
Pre-trained Language Modeling paper reading
요즘 NLP 분야에서 뜨거운 감자인 pre-trained Language Modeling에 관한 유명한 논문들을 읽고 리뷰를 하였다. 이 Pre-trained Language Modeling paper reading은 이 포스트만으로 끝나는 것이 아니라 연속된 포스트를 작성할 생각이다. 그래서 이 포스트는 Pre-trained Language Modeling paper reading의 첫 서막을 여는 포스트이다. 앞으로의 포스트 계획은 아래와 같다.
- ELMo: 'Deep contextualized word representations' reading & review(this post)
- BERT: 'Pre-training of Deep Bidirectional Transformers for Language Understanding' reading & review
- GPT-1: 'Improving Language Understanding by Generative Pre-Training' reading & review
그래서 오늘은 ELMo 논문에 대해서 읽고 리뷰를 해볼 것이다. ELMo 논문은 여기에서 확인할 수 있다.
Table of Contents
1. Introduction
2. ELMo: Embedding from Language Models
2-1. Bidirectional language models
2-2. ELMo
2-3. Using biLMs for supervised NLP tasks
2-4. Pre-trained bidirectional language model architecture
3. 알아보기 쉽게 ELMo 설명
4. Analysis
1. Introduction
이 논문의 저자들이 말하고자 하는 바는 pre-trained word representation 자체가 이로부터 시작되는 다양한 NLP tasks에 대한 key component라고 주장한다. 그리고 high quality representation은 조건들을 따라야 하는데 그 조건들은 다음과 같다.
- 단어의 복잡한 특징을 모델링할 수 있어야 한다. (구문 분석 관점에서 사용되는 것 & 의미 분석 관점에서 사용되는 것을 전부 다 커버해야 됨)
- 단어들이 linguistic context 상에서 서로 다르게 사용될 때, 해당하는 사용법에 맞는 representation을 표현해줘야 한다. 예를 들어 다의어인 '배'라는 단어에 대해 과일의 의미로 사용될 때와 운송수단의 의미로 사용될 때 이 두 상황의 임베딩 벡터가 달라야 한다는 것이다.
ELMo의 특징
ELMo는 각각의 token들에 대해 전체 input sentence의 함수를 representation으로 받는다. 그리고 ELMo는 language model에 대한 목적 함수를 가지고 학습이 되는 bidirectional-LSTM으로부터 유래되는 vector를 사용한다. 그래서 ELMo 자체는 전체의 입력 문장을 이용을 한 representation이고, 그리고 이 문장은 bidirectional-LSTM을 이용하여 학습이 된다. 다음은 ELMo의 특징이다.
- ELMo는 상당히 deep한 모델인데, 이는 bidirectional-LSTM의 모든 내부 internal layer에 해당하는 히든 벡터들을 결합시키기 때문이다. 따라서 특정한 층에 해당하는 값을 사용하는 것이 아니라 bidirectional-LSTM이 학습이 되었을 때 나오는, 다양한 히든 벡터들을 결합하는 방식으로 사용될 것이다.
- 하나의 position에 있는 단어에 여러 층에 해당하는 정보들을 결합한다. 가장 윗 단의 LSTM layer를 사용한 representation보다 성능이 훨씬 향상되었다.
- 여러 단계의 representation을 사용함으로써 위쪽에 있는 높은 레벨에 있는 hidden state들은 context-dependent하고, 보다 낮은 레벨에 있는 hidden state들은 syntax에 해당하는 특징들을 포함하고 있다. 그래서 만약 syntax 한 문제를 해결하기 위해서는 보다 낮은 layer의 hidden state들에 더 높은 가중치를 주면 되고, context-dependent 한 문제를 해결하기 위해서는 높은 layer의 hidden state들에 더 높은 가중치를 주면 된다.
2. ELMo: Embedding from Language Models
이번 장에서는 ELMo의 구조에 대해서 설명한다. ELMo는 내부 네트워크 상태(2-2)의 선형 함수로서 문자 컨볼루션(2-1)이 있는 2계층 biLM 위에서 계산된다. 이 설정을 통해 biLM이 대규모로 사전 훈련되고(2-4) 기존의 광범위한 neural NLP architecture(2-3)에 쉽게 통합되는 semi-supervised learning을 수행할 수 있다.
