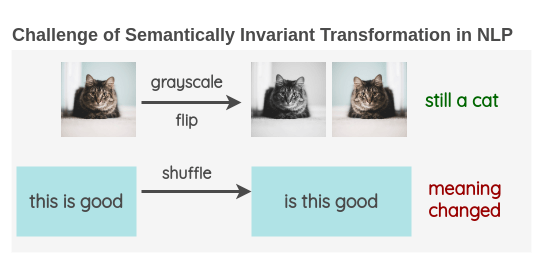
한 마디로 비전에서는 데이터가 주어지면 data generator를 사용해서 신경망 네트워크에 들어가는 데이터 배치를 랜덤하게 변형$($augmentation$)$하면 되므로 학습 전에 따로 준비해야할 사항은 없다.
하지만 NLP에서는 그렇지 않다. 문장의 문법적인 구조 때문에 매우 세밀하게 data augmentation을 진행해야 한다. 앞으로의 내용들은 모두 학습 이전에 사용해야 하는 method들이다. 이제부터 NLP의 data augmentation method에 대해 알아보도록 하자!! 🔥
NLP Data Augmentation Methods
1. Lexical Substitution
Lexical Substitution은 텍스트에 나타나 있는 단어를 문장의 의미를 해치지 않는 선에서 대체하는 방식이다.
a. Thesaurus-based substitution
이 method 에서는 문장 내에서 랜덤한 단어를 고르고 Thesaurus를 사용하여 동의어로 대체하였다. 예를 들어, 영어에 대한 WordNet 데이터베이스를 사용해서 동의어를 찾고 대체를 수행한다. 이 데이터베이스는 단어들 간의 연관성을 수동으로 정리해놓은 데이터베이스이다.
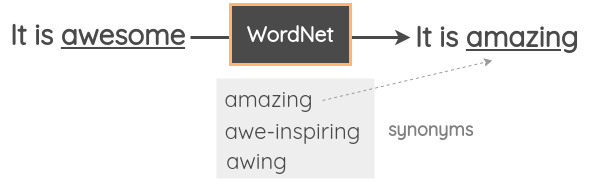
b. Word-Embeddings Substitution
이 방식에서는 Word2Vec, GloVe 같은 pre-trained 워드 임베딩을 가지고 문장 내의 몇몇 단어에 대한 대체를 위해 임베딩 공간에서 근접해 있는 단어들을 사용하였다.

예를 들어, 가장 비슷한 3개의 단어를 사용해서 총 3개의 변형된 텍스트를 생성할 수 있다.
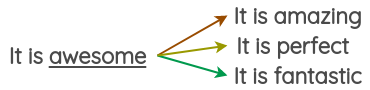
c. Masked Language Model
BERT, RoBERTa, ALBERT 같은 Transformer model들은 pretext task인 "Masked Language Modeling"을 사용하여 방대한 야의 데이터에서 학습되었다. 이 MLM은 문맥에 기반하여 masked word를 예측해야 하는 task이다.
이는 텍스트를 augment하는 데 사용할 수 있다. 예를 들어, pre-trained BERT model을 사용할 때, 텍스트의 몇몇 부분을 mask해두고 BERT model에게 masked token을 예측하도록 물어볼 수 있다.
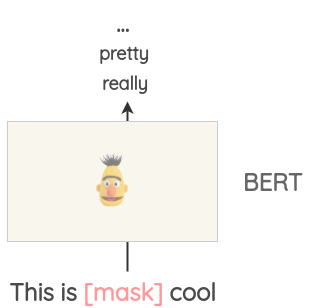
따라서, maske prediction을 통해 다양한 텍스트를 생성할 수 있다. 이전의 방식들과 비교할 때 생성된 텍스트는 모델이 예측할 때 컨텍스트를 고려하므로 문법적으로 더 일관성이 있다.
