
요즘에 매우 화제가 되고 있는 주제가 하나 있다. 아마도 많은 분들이 해보셨을거라 믿는데, 바로 'ChatGPT'이다. 필자도 처음에 공개됐을 때 호기심을 갖고, 몇 가지 질문들을 던지거나 시시콜콜한 이야기들을 했던 경험이 있다. 처음에는 그저 감탄 밖에 나오지 않았다. 정말이지 너무나도 놀라운 정확도와 전혀 기계라고 생각되지 않는 대화의 매끄러움 때문이었다. 물론, 아직 부족한 점들도 많았던 것은 사실이지만, 그런 점을 포함하고라도 정말이지 엄청난 발전이라고 말할 수 있었다. 처음에는 그저 감탄만 했을 뿐인데, 시간이 지나면서 과연 이 ChatGPT는 어떻게 만들어진 걸까? 라는 의구심을 품게 되었다. 그래서 OpenAI에서 ChatGPT에 대해 설명을 적어놓은 글을 발견하고, 이 글을 자세히 읽어보았다. $($글 링크$)$ 결국에 ChatGPT도 또다른 LM인 InstructGPT를 사용하여 제작되었다는 것을 알게 되었고, 이 InstructGPT의 논문을 읽어보고 싶다는 생각이 들어서, 지금 이렇게 포스트를 작성해보려고 한다.
InstructGPT에 사용된 개념 중 하나인 Reinforcement Learning with Human Feedback$($RLHF$)$은 매우 중요한 개념으로, 이 개념을 자세히 알면 논문을 읽는데 도움이 된다.
사람의 피드백을 통한 강화학습 - Reinforcement Learning from Human Feedback $($RLHF$)$
Language Model$($LM$)$은 지난 몇 년 동안 사람의 입력을 통해 다양하고 그럴 듯한 text를 생성해내면서 강렬한 인상을 남겼다. 하지만, 어떤 점이 이렇게 좋은 text를 출력할 수 있게 하는지는 자세히
cartinoe5930.tistory.com
The overview of this paper
LM의 크기를 증가시키는 방법을 통해 지난 몇 년간 놀라운 성능 상승 효과를 볼 수 있었다. 하지만, 무작정 LM의 크기를 증가시키는 것은 성능을 향상시키는데 도움이 될 수 있을지 몰라도, 모델의 출력의 퀄리티는 그렇지 않을 수 있다. 왜냐하면, 진실성이 없고 유해한, 한 마디로 도움이 되지 않는 정보를 생성해내기 때문이다. 다른 말로 하면, 이 LM은 사용자들에 알맞게 조정되지 않은 모델이라고 할 수 있는 것이다.
그래서 이 논문에서는 유저의 의도에 알맞게 여러가지 분야의 task를 수행할 수 있도록 사람의 피드백에 따라 LM을 fine-tuning함으로써 aligning한 LM을 제안하였다. 이를 위해, 사람 라벨러가 작성한 prompt와 OpenAI API의 prompt를 이용하여 GPT-3를 fine-tuning 하였다. 사람 라벨러가 작성한 prompt는 모델의 의도에 알맞게 사람이 작성한 설명을 의미한다. 그 다음에, 사람들의 피드백을 통해 모델의 출력들의 랭킹 데이터를 수집해서 RL로 다시 fine-tuning한다. 이런 방식으로 만들어진 모델이 바로 InstructGPT이다.
이 1.3B InstructGPT는 175B GPT-3보다 약 100배 가량 더 적은 수의 파라미터를 가지고도 더 나은 성능을 보여줬다. 게다가, InstructGPT의 진실성은 GPT-3보다 우수했고, 유해한 출력은 GPT-3보다 적었다. 이렇게 놀라운 성능을 보여줬음에도 불구하고, InstructGPT는 공인된 NLP dataset에서도 성능 차이가 별로 나지 않았다. 그래도 아직 잔실수를 보여주긴 하지만, human feedback을 통해 fine-tuning하는 것은 model을 aligning하는 유망한 방법이라고 할 수 있다.