2-1. Bidirectional language modeling
Bidirectional language modeling은 크게 두 가지로 나뉘는데 forward LM과 backward LM이다. 말 그래도 이 둘은 sequence가 주어졌을 때, 각각 앞에서부터 해석을 하는지와 뒤에서부터 해석을 하는지이다. N개의 token sequence인 (t_1, t_2, ..., t_N)가 주어졌을 때 Bidirectional LM은 다음과 같은 과정으로 진행된다.
forward LM
먼저 forward LM에 대해 알아보겠다. forward LM은 sequence probability를 이미 주어졌던 토큰들인(t_1, ..., t_k-1)에 대해 모델링을 진행하면서 구한다. 아래의 수식이 그 과정이다.

최근의 SOTA neural language model들은 context-independent한 token representation x^LM_k(논문에서 확인하시오)를 계산하고 그다음에 이것을 L layer의 forward LSTM들에 흘려보낸다. 각각의 k position에서 각각의 LSTM layer는 context-dependent 한 representation인 j=1, ..., L인 forward h^LM_i,j(논문에서 확인하시오)를 출력해낸다. 가장 높은 LSTM층의 출력인 forward h^LM_k,L은 Softmax layer와 함께 다음 토큰인 t_k+1을 예측하는 데 사용된다.
backward LM
backward LM도 forward LM과 sequence를 반대 방향부터 run한다는 점만 제외하면 비슷하다. 한 마디로 future context가 주어졌을 때 이전의 token을 예측하는 것이다. 아래의 수식이 그 과정이다.

이것도 forward LM과 유사하게 적영될 수 있는데 representation을 생성하는 L layer deep model의 각 backward LSTM 계층 j로 주어진 t_k인 (t_k+1, ..., t_N)의 backward h^LM_k,j(논문에서 확인하시오).
biLM
biLM은 forward LM과 backward LM의 결합이다. 논문의 식은 forward와 backeward direction에 대해 공동으로 log likelihood를 극대화 시킨다. 아래 수식이 biLM의 과정이다.

논문에서는 token representation(Θx)와 Softmax layer(Θs) 모두에 대한 parameter를 forward와 backward로 묶고 각 방향에서 LSTM에 대한 별도의 parameter를 유지하게 했다. 이 식은 이전의 연구와 비슷한 모습을 보이지만, 완전히 독립적인 parameter로 한 것이 아닌 방향들 사이에서 가중치를 공유하는 방식으로 진행하였다.
2-2. ELMo
ELMo는 biLM의 중간 계층들의 representation의 task specific한 combination이다. 각각의 token t_k에 대해 L-layer biLM은 2L+1의 representation을 계산해야 한다. 아래 수식이 그 과정이다.

h^LM_k,0(논문에서 확인하시오)은 token layer이고, h^LM_k,j는 각각의 biLSTM layer에 대한 forward LM과 backward LM이다.
downstream model에서 ELMo는 R의 모든 layer를 하나의 벡터 ELMo_k = E(R_k;Θ_e)로 collapse 시킨다. 논문에서는 task specific 한 weighting을 모든 biLM layer에 대해 진행하였다. 그 식은 다음과 같다.

s^task는 softmax-normalized 가중치인데, 이는 task specific하게 가중치를 학습시킨다(이 내용은 3장에서 다시 한번 설명). γ(감마)^task는 scalar parameter로 task model에게 모든 ELMo vector를 scale 할 수 있게 해 준다.γ(감마)는 optimization process를 도와주는 중요한 요소이다. 이는 전체 가중합이 된 pre-trainced vector를 얼마나 확대 또는 축소시킬지 결정하는 값이다. 각각의 biLM layer의 activation은 서로 다른 distribution을 가지는데, 어떤 상황에서는 각각의 biLM layer에 layer normalization을 weighting 하기 전에 적용하는 것에 도움을 준다.
2-3. Using biLMs for supervised NLP tasks
NLP task에 대한 architecture와 pre-trained되 biLM이 주어졌을 때, biLM을 각각의 단어의 모든 representation layer에 돌리면, 마지막에 모델은 이 representation들에 대한 선형 결합을 얻을 수 있다. 이 과정은 아래에서 더욱 자세히 설명하겠다.
- 첫 번째로, 가장 layer의 가장 밑동은 biLM이 적용되지 않았다. 많은 supervised NLP model들은 일반적인 architecture을 공유하기 때문에, ELMo를 적용할 수 있다. 토큰 시퀀스(t_1, ... , t_N )가 주어지면 pre-trained word embedding과 선택적으로 chracter-based representation을 사용하여 각 토큰 위치에 대해 context-independent toekn representation x_k를 형성하는 것이 표준이다. 그런 다음 모델은 일반적으로 양방향 RNN, CNN 또는 피드 포워드 네트워크를 사용하여 상황에 맞는 표현 h_k를 형성한다.