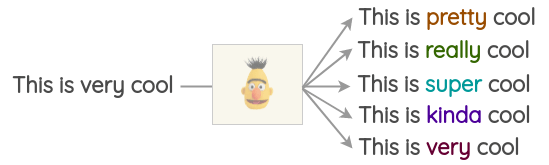
d. TF-IDF based word replacement
이 augmentation method의 기본적인 아이디어는 낮은 TF-IDF 점수를 가지는 단어들은 정보가 없고 따라서, 문장의 ground-truth 라벨에 영향을 받지 않고 대체될 수 있다.
기존 단어에서 대체되는 단어는 전체 문서에서 단어의 TF-IDF 점수를 계산함으로써 선택되고 가장 낮은 점수를 가지는 단어를 선택한다.
2. Back Translation
이 method에서는 텍스트 데이터를 어떤 언어로 번역하고 다시 원래의 언어로 번역한다. 이러한 방식은 문장의 의미는 보존하는 대신 단어들의 구성이 달라진다.
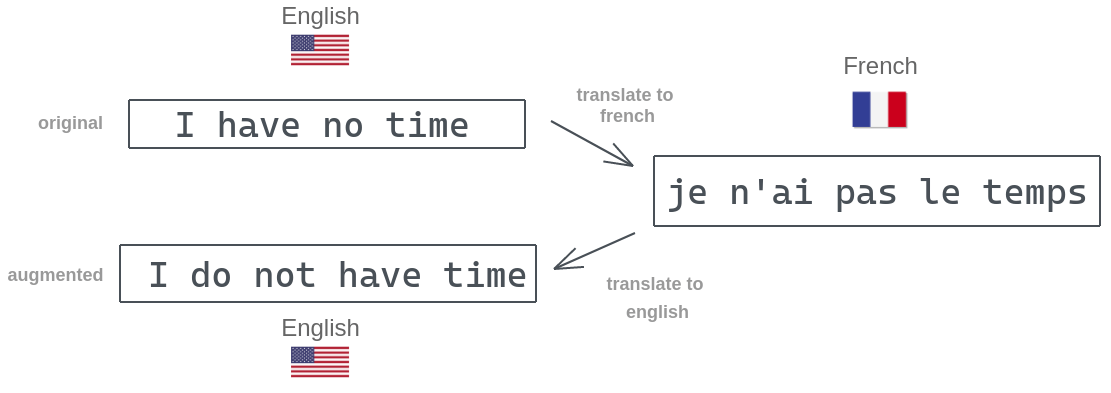
예시를 살펴보면 실제로 문장의 형태는 바뀌긴 했지만 문장의 의미는 바뀌지 않았음을 알 수 있다.
3. Text Surface Transformation
이 method는 정규식을 사용하여 적용되는 간단한 패턴 일치 변환이다. Text Surface Transformation 논문에서는 축약에서 확장으로 또는 그 반대로 언어 형식을 변환하는 예를 제공한다. 이를 적용하여 augmented text를 생성할 수 있다.

축약형과 일반형의 변환은 문장의 의미를 바꾸지 않기 때문에, 다음과 같이 모호한 상황에서는 제대로 작동하지 않는 모습을 보여주기도 한다.
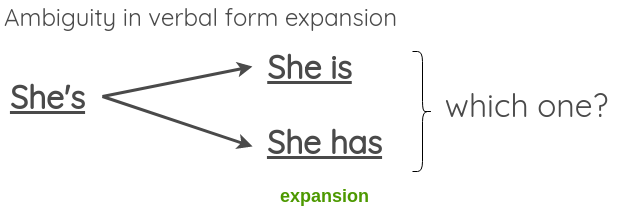
이를 해결하기 위해 논문에서는 모호한 축약은 허락하지만 모호한 확장은 건너뛰었다.