Table of Contents
1. Instroduction
2. Related Work
3. Methods & Experimental details
3-1. High-level methodology
3-2. Dataset
3-3. Tasks
3-4. Models
3-5. Evaluation
4. Results
4-1. Results on the API distribution
4-2. Results on public NLP datasets
4-3. Qualitative results
5. Discussion
5-1. Implication for alignment research
5-2. Limitations
1. Introduction
LM은 task에 대한 몇 가지 예시를 입력으로 받아, 광범위한 분야의 NLP task를 수행한다. 하지만, 이러한 LM은 종종 의도되지 않은 방향으로 나아가기도 하는데, 예를 들어 없는 사실을 만들거나, 편향적이고 유해한 텍스트를 만들거나, 사용자의 의도대로 사용되지 않는 등의 모습을 보여주기도 한다. 이는 왜냐하면, 보통의 LM을 학습시킬 때 자주 사용되는 NSP$($Next Sentence Prediction$)$은 misaligning한 목표이기 때문이다. 여기서 misaligning 하다는 표현은 사용자의 의도에 알맞게 조정되지 않았다는 의미이다. 다시 본론으로 들어와서, 이러한 학습 방법은 '사용자의 의도에 알맞게 유익하고 안전한 모델'이라는 의도에 알맞지 않는 학습 방법이다.
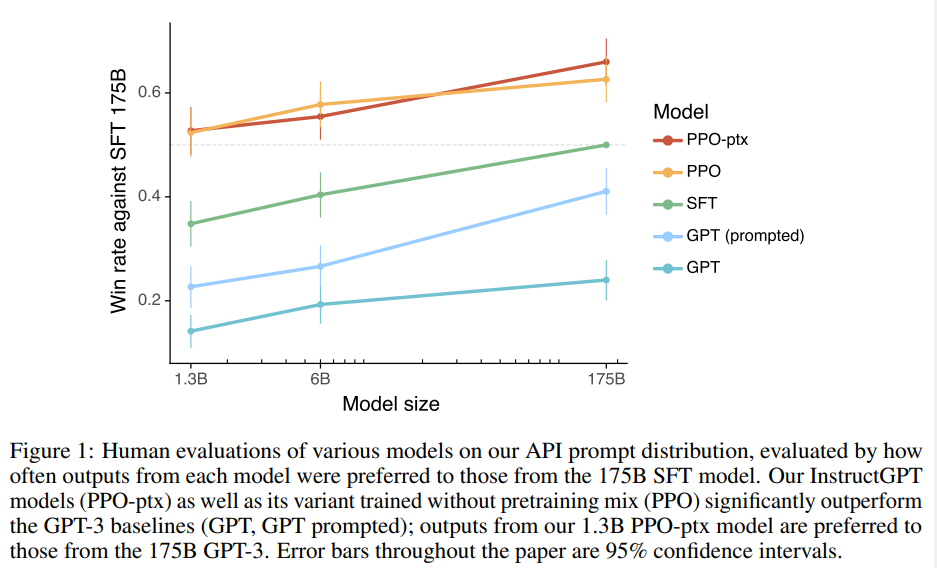
그래서 사용자의 의도에 알맞게 LM을 학습시키려 하였다. 이 과정에서 모델에게 explicit$($분명한$)$하게 학습시킨 것은 사용자의 instruction을 따르게 하는 것이고, implicit$($암시적$)$하게 학습시킨 것은 모델이 truthful, not biased & toxic한 text를 생성하게 하는 것이었다. 요약해서 말하면, 유익하고$($helpful$)$, 솔직하고$($honest$)$, 무해한$($harmless$)$한 모델을 만들고자 하였다.
논문에서는 aligning LM을 만들기 위해 fine-tuning 방식에 대해 집중하였다. 자세하게 말하면, Reinforcement Learning from Human Feedback$($RLHF$)$를 사용하여 GPT-3를 광범위한 instruction의 클래스를 따라 fine-tuning하였다. 이 방식을 사용하기 위해서는 사람의 preference$($선호도, 피드백 같은 개념으로 생각하면 될 것 같다$)$를 reward signal로 이용하여 model을 fine-tuning 해야 한다. 이 과정을 나타내면 다음과 같다.