- 그다음으로, supervised model에 ELMo를 추가하기 위해 처음에 biLM 가중치를 freeze 하고 ELMo^task_k와 x_k를 concatenate 하여 향상된 ELMo representation을 task RNN에 통과시킨다.
- 마지막으로, ELMo에도 적당한 양의 dropout을 추가시키고 어떤 경우에는 loss에 람다값(논문에서 확인하시오)을 추가하여 ELMo 가중치를 정규화한다. 이것은 모든 biLM layer의 평균에 가깝게 유지하기 위해 ELMo weights에 indeuctive bias를 부과한다.
2-4. Pre-trained bidirectional language model architecture
이 논문의 pre-trained biLMs는 이전의 논문들과 유사한데, 양방향을 계산하기 위해 살짝 수정되었고, residual connection을 LSTM layers 사이에 추가하였다.
논문에서 사용된 최종 모델은 L = 2인 biLSTM이고, 이것은 4096개의 unit과 512개의 dimension projection을 가지고 있고, residual connection이 첫 번째 layer로부터 두 번째 layer까지 있다. 결과적으로 biLM은 purely character input으로 인해 훈련 세트 외부의 representation을 포함하여 각 input token에 대해 3개의 representation layer를 제공한다. 반면에 전통적인 word embedding method들은 오직 하나의 representation layer를 고정된 vocabulary 안의 tokens에 대해 제공한다.
10 epochs의 훈련을 거치고 난 후에 forward CNN-BIG-LSTM는 perplexity가 30.0인 것에 비해 forward와 backward의 perplexities의 평균은 39.7이었다. 일반적으로, forward 및 backward perplexities가 거의 동일하고 backward 값이 약간 더 낮다는 것을 발견했다.
3. 알아보기 쉽게 ELMo 설명
이번 장에서는 이 사이트에서 설명하는 ELMo에 대해 다시 한 번 설명해보았다.
ELMo는 각각의 단어에 대해 embedding을 하는 것 대신에, 각각의 단어를 embedding에 할당하기 전에 전체 sentence를 한 번 둘러본다. ELMo는 specific task에 대해 훈련된 bidirectional-LSTM을 이용하여 이러한 embedding을 생성할 수 있었다. ELMo는 NLP의 맥락에서 pre-training을 향한 중요한 단계를 제공했다. ELMo의 LSTM은 어떠한 광범위한 데이터셋으로부터 훈련돼서 다른 모델의 구성 요소로 사용할 수 있다. 한 마디로, 내가 사용한 dataset에 대해 훈련을 진행하고 이 훈련된 ELMo를 다른 모델에 사용할 수 있다는 것이다.
ELMo's secret
ELMo는 word sequence가 주어졌을 때 다음 단어를 예측하는 이른 바 Langauge Modeling을 통해 language understanding을 얻는다. 다음의 그림은 ELMo의 pre-training process를 보여준다. 아래의 그림에서는 'Let's', 'stick', 'to'라는 단어를 받았을 때, 각각의 embedding vector을 집어넣어서 LSTM의 layer들에 태우게 되면 이전 단어들의 embedding vector을 이용해서 다음 단어를 예측하게 된다.

위의 그림을 보면 ELMo 캐릭터의 머리 뒤에 정점에 도달한 각각의 unrolled-LSTM 단계의 숨겨진 상태를 볼 수 있다. pre-training 단계가 끝나고 이것들은 embedding process에서 유용하다. ELMo는 추가적인 step들을 진행하고 bidirectional LSTM을 훈련시킨다. 따라서 ELMo는 다음 단어를 예측하는 능력만 가지는 것이 아니라 이전 단어에 대한 예측도 가능하게 된다. 다음 그림이 ELMo의 biLM을 보여준다.
