
Multiple Features
여러 변수들을 이용한 선형 회귀를 "multivariate linear regression"이라고 부른다. 이제 입력 변수를 얼마든지 가질 수 있는 방정식에 대한 표기법을 소개하도록 하겠다.

hypothesis function의 다변수 형태는 다음과 같이 여러 feature들을 수용한다.
$h_{\theta}(x) = \theta_{0} + \theta_{1}x_{1} + \theta_{2}x_{2} + \theta_{3}x_{3} + \cdots + \theta_{n}x_{n}$
위 수식에 대한 이해를 돕기 위해 집 가격 예 예시를 적용해보면, $\theta_{0}$은 일반적인 집 가격, $\theta_{1}$은 제곱 미터 당 가격, $\theta_{2}$은 층 수 당 가격을 뜻한다. 그렇다면 여기서 $x_{1}$은 집의 제곱 미터 크기를 의미하고, $x_{2}$은 층의 수를 의미한다.
행렬곱의 개념을 이용하여 다변수 hypothesis function을 정의하면 다음과 같다.

위 수식은 하나의 training example에 대한 hypothesis function의 벡터화이다.
Gradient Descent For Multiple Variables
다변수가 된다고 해서 경사 하강법의 방정식의 형태는 유지된다. 그저 $n$개의 feature에 대해 반복할 뿐이다.
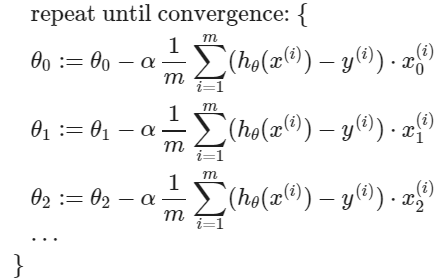
이를 다르게 작성하면 다음과 같다.

다음의 그림은 단일 변수 경사 하강 방정식과 다변수 경사 하강 방정식을 비교하고 있다.

Gradient Descent - Feature Scaling
각각의 입력 변수들을 똑같은 범위에 둠으로써 경사 하강법의 속도를 빠르게 할 수 있다. 이는 $\theta$가 작은 범위 내에서는 빠르게 하강하게 되고, 넓은 범위에 대해서는 천천히 하강하기 때문이다. 따라서 변수가 매우 고르지 않을 때 비효율적으로 진동하게 된다. 이를 방지하기 위한 방법은 입력 변수의 범위를 조정해서 모두 똑같게 만드는 것이다. 예를 들어 $-1 \leq x_{(i)} \leq 1$ 또는 $-0.5 \leq x_{(i)} \leq 0.5$의 범위를 정하는 것이다!
이것은 꼭 요구되는 것은 아니지만, 속도를 올리기 위해서는 요구된다. 이 과정의 목표는 모든 입력 변수들을 이 범위안에 집어넣는 것이다.
이 과정을 도와주는 두 가지 방법이 있는데 feature scaling과 mean normalization이 있다.
- feature scaling은 입력 변수들을 입력 변수의 범위에 의해 나눔으로써 1의 범위를 가지는 새로운 범위를 도출해내는 것이다.
- mean normalization은 해당 입력 변수의 값에서 입력 변수의 평균 값을 빼서 입력 변수의 새로운 평균 값을 0으로 만드는 방법이다.
이 두 방법을 적용하기 위해서는 입력 변수를 다음의 수식으로 조정해야 한다.
$x_{i} := \frac {x_{i} - \mu_{i}}{s_{i}}$
여기서 $\mu_{i}$는 feature $(i)$에 대한 모든 값들의 평균이고, $s_{i}$는 값의 범위$(max - min)$이거나 표준 편차이다. 범위 또는 표준 편차, 둘 중 무엇에 의해 나눠지냐에 따라서 다른 결과가 주어지게 된다. 예를 들어 $x_{i}$가 100부터 2000 까지의 집 값을 나타내고, 평균값이 1000일 때, $x_{i}$는 다음과 같다.
$x_{i} := \frac {price - 1000}{1900}$
Gradient Descent - Learning Rate
Debugging gradient descent. $x$축에 반복의 수를 나타내는 그래프를 그려보자. 이제 경사 하강법의 반복 횟수에 대한 cost function $J(\theta)$를 그려보자. $J(\theta)$가 상승하게 되면, $\alpha$의 값을 줄여야 할 필요가 있다.
Automatic convergence test. 한 반복에서 $J(\theta)$의 값이 $10^{-3}$같이 매우 작은 값인 $E$보다 적게 줄어든다면 수렴이라고 정의해야 한다. 하지만, 실전에서 이 기준값을 정하는 것은 매우 어렵다..

learning rate $\alpha$가 충분히 작다면, $J(\theta)$는 매 반복에서 줄어들게 된다.

이를 요약하면 다음과 같다.
- $\alpha$가 너무 작을 때: 천천히 수렴
- $\alpha$가 너무 클 때: 매 반복마다 줄어들지 않을 수 있고, 결국 수렴하지 않을 수도 있음
Features & Polynomial Regression
feature와 hypothesis function의 형태를 다음의 두 가지 방법으로 향상시킬 수 있다. 그 중 한 가지 방법으로 여러 개의 feature을 하나로 묶을 수 있다. 예를 들어, $x_{1}$과 $x_{2}$를 $x_{1} \cdot x_{2}$을 통해 새로운 feature $x_{3}$를 얻어낼 수 있다.
Polynomial Regression
hypothesis function이 꼭 선형일 필요는 없다. 만약 직선이 데이터에 잘 맞지 않다면 다른 형태여도 된다. 이를 위해 hypothesis function의 특성과 곡선을 제곱 또는 세제곱, 제곱근을 사용하여 바꿀 수 있다.
예를 들어, hypothesis function이 $h_{\theta}(x) = \theta_{0} + \theta_{1}x_{1}$일 때, $x_{1}$에 기반해서 새로운feature을 추가해서 이차 함수 $h_{\theta}(x) = \theta_{0} + \theta_{1}x_{1} + \theta_{2}x_{1}^{2}$ 또는 삼차 함수 $h_{\theta}(x) = \theta_{0} + \theta_{1}x_{1} + \theta_{2}x_{1}^{2} + \theta_{3}x_{1}^{3}$을 얻을 수도 있다.
삼차 함수의 경우에 새로운 feature $x_{2}$와 $x_{3}$를 $x_{2} = x_{1}^{2}$과 $x_{3} = x_{1}^{3}$을 통해 만들어낼 수 있다.
이를 제곱근 함수로 만들기 위해서는 다음을 해주면 된다: $h_{\theta}(x) = \theta_{0} +\theta_{1}x_{1} + \theta_{2} \sqrt{x_{1}}$
한 가지 기억해야 할 점은 feature을 이와 같은 방식으로 선택했을 때, feature scaling이 매우 중요해진다는 것이다!
'Lecture 🧑🏫 > Coursera' 카테고리의 다른 글
| [Machine Learning] Classification & Representation (0) | 2023.03.15 |
|---|---|
| [Machine Learning] Computing Parameters Analytically (0) | 2023.03.14 |
| [Machine Learning] Parameter Learning - Gradient Descent (0) | 2023.03.13 |
| [Machine Learning] Model & Cost Function (0) | 2023.03.13 |
| [Machine Learning] What is Machine Learning? - Supervised Learning & Unsupervised Learning (0) | 2023.03.13 |