- 이를 위해, 40명의 labeler를 테스트를 통해 뽑음. 그 다음으로 OpenAI API의 human-written demonstration과 labeler-written prompt를 활용하여 supervised learning baseline을 학습시킴.
- 이렇게 학습된 모델이 출력한 출력값과, labeler가 라벨링한 라벨과 비교하여 API prompt를 만듦. 그런 다음 이 데이터셋에서 reward model$($RM$)$을 훈련하여 라벨러가 선호하는 모델 출력을 예측.
- 이 RM을 reward function으로 활용하여 supervised learning baseline을 fine-tuning해서 PPO 알고리즘을 사용해 이 보상을 최대화할 수 있게 만듦.
이 과정이 그림 2에 나타나 있다. 이러한 과정은 GPT-3가 좀 더 aligning되서 소수의 사람들에게만 선호 받는 대답이 아닌, 좀 더 모두가 선호하는 대답을 내놓을 수 있게 해주었다. 이를 통해 나온 모델이 바로 'InstructGPT'인 것이다!

모델을 제작한 후, 여러 가지 평가를 진행하였는데, 그렇게 얻게된 점은 다음과 같다.
- InstructGPT의 출력이 GPT-3의 출력보다 선호받음 ✨
- InstructGPT의 truthfulness가 GPT-3보다 조금 더 상승한 모습을 보여줌 ✨
- InstructGPT가 GPT-3에 비해 toxiciry에서 미약하지만 향상된 모습을 보여줌
- RLHF를 이용하여 alignment tax 때문에, public NLP dataset에 대해 성능이 저하되는 모습이 있었지만, fine-tuning procedure을 수정하여 최소화함 ✨
- 학습에 사용된 instruction을 만든 labeler에 한해서만 선호도를 보인 것이 아니라, 학습 instruction 제작에 관여되지 않은 labeler도 모델의 출력에 선호도를 보임 -> 일반화가 잘 되었음 ✨
- InstructGPT는 RLHF fine-tuning 분포 외의 명령에 대해서도 일반화가 잘 된 모습을 보여줌 ✨
- InstructGPT는 그럼에도 아직 잔실수가 있음,, 😅
2. Related Work
InstructGPT 논문과 관련된 연구 내용들은 다음과 같다. 원래는 Related Work를 살펴보지 않지만, InstructGPT 논문의 Related Work를 보면 논문의 전체적인 흐름을 잡을 수 있어서 간단하게 짚고 넘어가보도록 하겠다.
- Human Feedback을 이용하여 alignment & learning 🫡: 서론에서 봐서 알 수 있듯이, InstructGPT는 사람의 feedback을 받아서 학습 및 fine-tuning을 한다.
- Instruction을 따라 LM 학습시키기 🏫: 사람 labeler가 instruction을 제작해서 이 instruction을 이용하여 LM을 학습시킨다.
- LM의 위험도 측정 📐: InstructGPT의 목표는 사람한테 더욱 aligning한 모델을 만드는 것이었다. 따라서 사람에게 잘못되거나, 편향적인 정보를 주는지 측정할 수 있어야 한다.
- LM의 behavior$($행동, 태도$)$를 조정하여 위험도 완화시키기 ⚠️🔻: InstructGPT의 목표였던 harmless한 LM을 위해 LM의 behavior을 조정하여 위험도를 완하시켜야 한다.
3. Methods & Experimental details
3-1. High-level methodology
논문에서 사용된 방법은 이전의 RLHF 방식들을 따라서 진행되었다. 우선 pre-trained LM, 모델이 aligning한 출력을 생성하기를 원하는 prompt 분포, 그리고 훈련된 human labeler 팀으로 시작하였다. 그 다음에 그림 2에서 설명한 것처럼 3 단계를 적용하였다.
- demonstration data 수집 & supervised policy 학습: labeler는 input prompt에서 원하는 behavior의 demonstration을 제공하였다. 그 다음에, 이를 이용해서 GPT-3를 fine-tune.