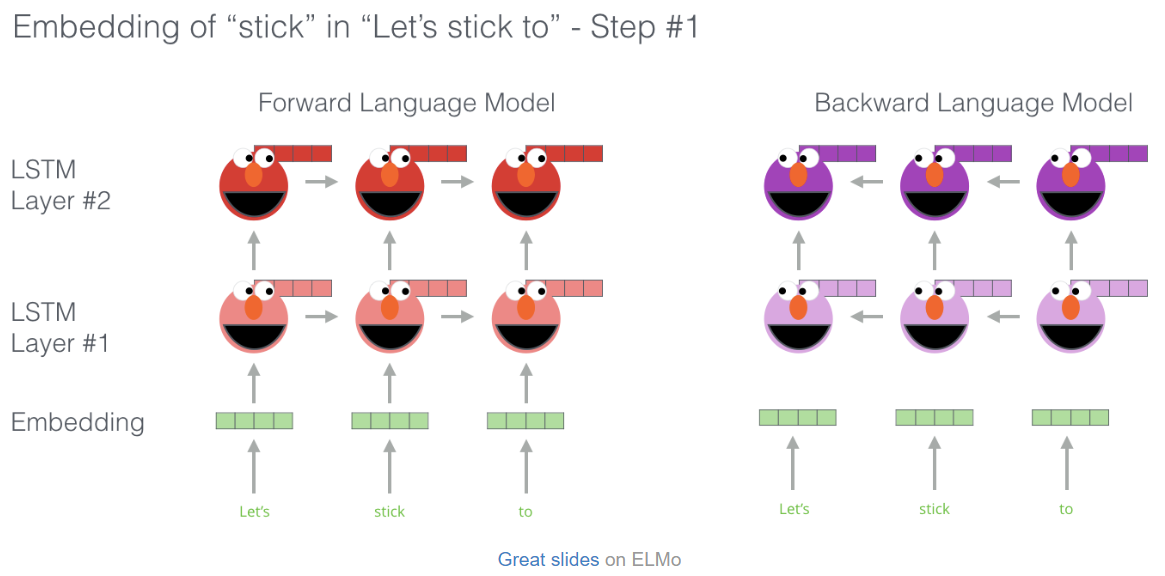
그리고 ELMo는 hidden states(and initial embedding)를 특정한 방법(가중치 합으로 인한 concatenation)으로 grouping 시키는 과정을 통해 contextualized embedding을 만들어낸다. 다음의 그림은 이 과정을 나타낸다.
- stick이라는 단어가 존재하는 이 시점에서의 위치가 forward와 backward에서 동일하고, 각각의 같은 동일한 레벨에 있는 hidden state vector을 concatenaton을 한다. 다시 말하자면, forward의 input값과 backward의 input값을 합친 것이 Concatenate hidden layer의 첫 번째 값이 되는 것이고, 이와 같은 과정을 거쳐 아래 그림의 왼쪽 상단에 위치해있는 Concatenate hidden layers가 만들어지는 것이다. 이 말인즉슨, forward 모델과 backward 모델에 대해서 같은 레벨에 있는 hidden state들을 옆으로 concatenation 한 것이다.
- 그 뒤에 특정한 task에 대해서 이 3개의 벡터들에 대한 적절한 가중합을 계산해서(s_0, s_1, s_2 계산) 가중합을 하게 되면 아래 그림의 좌측 하단에 위치해 있는 파란색 벡터가 만들어지게 된다. 그리고 이게 바로 ELMo에 의해서 만들어진 'stick' 이라는 단어에 대한 embedding 값이다.
- 가중합을 할 때 s_0, s_1, s_2는 task에 따라서 변화하는 parameter이다. 따라서 어떤 task가 주어지느냐에 따라 학습이 함께 진행된다. 만약 syntax에 대한 task를 진행하려면 아래에 레벨에 위치해 있는 벡터에 대해 더 큰 가중치를 갖게 될 것이고, contextual 한 task를 진행하려면 위의 레벨에 위치해 있는 벡터에 대해 더 큰 가중치를 갖게 될 것이다.

4. Analysis
논문에서는 Experiment를 진행하고 나서 몇 가지의 Ablation Study를 진행했는데 그 중에 몇 가지를 살펴보았다.
Alternate layer weighting scheme
이 layer를 어떻게 가중합을 하는 게 좋으냐 라는 질문이 던져졌을 때 논문에서는 다음의 그림과 같이 답하였다.
위의 그림을 해석해보면 첫 번째로는 task에 따라서 가중치 값을 다르게 주는 것이 가장 성능이 좋고, 그다음으로는 모든 벡터들에 대해 똑같은 가중치를 주는 것이 성능이 좋았고, 그다음으로는 제일 높은 레벨의 벡터에 가중치를 주는 것이 나았다.
Where to include ELMo?
ELMo를 어디에 집어넣는 것이 더 좋을지에 대한 질문에 대한 답이다. 다음 그림과 같이 답하였다. 다음 그림은 LM이 아닌 downstream task에 해당하는 모델이다.

위의 그림을 해석해보면 Input 값과 Output 값에 ELMo를 사용하는 것이 가장 성능이 좋았고, 그 다음으로는 Input에만 사용하는 것이, 그다음에는 Output 값에만 사용하는 것이 성능이 좋았다.