4. Easy Data Auhmentation$($EDA$)$
Easy Data Augmentation은 통상적으로 사용되고 가장 간단한 data augmentation 방법 중 하나이다. EDA는 4개의 간단하지만 매우 좋은 모습을 보여주는 연산으로 구성되어 있다. 이 방법들은 overfitting을 방지해주고 robust model을 학습시키는데 도움을 준다. EDA는 하나의 논문이 있는데 궁금하다면 논문을 읽어보는 것도 추천한다.
a. Synonym Replacement
이 method는 앞서 설명한 Thesaurus-based substitution와 유사한 내용으로 문장 내에서 랜덤한 단어를 동의어로 변형하는 것이다. 한 마디로 paraphrase를 한다는 의미이다.
b. Random Insertion
문장 내에서 불용어가 아닌 랜덤한 단어의 랜덤한 동의어를 찾는다. 이 동의어를 문장 내에서 랜덤한 위치에 삽입한다. 이 과정을 $n$번 반복한다.

c. Random Swap
문장 내에서 랜덤한 두 단어의 위치를 바꾸는 것이다.

d. Random Deletion
문장에서 각 단어를 확률 $p$를 사용하여 랜덤하게 제거한다.

5. Instance Crossover Augmentation
이 method는 유전학에서 발생하는 염색체 교차에서 영감을 받았다. 여기서는 tweet이 반으로 나눠지고 똑같은 양극$($positive/negative$)$의 두 개의 랜덤한 tweet들끼리는 서로의 절반이 바뀌어진다. 가설은 결과가 비문법적이고 의미론적으로 부적절하더라도 새 텍스트가 여전히 sentiment를 보존한다는 것이다.
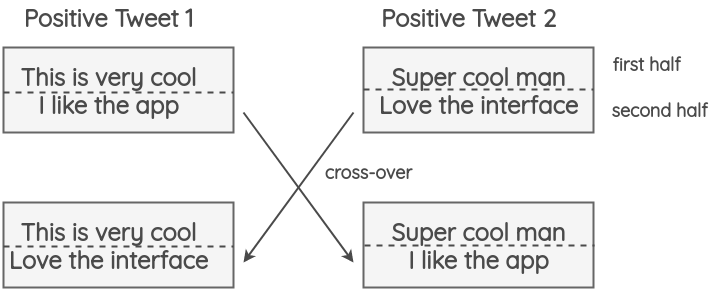
이 method는 정확도 측면에서 별 효과가 없지만 F1-score에는 도움이 되는 모습을 보여줬다.
6. NLP Albumentation
이 포스트의 앞부분에서 computer vision data augmentation과 NLP data augmentation의 차이에 대해서 얘기하였다. 하지만 이 섹션에서는 CV data augmentation에서 사용되는 방법들을 어떻게 NLP에 적용할 수 있을 지에 대해서 알아볼 것이다. 그러기 위해 Albumentation 패키지를 사용할텐데, 여기에는 어떠한 기술들이 있는지 알아보도록 하자.
a. Shuffle Sentences Transform
이 변형에서는 여러 개의 문장을 포함하는 텍스트 샘플이 주어지면 이 문장들은 셔플되서 새로운 샘플을 만들어낸다. 예를 들어 text = '<Sentence1>. <Sentence2>. <Sentence3>. <Sentence4>. <Sentence5>. <Sentence5>'가 주어지면 text = '<Sentence2>. <Sentence3>. <Sentence1>. <Sentence5>. <Sentence5>. <Sentence4>.'로 변형되는 것이다.
b. Exclude Duplicate Transform
이 변형에서는 복제가 되어 있는 문장을 포함한 여러 문장을 포함한 텍스트 샘플이 주어지면, 이 복제 문장들은 새로운 샘플을 만들기 위해 삭제된다. 예를 들어 text = ‘<Sentence1>. <Sentence2>. <Sentence4>. <Sentence4>. <Sentence5>. <Sentence5>.’ 가 주어지면 ‘<Sentence1>. <Sentence2>.<Sentence4>. <Sentence5>.’ 로 변형되는 것이다.