- 비교 데이터 수집 & RM 학습: 모델 출력들 간에 비교를 한 데이터셋을 수집한다. 이때, labeler는 주어진 입력에 대해 어떤 출력값이 나은지 선호를 함으로써 비교를 진행한다. 그 다음에, RM을 human-preffered 출력을 예측하도록 학습시킨다.
- PPO를 사용하여 RM에 대해 policy를 최적화: RM의 출력을 scalar reward로 사용하고 이 reward를 PPO를 사용하여 최적화시킨다.
2 단계와 3 단계는 계속적으로 반복된다. 현재 best policy에 비교 데이터가 충분히 수집될 때까지 말이다. 실제로 대부분의 비교 데이터는 supervised policy에서 가져오며 일부는 PPO 정책에서 가져온다.
3-2. Dataset
Dataset은 실제 논문에서 보면, 막 사람들을 어떻게 뽑았고, 뭐 어떤 기준으로 데이터를 수집했고 등과 같이 매우 복잡하고 이해하기 어렵게 설명해뒀지만, 실상 가장 중요한 것은 fine-tuning에 어떤 데이터셋들이 사용되었는가 이다. 따라서 가장 중요한 이 부분을 살펴보도록 하자.
최초의 InstructGPT를 학습시키기 위해, labeler한테 스스로 prompt를 작성시키게 하였다. 왜냐하면, 프로세스를 bootstrap하기 위해 instruction-like prompt의 초기 소스가 필요했기 때문이다. 그리고 중요한 것은 이러한 prompt가 GPT-3에는 들어가지 않았다는 것이다. labeler는 다음 3가지 형식의 prompt를 작성하였다.
- Plain: labeler에게 task의 다양성을 충분히 보장하면서, 임의의 task를 제안하도록 요청
- Few-shot: labeler에게 instruction과 그 instruction에 대한 여러 query/response 쌍을 제시하도록 요청
- User-based: OpenAI API에 대한 대기자 명단 애플리케이션에 명시된 여러 사용 사례가 있다. labeler에게 이러한 사용 사례에 해당하는 prompt를 제시하도록 요청.
이러한 prompt로부터 fine-tuning procedure에 사용되는 세 개의 서로 다른 데이터셋을 생성하였다.
- SFT dataset: labeler demonstration을 사용해 SFT model 학습
- RM dataset: 모델 출력에 대한 랭킹을 사용하여 RM 학습
- PPO dataset: 아무런 human label 없이, RLHF fine-tuning에 입력으로 사용
이렇게 생성된 dataset은 다양한 분포를 이루는데 이는 다음의 표 1과 같다.
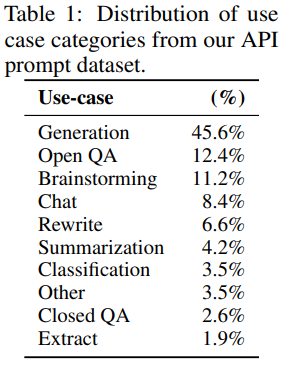
3-3. Tasks
논문에서 사용된 학습 task는 다음의 두 가지 소스로부터 나왔다. 1. labeler에 의해 작성된 prompt dataset 2. API의 초기 InstructGPT 모델에 제출된 prompt dataset. 이러한 prompt는 매우 다양한데, 생성, QA, 대화, 요약, 추출 외에도 많은 NLP task를 포함하고 있다. 이렇게 만들어진 dataset은 96% 정도가 영어 데이터인데, 나중에 확인할 수 있겠지만, 다른 언어에서도 놀라운 성능을 보여줬다
3-4. Models
드디어 대망의 Model에 대해 알아볼 차례이다. 포스트의 처음에서도 말했듯이 도대체 어떻게 작동하는 건 지 되게 의문을 품고 있었는데, 이제 이 궁금증을 풀어볼 것이다! 우선 InstructGPT도 처음에는 GPT-3로부터 시작하였다. 그리고 이 GPT-3에 다음의 각기 다른 3가지 방법을 적용하여 학습시켰다.