출처
https://arxiv.org/abs/1802.05365
Deep contextualized word representations
We introduce a new type of deep contextualized word representation that models both (1) complex characteristics of word use (e.g., syntax and semantics), and (2) how these uses vary across linguistic contexts (i.e., to model polysemy). Our word vectors are
arxiv.org
https://www.youtube.com/watch?v=zV8kIUwH32M
https://jalammar.github.io/illustrated-bert/
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
Discussions: Hacker News (98 points, 19 comments), Reddit r/MachineLearning (164 points, 20 comments) Translations: Chinese (Simplified), French 1, French 2, Japanese, Korean, Persian, Russian, Spanish 2021 Update: I created this brief and highly accessibl
jalammar.github.io
'Paper Reading 📜 > Natural Language Processing' 카테고리의 다른 글
Pre-trained Language Modeling paper reading
요즘 NLP 분야에서 뜨거운 감자인 pre-trained Language Modeling에 관한 유명한 논문들을 읽고 리뷰를 하였다. 이 Pre-trained Language Modeling paper reading은 이 포스트만으로 끝나는 것이 아니라 연속된 포스트를 작성할 생각이다. 그래서 이 포스트는 Pre-trained Language Modeling paper reading의 첫 서막을 여는 포스트이다. 앞으로의 포스트 계획은 아래와 같다.
- ELMo: 'Deep contextualized word representations' reading & review(this post)
- BERT: 'Pre-training of Deep Bidirectional Transformers for Language Understanding' reading & review
- GPT-1: 'Improving Language Understanding by Generative Pre-Training' reading & review
그래서 오늘은 ELMo 논문에 대해서 읽고 리뷰를 해볼 것이다. ELMo 논문은 여기에서 확인할 수 있다.
Table of Contents
1. Introduction
2. ELMo: Embedding from Language Models
2-1. Bidirectional language models
2-2. ELMo
2-3. Using biLMs for supervised NLP tasks
2-4. Pre-trained bidirectional language model architecture
3. 알아보기 쉽게 ELMo 설명
4. Analysis
1. Introduction
이 논문의 저자들이 말하고자 하는 바는 pre-trained word representation 자체가 이로부터 시작되는 다양한 NLP tasks에 대한 key component라고 주장한다. 그리고 high quality representation은 조건들을 따라야 하는데 그 조건들은 다음과 같다.
- 단어의 복잡한 특징을 모델링할 수 있어야 한다. (구문 분석 관점에서 사용되는 것 & 의미 분석 관점에서 사용되는 것을 전부 다 커버해야 됨)
- 단어들이 linguistic context 상에서 서로 다르게 사용될 때, 해당하는 사용법에 맞는 representation을 표현해줘야 한다. 예를 들어 다의어인 '배'라는 단어에 대해 과일의 의미로 사용될 때와 운송수단의 의미로 사용될 때 이 두 상황의 임베딩 벡터가 달라야 한다는 것이다.
ELMo의 특징
ELMo는 각각의 token들에 대해 전체 input sentence의 함수를 representation으로 받는다. 그리고 ELMo는 language model에 대한 목적 함수를 가지고 학습이 되는 bidirectional-LSTM으로부터 유래되는 vector를 사용한다. 그래서 ELMo 자체는 전체의 입력 문장을 이용을 한 representation이고, 그리고 이 문장은 bidirectional-LSTM을 이용하여 학습이 된다. 다음은 ELMo의 특징이다.
- ELMo는 상당히 deep한 모델인데, 이는 bidirectional-LSTM의 모든 내부 internal layer에 해당하는 히든 벡터들을 결합시키기 때문이다. 따라서 특정한 층에 해당하는 값을 사용하는 것이 아니라 bidirectional-LSTM이 학습이 되었을 때 나오는, 다양한 히든 벡터들을 결합하는 방식으로 사용될 것이다.
- 하나의 position에 있는 단어에 여러 층에 해당하는 정보들을 결합한다. 가장 윗 단의 LSTM layer를 사용한 representation보다 성능이 훨씬 향상되었다.
- 여러 단계의 representation을 사용함으로써 위쪽에 있는 높은 레벨에 있는 hidden state들은 context-dependent하고, 보다 낮은 레벨에 있는 hidden state들은 syntax에 해당하는 특징들을 포함하고 있다. 그래서 만약 syntax 한 문제를 해결하기 위해서는 보다 낮은 layer의 hidden state들에 더 높은 가중치를 주면 되고, context-dependent 한 문제를 해결하기 위해서는 높은 layer의 hidden state들에 더 높은 가중치를 주면 된다.
