
Gradient Descent
이제 hypothesis function과 이 함수가 데이터에 얼마나 잘 맞는지 측정하는 방법도 가지고 있다. 이제 hypothesis function에서의 parameter를 측정해야 한다. 여기서 경사 하강법이 등장하게 된다.
$\theta_{0}$과 $\theta_{1}$에 기반해서 hypothesis function의 그래프를 상상해보도록 하자. $x$와 $y$ 자체를 그래프로 표시하는 것이 아니라 hypothesis function의 파라미터 범위와 특정 파라미터 집합을 선택해서 발생하는 비용을 그래프로 표시한다.
$\theta_{0}$을 $x$축, $\theta_{1}$을 $y$축, cost function을 수직 $z$축으로 두어보자. 그래프의 점은 특정 $\theta$ 파라미터와 함께 hypothesis를 사용하는 cost function의 결과이다. 아래 그래프는 그러한 설정을 보여준다.

우리는 그래프에서 cost function의 값이 매우 바닥에 있을 때 성공한다는 것을 알 수 있었다. 이는 다시 말해 최솟값에 있을 때를 말한다. 빨간색 화살표가 그래프의 최솟값 지점을 나타낸다.
이것을 하는 방법은 cost fuction의 미분$($함수의 탄젠트 선$)$을 사용하는 것이다. 탄젠트의 기울기는 그 시점에서의 미분이고, 이는 움직여야할 방향을 제공해준다. 결국에 더욱 가파른 기울기의 방향으로 cost function을 낮춰간다. 각 스텝의 크기는 파라미터 $\alpha$에 의해 결정되는데, 이를 learning rate$($학습률$)$이라 부른다.
예를 들어, 위 그림에서 각 별들의 거리는 파라미터 $\alpha$에 의해 결정된다. 작은 값의 $\alpha$는 작은 스텝을, 큰 값의 $\alpha$는 큰 스텝을 결과로 갖는다. 스텝이 진행될 방향은 $J(\theta_{0}, \theta_{1})$에 의해 결정된다. 경사 하강법을 어느 위치에서 시작하느냐가 어느 위치에서 끝나게 될 지를 결정한다. 위의 그림을 보면 알 수 있듯이 서로 다른 시작 지점은 서로 다른 수렴을 가져온다.
경사 하강 알고리즘은 다음의 식을 수렴할 때까지 반복한다.

여기서 $j = 0, 1$은 feature 인덱스 넘버를 나타낸다.
각 반복 $j$에서, 파라미터 $\theta_{0}, \theta_{1}, ..., \theta_{n}$을 동시에 업데이트해야 한다. 다른 파라미터의 값을 계산하기 전에 특정 파라미터를 업데이트 하면 잘못된 업데이트를 불러오게 된다.

Gradient Descent Intuition
하나의 파라미터 $\theta_{1}$을 사용해서 이것의 cost function을 경사 하강법을 통해서 그려보았다. 하나의 파라미터에 대한 공식은 다음의 수식을 수렴할 때까지 반복하면 된다.

$\frac {d}{d \theta_{1}} J(\theta_{1})$을 위한 기울기의 사인에 상관없이, $\theta_{1}$은 최솟값에 수렴하게 된다. 다음의 그래프는 기울기가 음수일 때는 $\theta_{1}$의 값이 증가하고, 양수일 때는 $\theta_{1}$의 값이 감소하는 것을 보여준다.

우리는 파라미터 $\alpha$를 경사 하강 알고리즘이 합리적인 시간에 수렴할 수 있게 보장하도록 조정되어야 한다. 수렴에 실패하거나, 최솟값을 얻는데 너무 많은 시간을 쏟는다면 step size가 잘못되었다는 것을 암시한다.

어떻게 경사 하강법은 고정된 step size $\alpha$로 수렴할 수 있을까?
수렴의 뒤에 있는 개념은 $\frac {d}{d \theta_{1}} J(\theta_{1})$이 convex function$($최솟값이 딱 하나로 정해져 있는 함수$)$의 바닥에 접근하는 것처럼 0에 접근하는 것이다. 최솟값에서 이 값은 항상 0이고, 다음의 수식을 얻게 된다.
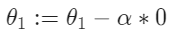

Gradient Descent for Linear Regression
선형 회귀$($linear regression$)$에 적용할 때, 새로운 유형의 경사 하강 수식이 필요하다. 기존의 cost function과 hypothesis function, 그리고 수식을 다음과 같이 조정할 수 있다.

$m$은 training set의 크기를 의미하고, $\theta_{0}$은 $\theta_{1}$와 동시에 변화하고, $x_{i}, y_{i}$는 주어진 training set의 값들이다.
$\theta_{j}$에 대한 두 가지 경우를 $\theta_{0}$ 및 $\theta_{1}$에 대한 별도의 방정식으로 분리했다. $\theta_{1}$의 경우 미분으로 인해 끝에 $x_{i}$를 곱한다. 다음의 수식은 하나의 example에 대한 $\frac {\partial}{\partial \theta_{j}} J(\theta)$의 미분이다.
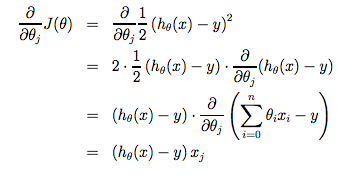
가장 중요한 점은 우리의 hypothesis에 대해 경사 하강식을 반복적으로 적용했을 때, hypothesis가 더욱 정교해진다는 점에서 시작되었다는 것이다.
그래서, 이는 기존의 cost function $J$에 간단하게 경사 하강법을 한 것이다. 이 method는 모든 step에서 전체 training set의 모든 example을 참조하기 때문에, 이를 batch gradient descent라고 부른다. 경사 하강법은 일반적으로 local minima에 수렴하기 쉽지만, 여기에서 사용한 linear regression의 경우에는 local opitima 없이 오직 하나의 global optima가 존재하기 때문에, 이 경우 경사 하강법은 항상 global minimum에 수렴한다. 사실 $J$는 convex quadratic 함수이다. 다음의 그림은 이차 함수에 대해 경사 하강법을 사용하여 최솟값을 찾는 과정을 보여주고 있다.

위 그림의 타원은 이차 함수의 등고선을 나타낸다. 그리고 경사 하강법의 궤도 또한 보여지고 있는데, 초깃값은 $(48, 30)$이다. 위 그림의 $x$들은 경사 하강법이 최솟값으로 수렴하면서 통과한 $\theta$의 연속 값을 표시한다.
'Lecture 🧑🏫 > Coursera' 카테고리의 다른 글
| [Machine Learning] Computing Parameters Analytically (0) | 2023.03.14 |
|---|---|
| [Machine Learning] Multivariate Linear Regression (0) | 2023.03.14 |
| [Machine Learning] Model & Cost Function (0) | 2023.03.13 |
| [Machine Learning] What is Machine Learning? - Supervised Learning & Unsupervised Learning (0) | 2023.03.13 |
| Stanford University Machine Learning 강의(Andrew Ng) (0) | 2023.03.13 |