Supervised fine-tuning $($SFT$)$
지도 학습을 이용하여 GPT-3를 labeler demonstration에 대해 fine-tune 하였다. cosine learning rate 감소와 residual dropout 0.2를 사용하여 16 epoch 동안 학습되었다. 그러고 최종 SFT model은 validation set에 대해 RM score를 기준으로 로 선정되었다. SFT model은 1 epoch을 진행한 뒤에 과적합이 있었음에도 불구하고, epoch을 많이 진행할수록 RM score와 human reference rating에 도움이 된다는 것을 알았다.
Reward Modeling $($RM$)$
최종 unembedding layer가 제거된 SFT model에서 시작하여 prompt와 response을 받아들이고 출력으로 scalar reward를 내놓도록 모델을 훈련시켰다. 논문에서는 6B RM만 사용했는데, 이는 계산량을 줄이기 위한 것도 있고, 175B RM 학습은 불안정한 모습과 오히려 더 떨어지는 성능을 보여줬기 때문이다.
기존의 RM과 다른 점은 human labeler가 더 선호하는 응답에 log odd를 추가해서 차이점을 뒀다.
비교 수집 속도를 높이기 위해, 순위에 대한 응답이 $K = 4$에서 $K = 9$ 사이인 labeler만 제시할 수 있도록 하였다. 이렇게 하면 labeler에게 표시되는 각 prompt에 대해 $\begin{pmatrix}
K \\ 2
\end{pmatrix}$ 비교가 생성된다. 비교는 각 labeling task 내에서 매우 상관 관계가 있기 때문에 비교를 하나의 dataset으로 단순히 섞으면 dataset에 대한 single pass로 인해 RM이 과적합됨을 발견하였다. 대신 각 prompt의 모든 $\begin{pmatrix}
K \\ 2
\end{pmatrix}$ 비교를 단일 배치 요소로 학습하였다. 이는 각 completion에 대해 RM의 single forward pass만 필요하고 더 이상 과대적합되지 않기 때문에 훨씬 향상된 validation accuracy 및 log loss를 달성하기 때문에 훨씬 더 계산적으로 효율적이다.
RM의 loss function은 다음과 같다.

마지막으로, RM 손실은 reward의 변화에 불변하기 때문에 labeler demonstration이 RL을 수행하기 전에 평균 점수가 0이 되도록 편향을 사용하여 보상 모델을 정규화한다.
Reinforcement learning $($RL$)$
논문에서는 이러한 환경에서 PPO를 사용하여 SFT model을 fine-tune 하였다. 환경은 임의의 customer prompt를 제시하고 prompt에 대한 응답을 기대하는 bandit 환경이다. prompt와 response가 주어지면, RM에 의해 결정되는 reward를 출력하고 에피소드를 끝낸다. 게다가, 토큰당 KL 페널티를 추가해 RM의 과도한 최적화를 방지하였다. value function은 RM으로부터 시작된다. 이러한 방식을 'PPO'라고 한다.
그리고 논문에서는 public NLP dataset에 대한 성능 저하 문제를 해결하기 위해, PPO 기울기에 pre-training 기울기를 섞는 실험을 진행하였다. 이러한 모델을 'PPO-ptx'라고 부른다. RL 학습에서 다음과 같은 결합된 objective function을 최대화한다.

Baselines
이렇게 만들어진 PPO model을 SFT model과 GPT-3에 대해서도 성능을 비교해보았다.
3-5. Evaluation
모델이 얼마나 align 되었는지 측정하기 위해, context에서 alignment의 의미를 명확히 해야할 필요가 있다. align하다는 의미는 모델이 사용자의 의도대로 행동하는가를 의미하고, 이는 다시 말하면 얼마나 도움이 되고$($helpful$)$, 정직하고$($honest$)$, 덜 유해한지$($harmless$)$한 지를 측정해야 한다.
모델의 정직함$($honest$)$를 측정하는 건 매우 어렵다. 따라서 이에 대한 대안으로 모델의 truthfulness를 측정하기로 했다. 모델의 truthfulness를 측정하는 데에는 두 가지 방법이 사용되었다.
- closed domain task에서 어떻게 정보를 형성하는지 경향 평가
- truthfulQA dataset 사용
정직함과 비슷하게 모델의 해로움$($harm$)$을 측정하는 것은 매우 어려운 일이다. 그래서 labeler가 text가 맥락에 맞는 말인지 평가하는 과정을 통해 측정하거나, RealToxicityPrompts 벤치마크를 이용하였다.