2. ELMo: Embedding from Language Models
이번 장에서는 ELMo의 구조에 대해서 설명한다. ELMo는 내부 네트워크 상태(2-2)의 선형 함수로서 문자 컨볼루션(2-1)이 있는 2계층 biLM 위에서 계산된다. 이 설정을 통해 biLM이 대규모로 사전 훈련되고(2-4) 기존의 광범위한 neural NLP architecture(2-3)에 쉽게 통합되는 semi-supervised learning을 수행할 수 있다.
2-1. Bidirectional language modeling
Bidirectional language modeling은 크게 두 가지로 나뉘는데 forward LM과 backward LM이다. 말 그래도 이 둘은 sequence가 주어졌을 때, 각각 앞에서부터 해석을 하는지와 뒤에서부터 해석을 하는지이다. N개의 token sequence인 (t_1, t_2, ..., t_N)가 주어졌을 때 Bidirectional LM은 다음과 같은 과정으로 진행된다.
forward LM
먼저 forward LM에 대해 알아보겠다. forward LM은 sequence probability를 이미 주어졌던 토큰들인(t_1, ..., t_k-1)에 대해 모델링을 진행하면서 구한다. 아래의 수식이 그 과정이다.
최근의 SOTA neural language model들은 context-independent한 token representation x^LM_k(논문에서 확인하시오)를 계산하고 그다음에 이것을 L layer의 forward LSTM들에 흘려보낸다. 각각의 k position에서 각각의 LSTM layer는 context-dependent 한 representation인 j=1, ..., L인 forward h^LM_i,j(논문에서 확인하시오)를 출력해낸다. 가장 높은 LSTM층의 출력인 forward h^LM_k,L은 Softmax layer와 함께 다음 토큰인 t_k+1을 예측하는 데 사용된다.
backward LM
backward LM도 forward LM과 sequence를 반대 방향부터 run한다는 점만 제외하면 비슷하다. 한 마디로 future context가 주어졌을 때 이전의 token을 예측하는 것이다. 아래의 수식이 그 과정이다.
이것도 forward LM과 유사하게 적영될 수 있는데 representation을 생성하는 L layer deep model의 각 backward LSTM 계층 j로 주어진 t_k인 (t_k+1, ..., t_N)의 backward h^LM_k,j(논문에서 확인하시오).
biLM
biLM은 forward LM과 backward LM의 결합이다. 논문의 식은 forward와 backeward direction에 대해 공동으로 log likelihood를 극대화 시킨다. 아래 수식이 biLM의 과정이다.
논문에서는 token representation(Θx)와 Softmax layer(Θs) 모두에 대한 parameter를 forward와 backward로 묶고 각 방향에서 LSTM에 대한 별도의 parameter를 유지하게 했다. 이 식은 이전의 연구와 비슷한 모습을 보이지만, 완전히 독립적인 parameter로 한 것이 아닌 방향들 사이에서 가중치를 공유하는 방식으로 진행하였다.
2-2. ELMo
ELMo는 biLM의 중간 계층들의 representation의 task specific한 combination이다. 각각의 token t_k에 대해 L-layer biLM은 2L+1의 representation을 계산해야 한다. 아래 수식이 그 과정이다.
h^LM_k,0(논문에서 확인하시오)은 token layer이고, h^LM_k,j는 각각의 biLSTM layer에 대한 forward LM과 backward LM이다.
downstream model에서 ELMo는 R의 모든 layer를 하나의 벡터 ELMo_k = E(R_k;Θ_e)로 collapse 시킨다. 논문에서는 task specific 한 weighting을 모든 biLM layer에 대해 진행하였다. 그 식은 다음과 같다.
s^task는 softmax-normalized 가중치인데, 이는 task specific하게 가중치를 학습시킨다(이 내용은 3장에서 다시 한번 설명). γ(감마)^task는 scalar parameter로 task model에게 모든 ELMo vector를 scale 할 수 있게 해 준다.γ(감마)는 optimization process를 도와주는 중요한 요소이다. 이는 전체 가중합이 된 pre-trainced vector를 얼마나 확대 또는 축소시킬지 결정하는 값이다. 각각의 biLM layer의 activation은 서로 다른 distribution을 가지는데, 어떤 상황에서는 각각의 biLM layer에 layer normalization을 weighting 하기 전에 적용하는 것에 도움을 준다.
2-3. Using biLMs for supervised NLP tasks
NLP task에 대한 architecture와 pre-trained되 biLM이 주어졌을 때, biLM을 각각의 단어의 모든 representation layer에 돌리면, 마지막에 모델은 이 representation들에 대한 선형 결합을 얻을 수 있다. 이 과정은 아래에서 더욱 자세히 설명하겠다.