이 외에도 Albumentation 패키지에는 많은 변형들이 존재하지만, 본 포스트에서는 이 정도만 다뤄보도록 하겠다.
7. NLP Mixup
Mixup은 간단하지막 효과적인 image augmentation 방법이다. Mixup의 아이디어는 학습을 위한 합성 예제를 생성하기 위해 일정 비율로 미니 배치에서 두 개의 무작위 이미지를 결합하는 것이다. 이미지에 대해 이것은 두 개의 서로 다른 클래스의 이미지 픽셀을 합친다는 의미이다. Mixup은 학습 중에 정규화의 형태로 작동한다.

Mixup의 아이이더를 NLP로 끌고 와서 텍스트에서 작동할 수 있도록 하였다. 이 방법은 Mixup을 텍스트에 적용한 두 가지 새로운 방법을 제안하였다.
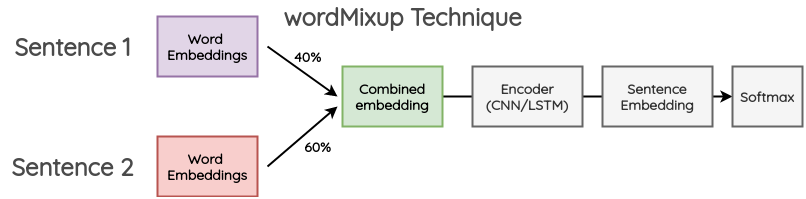
a. wordMixup
이 방법에서는 미니 배치에서 두 개의 랜덤한 문장들이 들어오고 똑같은 길이로 zero-padding 된다. 그 다음에 이들의 word embedding은 보통의 text classification에 대한 흐름으로 지나간다. cross-entropy loss은 주어진 비율에서 기존 텍스트의 두 라벨 모두에 대해 계산된다.
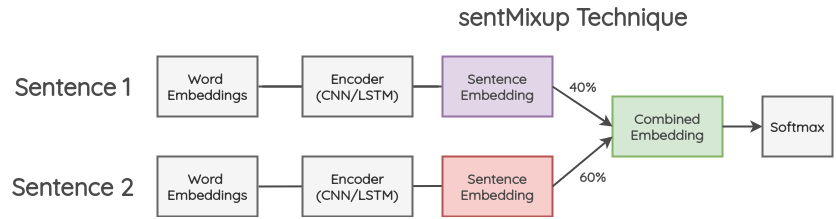
b. sentMixup
이 방법에서는 두 개의 문장이 들어오고 똑같은 길이로 zero-padding 된다. 그 다음에 이들의 word embedding은 LSTM/CNN encoder을 통과하고 마지막 hidden state를 sentence embedding으로 받아들인다. 이러한 embedding들은 특정 비율로 합쳐지고 마지막 분류 레이어로 흘러간다. cross-entropy loss는 주어진 비율에서 기존 문장의 두 라벨에 기반해서 계산된다.
Conclusion
이렇게 해서 NLP의 data augmentation method들에 대해서 알아봤는데 생각보다 computer vision만큼이나 다양해서 놀랐다. 😲 data augmentation은 매우 중요한 분야이기 때문에 NLP 외에 Computer vision을 공부할 때도 필요하므로 한 번 즈음 공부해보기를 추천한다. 👍
출처
A Visual Survey of Data Augmentation in NLP
An extensive overview of text data augmentation techniques for Natural Language Processing
amitness.com
https://neptune.ai/blog/data-augmentation-nlp
Data Augmentation in NLP: Best Practices From a Kaggle Master - neptune.ai
There are many tasks in NLP from text classification to question answering but whatever you do the amount of data you have to train your model impacts the model performance heavily. What can you do to make your dataset larger? Simple option -> Get more dat
neptune.ai
'Paper Reading 📜 > Natural Language Processing' 카테고리의 다른 글
현재 딥러닝 분야에서는 데이터의 부족에 시달리고 있다. 왜냐하면 모델의 성능을 향상시키기 위해서는 더 많은 데이터가 필수적인데 이를 위해 필요한 데이터의 양은 한정적이기 때문이다. 따라서 이를 해결하기 위해 발명된 기술이 Data Augmentation이다. Data Augmentation에 대해 간략하게 설명하면 기존에 존재하는 데이터에 약간의 변형 또는 손상을 가해서 새로운 데이터를 만드는 방법이다. 이 방법은 주로 Computer VIsion 분야에서 사용되는데 NLP에도 Data Augmentation 기법이 존재한다는 사실을 알게 되고 한 번 공부해보면서 포스트를 작성하였다. 이 포스트는 다음의 블로그들을 참고하여 작성되었다.