요약하자면, 정량적 평가를 두 개의 파트로 나눌 수 있다.
- API 분포 평가
- public NLP dataset 평가
4. Results
4-1. Results on API distribution
앞서 Evaluation에서 설명했던 것처럼 평가는 API 분포와 public NLP dataset으로 두 가지 파트로 나뉜다고 했다. 그 중에 첫 번째 평가 영역인 API 분포에 대해서 어떤 결과가 나왔는지 알아보자.
- labeler들은 GPT-3보다 InstructGPT를 더욱 선호함 🔥
- training labeler가 아닌 labeler도 InstructGPT를 더욱 선호함. 게다가 과적합 되지도 않음. ✨
- Public NLP dataset은 LM이 사용되는 방식을 반영하지 못함 😭
더욱 자세한 내용은 논문을 참고하길 바란다.
4-2. Results on public NLP dataset
두 번째 평가 영역인 public NLP dataset에 대해서 알아보자.
- InstructGPT는 GPT-3에 비해 truthfulness가 향상된 모습을 보여줌 📈
- toxicity도 미미하지만 향상되었음. 그리고 덜 편향적인 모습을 보여줌 😑
- RLHF 프로시저를 수정해서 public NLP dataset에 대해 성능 감소를 최소화시킬 수 있었음 🫣
- PPO fine-tuning에 pre-traininig update를 추가
더욱 자세한 내용은 논문을 참고하길 바란다.
4-3. Qualitative results
- 비영어 언어 & code data가 부족했음에도 불구, task를 수행하는 모습을 보여줌 🫢
- alignment method가 사람이 지도하지 않는 데이터에도 수행할 수 있게 해줌
- 그치만 대답은 그 언어가 아닌 보통은 영어로 해줌 😫
- 아직 잔실수도 있음 😅
- 잘못된 가정도 진짜라고 판단 😏
- 쉬운 문제임에도 불구, 너무 문제를 꼬아서 생각할 때가 있음 🤨
- 어렵거나 여러가지의 조건을 달게 되면 성능 🔻
더욱 자세한 내용은 논문을 참고하길 바란다.
5. Discussion
5-1. Implications for alignment research
연구를 통해 alignment 연구에 대해 다음과 같은 교훈들을 얻을 수 있었다.
- 모델의 크기를 늘리는 것보다 alignment에 투자하는 것이 더욱 효율적 📈
- InstructGPT는 가르쳐주지 않은 것에도 일반화가 가능 🫡
- 논문에서 제안된 방법의 fine-tuning으로 성능 저하를 완화할 수 있었음 ✨
- 이 논문이 앞으로의 alignment 연구의 발판이 되길 바람 🤗
5-2. Limitations
완벽해 보이는 InstructGPT에도 몇 가지 한계가 있었는데 그 한계는 다음과 같다.
- 40명의 labeler로 모든 사람들의 표현과 감정, 기준을 대변하기에는 부족 😅
- InstructGPT는 완벽하게 align되지도, 안전하지도 않음 ⚠️
- 가장 큰 한계는, 사용자의 의도가 유해한 대답을 내놓을 것임을 앎에도 불구하고 따른다는 것임 😈
이렇게 해서 InstructGPT의 논문을 읽어보고 나름대로 리뷰를 진행해 보았는데, 지금까지와는 완전히 다른 새로운 방법으로 나한테 다가왔기에 아직도 제대로 이해하지 못한 부분들도 많았던 것 같다. 포스트를 읽으면서 이상하거나, 부족한 부분이 있다면 언제든 코멘트 해주시면 바로바로 수정하도록 하겠습니다!! 오늘도 글 읽어주시느라 수고 많으셨습니다!! 다음 포스트에서 또 뵙겠습니다!! 감사합니다!! 😘
출처
https://arxiv.org/abs/2203.02155
Training language models to follow instructions with human feedback
Making language models bigger does not inherently make them better at following a user's intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not ali
arxiv.org