- 첫 번째로, 가장 layer의 가장 밑동은 biLM이 적용되지 않았다. 많은 supervised NLP model들은 일반적인 architecture을 공유하기 때문에, ELMo를 적용할 수 있다. 토큰 시퀀스(t_1, ... , t_N )가 주어지면 pre-trained word embedding과 선택적으로 chracter-based representation을 사용하여 각 토큰 위치에 대해 context-independent toekn representation x_k를 형성하는 것이 표준이다. 그런 다음 모델은 일반적으로 양방향 RNN, CNN 또는 피드 포워드 네트워크를 사용하여 상황에 맞는 표현 h_k를 형성한다.
- 그다음으로, supervised model에 ELMo를 추가하기 위해 처음에 biLM 가중치를 freeze 하고 ELMo^task_k와 x_k를 concatenate 하여 향상된 ELMo representation을 task RNN에 통과시킨다.
- 마지막으로, ELMo에도 적당한 양의 dropout을 추가시키고 어떤 경우에는 loss에 람다값(논문에서 확인하시오)을 추가하여 ELMo 가중치를 정규화한다. 이것은 모든 biLM layer의 평균에 가깝게 유지하기 위해 ELMo weights에 indeuctive bias를 부과한다.
2-4. Pre-trained bidirectional language model architecture
이 논문의 pre-trained biLMs는 이전의 논문들과 유사한데, 양방향을 계산하기 위해 살짝 수정되었고, residual connection을 LSTM layers 사이에 추가하였다.
논문에서 사용된 최종 모델은 L = 2인 biLSTM이고, 이것은 4096개의 unit과 512개의 dimension projection을 가지고 있고, residual connection이 첫 번째 layer로부터 두 번째 layer까지 있다. 결과적으로 biLM은 purely character input으로 인해 훈련 세트 외부의 representation을 포함하여 각 input token에 대해 3개의 representation layer를 제공한다. 반면에 전통적인 word embedding method들은 오직 하나의 representation layer를 고정된 vocabulary 안의 tokens에 대해 제공한다.
10 epochs의 훈련을 거치고 난 후에 forward CNN-BIG-LSTM는 perplexity가 30.0인 것에 비해 forward와 backward의 perplexities의 평균은 39.7이었다. 일반적으로, forward 및 backward perplexities가 거의 동일하고 backward 값이 약간 더 낮다는 것을 발견했다.
3. 알아보기 쉽게 ELMo 설명
이번 장에서는 이 사이트에서 설명하는 ELMo에 대해 다시 한 번 설명해보았다.
ELMo는 각각의 단어에 대해 embedding을 하는 것 대신에, 각각의 단어를 embedding에 할당하기 전에 전체 sentence를 한 번 둘러본다. ELMo는 specific task에 대해 훈련된 bidirectional-LSTM을 이용하여 이러한 embedding을 생성할 수 있었다. ELMo는 NLP의 맥락에서 pre-training을 향한 중요한 단계를 제공했다. ELMo의 LSTM은 어떠한 광범위한 데이터셋으로부터 훈련돼서 다른 모델의 구성 요소로 사용할 수 있다. 한 마디로, 내가 사용한 dataset에 대해 훈련을 진행하고 이 훈련된 ELMo를 다른 모델에 사용할 수 있다는 것이다.
ELMo's secret
ELMo는 word sequence가 주어졌을 때 다음 단어를 예측하는 이른 바 Langauge Modeling을 통해 language understanding을 얻는다. 다음의 그림은 ELMo의 pre-training process를 보여준다. 아래의 그림에서는 'Let's', 'stick', 'to'라는 단어를 받았을 때, 각각의 embedding vector을 집어넣어서 LSTM의 layer들에 태우게 되면 이전 단어들의 embedding vector을 이용해서 다음 단어를 예측하게 된다.
위의 그림을 보면 ELMo 캐릭터의 머리 뒤에 정점에 도달한 각각의 unrolled-LSTM 단계의 숨겨진 상태를 볼 수 있다. pre-training 단계가 끝나고 이것들은 embedding process에서 유용하다. ELMo는 추가적인 step들을 진행하고 bidirectional LSTM을 훈련시킨다. 따라서 ELMo는 다음 단어를 예측하는 능력만 가지는 것이 아니라 이전 단어에 대한 예측도 가능하게 된다. 다음 그림이 ELMo의 biLM을 보여준다.