https://neptune.ai/blog/data-augmentation-nlp
Data Augmentation in NLP: Best Practices From a Kaggle Master - neptune.ai
There are many tasks in NLP from text classification to question answering but whatever you do the amount of data you have to train your model impacts the model performance heavily. What can you do to make your dataset larger? Simple option -> Get more dat
neptune.ai
A Visual Survey of Data Augmentation in NLP
An extensive overview of text data augmentation techniques for Natural Language Processing
amitness.com
What is the difference of augmentation between vision and NLP?
vision의 augmentation과 NLP의 augmentation에는 차이점이 분명히 존재한다. 예를 들어 생각해보자. vision에서 고양이 사진이 주어졌다고 하였을 때, 비전에서 가장 흔하게 사용되는 방법인 grayscale이나 회전 등을 적용한다고 해보자. 그러면 이와 비슷하게 NLP에서도 문장내 단어의 순서를 셔플하면 augmentation 하기 이전의 문장과 똑같은 의미를 갖는 문장이 나올까? 다음의 그림을 보면 그렇지 않음을 확연하게 알 수 있다.
한 마디로 비전에서는 데이터가 주어지면 data generator를 사용해서 신경망 네트워크에 들어가는 데이터 배치를 랜덤하게 변형$($augmentation$)$하면 되므로 학습 전에 따로 준비해야할 사항은 없다.
하지만 NLP에서는 그렇지 않다. 문장의 문법적인 구조 때문에 매우 세밀하게 data augmentation을 진행해야 한다. 앞으로의 내용들은 모두 학습 이전에 사용해야 하는 method들이다. 이제부터 NLP의 data augmentation method에 대해 알아보도록 하자!! 🔥
NLP Data Augmentation Methods
1. Lexical Substitution
Lexical Substitution은 텍스트에 나타나 있는 단어를 문장의 의미를 해치지 않는 선에서 대체하는 방식이다.
a. Thesaurus-based substitution
이 method 에서는 문장 내에서 랜덤한 단어를 고르고 Thesaurus를 사용하여 동의어로 대체하였다. 예를 들어, 영어에 대한 WordNet 데이터베이스를 사용해서 동의어를 찾고 대체를 수행한다. 이 데이터베이스는 단어들 간의 연관성을 수동으로 정리해놓은 데이터베이스이다.
b. Word-Embeddings Substitution
이 방식에서는 Word2Vec, GloVe 같은 pre-trained 워드 임베딩을 가지고 문장 내의 몇몇 단어에 대한 대체를 위해 임베딩 공간에서 근접해 있는 단어들을 사용하였다.
예를 들어, 가장 비슷한 3개의 단어를 사용해서 총 3개의 변형된 텍스트를 생성할 수 있다.
c. Masked Language Model
BERT, RoBERTa, ALBERT 같은 Transformer model들은 pretext task인 "Masked Language Modeling"을 사용하여 방대한 야의 데이터에서 학습되었다. 이 MLM은 문맥에 기반하여 masked word를 예측해야 하는 task이다.