그리고 ELMo는 hidden states(and initial embedding)를 특정한 방법(가중치 합으로 인한 concatenation)으로 grouping 시키는 과정을 통해 contextualized embedding을 만들어낸다. 다음의 그림은 이 과정을 나타낸다.
- stick이라는 단어가 존재하는 이 시점에서의 위치가 forward와 backward에서 동일하고, 각각의 같은 동일한 레벨에 있는 hidden state vector을 concatenaton을 한다. 다시 말하자면, forward의 input값과 backward의 input값을 합친 것이 Concatenate hidden layer의 첫 번째 값이 되는 것이고, 이와 같은 과정을 거쳐 아래 그림의 왼쪽 상단에 위치해있는 Concatenate hidden layers가 만들어지는 것이다. 이 말인즉슨, forward 모델과 backward 모델에 대해서 같은 레벨에 있는 hidden state들을 옆으로 concatenation 한 것이다.
- 그 뒤에 특정한 task에 대해서 이 3개의 벡터들에 대한 적절한 가중합을 계산해서(s_0, s_1, s_2 계산) 가중합을 하게 되면 아래 그림의 좌측 하단에 위치해 있는 파란색 벡터가 만들어지게 된다. 그리고 이게 바로 ELMo에 의해서 만들어진 'stick' 이라는 단어에 대한 embedding 값이다.
- 가중합을 할 때 s_0, s_1, s_2는 task에 따라서 변화하는 parameter이다. 따라서 어떤 task가 주어지느냐에 따라 학습이 함께 진행된다. 만약 syntax에 대한 task를 진행하려면 아래에 레벨에 위치해 있는 벡터에 대해 더 큰 가중치를 갖게 될 것이고, contextual 한 task를 진행하려면 위의 레벨에 위치해 있는 벡터에 대해 더 큰 가중치를 갖게 될 것이다.
4. Analysis
논문에서는 Experiment를 진행하고 나서 몇 가지의 Ablation Study를 진행했는데 그 중에 몇 가지를 살펴보았다.
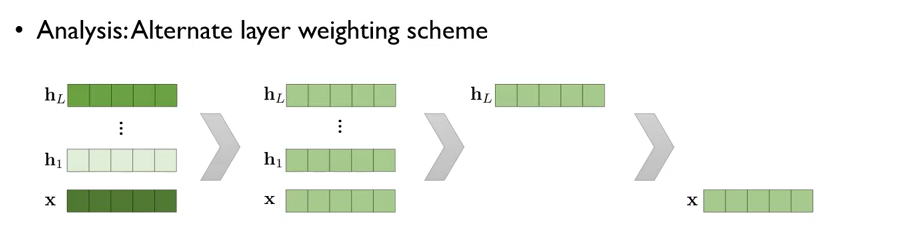
Alternate layer weighting scheme
이 layer를 어떻게 가중합을 하는 게 좋으냐 라는 질문이 던져졌을 때 논문에서는 다음의 그림과 같이 답하였다.
위의 그림을 해석해보면 첫 번째로는 task에 따라서 가중치 값을 다르게 주는 것이 가장 성능이 좋고, 그다음으로는 모든 벡터들에 대해 똑같은 가중치를 주는 것이 성능이 좋았고, 그다음으로는 제일 높은 레벨의 벡터에 가중치를 주는 것이 나았다.
Where to include ELMo?
ELMo를 어디에 집어넣는 것이 더 좋을지에 대한 질문에 대한 답이다. 다음 그림과 같이 답하였다. 다음 그림은 LM이 아닌 downstream task에 해당하는 모델이다.
위의 그림을 해석해보면 Input 값과 Output 값에 ELMo를 사용하는 것이 가장 성능이 좋았고, 그 다음으로는 Input에만 사용하는 것이, 그다음에는 Output 값에만 사용하는 것이 성능이 좋았다.
출처
https://arxiv.org/abs/1802.05365
Deep contextualized word representations
We introduce a new type of deep contextualized word representation that models both (1) complex characteristics of word use (e.g., syntax and semantics), and (2) how these uses vary across linguistic contexts (i.e., to model polysemy). Our word vectors are
arxiv.org
https://www.youtube.com/watch?v=zV8kIUwH32M
https://jalammar.github.io/illustrated-bert/
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
Discussions: Hacker News (98 points, 19 comments), Reddit r/MachineLearning (164 points, 20 comments) Translations: Chinese (Simplified), French 1, French 2, Japanese, Korean, Persian, Russian, Spanish 2021 Update: I created this brief and highly accessibl
jalammar.github.io