이는 텍스트를 augment하는 데 사용할 수 있다. 예를 들어, pre-trained BERT model을 사용할 때, 텍스트의 몇몇 부분을 mask해두고 BERT model에게 masked token을 예측하도록 물어볼 수 있다.
따라서, maske prediction을 통해 다양한 텍스트를 생성할 수 있다. 이전의 방식들과 비교할 때 생성된 텍스트는 모델이 예측할 때 컨텍스트를 고려하므로 문법적으로 더 일관성이 있다.
d. TF-IDF based word replacement
이 augmentation method의 기본적인 아이디어는 낮은 TF-IDF 점수를 가지는 단어들은 정보가 없고 따라서, 문장의 ground-truth 라벨에 영향을 받지 않고 대체될 수 있다.
기존 단어에서 대체되는 단어는 전체 문서에서 단어의 TF-IDF 점수를 계산함으로써 선택되고 가장 낮은 점수를 가지는 단어를 선택한다.
2. Back Translation
이 method에서는 텍스트 데이터를 어떤 언어로 번역하고 다시 원래의 언어로 번역한다. 이러한 방식은 문장의 의미는 보존하는 대신 단어들의 구성이 달라진다.
예시를 살펴보면 실제로 문장의 형태는 바뀌긴 했지만 문장의 의미는 바뀌지 않았음을 알 수 있다.
3. Text Surface Transformation
이 method는 정규식을 사용하여 적용되는 간단한 패턴 일치 변환이다. Text Surface Transformation 논문에서는 축약에서 확장으로 또는 그 반대로 언어 형식을 변환하는 예를 제공한다. 이를 적용하여 augmented text를 생성할 수 있다.
축약형과 일반형의 변환은 문장의 의미를 바꾸지 않기 때문에, 다음과 같이 모호한 상황에서는 제대로 작동하지 않는 모습을 보여주기도 한다.
이를 해결하기 위해 논문에서는 모호한 축약은 허락하지만 모호한 확장은 건너뛰었다.
4. Easy Data Auhmentation$($EDA$)$
Easy Data Augmentation은 통상적으로 사용되고 가장 간단한 data augmentation 방법 중 하나이다. EDA는 4개의 간단하지만 매우 좋은 모습을 보여주는 연산으로 구성되어 있다. 이 방법들은 overfitting을 방지해주고 robust model을 학습시키는데 도움을 준다. EDA는 하나의 논문이 있는데 궁금하다면 논문을 읽어보는 것도 추천한다.
a. Synonym Replacement
이 method는 앞서 설명한 Thesaurus-based substitution와 유사한 내용으로 문장 내에서 랜덤한 단어를 동의어로 변형하는 것이다. 한 마디로 paraphrase를 한다는 의미이다.
b. Random Insertion
문장 내에서 불용어가 아닌 랜덤한 단어의 랜덤한 동의어를 찾는다. 이 동의어를 문장 내에서 랜덤한 위치에 삽입한다. 이 과정을 $n$번 반복한다.
c. Random Swap
문장 내에서 랜덤한 두 단어의 위치를 바꾸는 것이다.
d. Random Deletion
문장에서 각 단어를 확률 $p$를 사용하여 랜덤하게 제거한다.
5. Instance Crossover Augmentation
이 method는 유전학에서 발생하는 염색체 교차에서 영감을 받았다. 여기서는 tweet이 반으로 나눠지고 똑같은 양극$($positive/negative$)$의 두 개의 랜덤한 tweet들끼리는 서로의 절반이 바뀌어진다. 가설은 결과가 비문법적이고 의미론적으로 부적절하더라도 새 텍스트가 여전히 sentiment를 보존한다는 것이다.
이 method는 정확도 측면에서 별 효과가 없지만 F1-score에는 도움이 되는 모습을 보여줬다.
6. NLP Albumentation
이 포스트의 앞부분에서 computer vision data augmentation과 NLP data augmentation의 차이에 대해서 얘기하였다. 하지만 이 섹션에서는 CV data augmentation에서 사용되는 방법들을 어떻게 NLP에 적용할 수 있을 지에 대해서 알아볼 것이다. 그러기 위해 Albumentation 패키지를 사용할텐데, 여기에는 어떠한 기술들이 있는지 알아보도록 하자.
a. Shuffle Sentences Transform
이 변형에서는 여러 개의 문장을 포함하는 텍스트 샘플이 주어지면 이 문장들은 셔플되서 새로운 샘플을 만들어낸다. 예를 들어 text = '<Sentence1>. <Sentence2>. <Sentence3>. <Sentence4>. <Sentence5>. <Sentence5>'가 주어지면 text = '<Sentence2>. <Sentence3>. <Sentence1>. <Sentence5>. <Sentence5>. <Sentence4>.'로 변형되는 것이다.
b. Exclude Duplicate Transform
이 변형에서는 복제가 되어 있는 문장을 포함한 여러 문장을 포함한 텍스트 샘플이 주어지면, 이 복제 문장들은 새로운 샘플을 만들기 위해 삭제된다. 예를 들어 text = ‘<Sentence1>. <Sentence2>. <Sentence4>. <Sentence4>. <Sentence5>. <Sentence5>.’ 가 주어지면 ‘<Sentence1>. <Sentence2>.<Sentence4>. <Sentence5>.’ 로 변형되는 것이다.
이 외에도 Albumentation 패키지에는 많은 변형들이 존재하지만, 본 포스트에서는 이 정도만 다뤄보도록 하겠다.
7. NLP Mixup
Mixup은 간단하지막 효과적인 image augmentation 방법이다. Mixup의 아이디어는 학습을 위한 합성 예제를 생성하기 위해 일정 비율로 미니 배치에서 두 개의 무작위 이미지를 결합하는 것이다. 이미지에 대해 이것은 두 개의 서로 다른 클래스의 이미지 픽셀을 합친다는 의미이다. Mixup은 학습 중에 정규화의 형태로 작동한다.
Mixup의 아이이더를 NLP로 끌고 와서 텍스트에서 작동할 수 있도록 하였다. 이 방법은 Mixup을 텍스트에 적용한 두 가지 새로운 방법을 제안하였다.
a. wordMixup
이 방법에서는 미니 배치에서 두 개의 랜덤한 문장들이 들어오고 똑같은 길이로 zero-padding 된다. 그 다음에 이들의 word embedding은 보통의 text classification에 대한 흐름으로 지나간다. cross-entropy loss은 주어진 비율에서 기존 텍스트의 두 라벨 모두에 대해 계산된다.
b. sentMixup
이 방법에서는 두 개의 문장이 들어오고 똑같은 길이로 zero-padding 된다. 그 다음에 이들의 word embedding은 LSTM/CNN encoder을 통과하고 마지막 hidden state를 sentence embedding으로 받아들인다. 이러한 embedding들은 특정 비율로 합쳐지고 마지막 분류 레이어로 흘러간다. cross-entropy loss는 주어진 비율에서 기존 문장의 두 라벨에 기반해서 계산된다.
Conclusion
이렇게 해서 NLP의 data augmentation method들에 대해서 알아봤는데 생각보다 computer vision만큼이나 다양해서 놀랐다. 😲 data augmentation은 매우 중요한 분야이기 때문에 NLP 외에 Computer vision을 공부할 때도 필요하므로 한 번 즈음 공부해보기를 추천한다. 👍
출처
A Visual Survey of Data Augmentation in NLP
An extensive overview of text data augmentation techniques for Natural Language Processing
amitness.com
https://neptune.ai/blog/data-augmentation-nlp
Data Augmentation in NLP: Best Practices From a Kaggle Master - neptune.ai
There are many tasks in NLP from text classification to question answering but whatever you do the amount of data you have to train your model impacts the model performance heavily. What can you do to make your dataset larger? Simple option -> Get more dat
neptune.ai