
Pre-trained Language Modeling paper reading
요즘 NLP 분야에서 뜨거운 감자인 pre-trained Language Modeling에 관한 유명한 논문들을 읽고 리뷰를 하였다. 이 Pre-trained Language Modeling paper reading은 이 포스트만으로 끝나는 것이 아니라 연속된 포스트를 작성할 생각이다. 이번 포스트에서는 저번 포스트의 BERT에 이어서 GPT-1에 대해서 리뷰하였다.
- ELMo: 'Deep contextualized word representations' reading & review
- BERT: 'Pre-training of Deep Bidirectional Transformers for Language Understanding' reading & review
- GPT-1: 'Improving Language Understanding by Generative Pre-Training' reading & review(this post)
Table of Contents
1. Introduction
2. GPT-1
2-1. Unsupervised pre-training
2-2. Supervised fine-tuning
2-3. Task specific input transformations
3. Analysis
1. Introduction
세상에는 labeling이 되지 않은 데이터는 풍부하지만, 라벨링이 되어 있는 데이터는 매우 부족하다. 이러한 점이 모델을 구별되게 학습시켜서 적합한 성능을 내게 하는 것에 어려움을 주고 있다. 논문에서는 이러한 문제점을 해결하기 위해 다양한 라벨링이 되지 않은 corpus에 대해 generative pre-training을 진행하고, 각각의 task에 대해 discriminative fine-tuning을 진행하였다.
learn from raw text
raw text에 대해서 효과적으로 학습을 하는 능력은 NLP에서 지도학습에 대한 의존도를 완화시킬 수 있다. 대부분의 딥러닝 methods는 많은 양의 라벨링이 되어 있는 데이터를 이용하여 학습을 하게 되는데, 이는 이 methods의 가용성(다양한 task들을 해결할 수 있는 능력)을 떨어뜨리게 한다. 이러한 상황에서 라벨링이 되지 않은 데이터의 linguistic information을 활용할 수 있는 모델은 더 많은 annotation을 수집하는 데 유용한 대안을 제공한다. 추가적으로 supervision이 가능하다면, 비지도적으로 좋은 language representation을 학습하게 되면 성능을 더 향상시킬 수 있다.
leveraging problem
라벨링이 되어 있지 않은 text에 대해서 word-level 이상의 정보 활용은 다음의 두 가지 이유로 인해 상당히 어렵다.
- 아직 어떤 optimization이 번역에 useful한 text representation을 학습하는 데에 가장 효율적인지 잘 모른다.
- 학습된 representation을 target task로 번역하는 것에 대해 가장 효과적인 방법인지에 대한 합의가 없다.
이러한 불확실성이 language processing을 위한 효과적인 준지도학습 방법에 대한 발전을 가로막는다.
semi-supervised learning approach
이 논문에서는 비지도 pre-training과 지도 fine-tuning을 합쳐서 준지도학습 방법으로 language understanding에 사용하였다. 논문의 목표는 광범위한 representation을 학습시켜서 조금의 adaptation만으로 광범위한 tasks에 대해 번역을 진행할 수 있도록 만드는 것이다. 논문에서는 라벨링이되지 않은 텍스트의 대규모 corpus와 수동으로 annotation이 달린 훈련 예제(target tasks)가 있는 여러 데이터 세트에 대한 액세스를 가정한다. 논문의 설정에서는 이러한 target tasks가 라벨링이되지 않은 corpus와 동일한 도메인에 있을 필요가 없다. 논문에서는 다음과 같은 2-stage 학습 방식을 채택하였다.
- 라벨링이 되지 않은 데이터에 대하여 LM을 사용하여 신경망 모델의 초기 parameters를 학습시켰다.
- 이 학습된 parameters를 지도학습을 사용하여 target task에 적용하였다.
moder architecture
모델의 architecture을 위해 Transformer을 사용하였다. Transformer을 사용함으로써 text에 대해 더 long-term dependency하기 위한 structured된 memory를 제공하였다. 번역을 진행하는 중에 traversal-style로부터 유래된 task-specific한 input adaptation을 활용하였다. traversla-style은 structured text input을 하나의 연속된 토큰 시퀀스로 나누는 것을 말한다. 이러한 방법은 pre-trined model의 architecture에 조금의 변화만으로 효과적으로 fine-tune 할 수 있도록 도와줬다.
2. GPT-1
학습 과정은 두 개의 stage로 이루어져있다. 첫 번째 스테이지에서는 대량의 큰 text corpus에 대해서 high-capacity language model을 학습한다. 두 번째 스테이지에서는 model을 각각의 task에 대해서 라벨링된 데이터와 함께 적용하는 fine-tuning을 진행한다.
2-1. Unsupervised pre-training
학습되지 않은 corpus인 U = {u_1, u_2, ... , u_n} 이 주어졌을 때, 표준 language modeling 목표를 사용하여 다음과 같이 가능성을 최대화하였다.

위의 수식에서 k는 context windows의 크기이고, 조건부 확률 P는 신경망과 parameter Θ 를 활용하여 modeling 된다. 이 파라미터들은 SGD(Stochastic Gradient Descent) 을 이용하여 학습된다. 위의 식을 풀어서 설명하면 u_i 이전의 단어들을 가지고 u_i번째 단어를 예측하는 것을 최대화하는 수식이라고 할 수 있다.
논문에서는 multi-layer Transformer Decoder을 language modeling을 위하여 사용하였다. 이 말인 즉슨, GPT-1은 Transformer의 Decoder을 쭈욱 올려쌓아서 language modeling을 진행한다고 할 수 있다. 이 모델은 대상 token에 대한 출력 분포를 생성하기 위해 위치별 feed-forward layer가 뒤따르는 input context token에 대해 multi-headed self-attention을 적용한다.
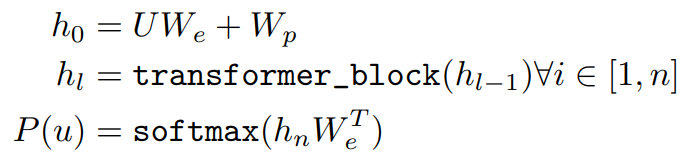
위의 수식은 transformer block들 에서의 hidden state들을 계산하는 방식을 보여주고 있다. 여기서 h_l은 l번째 hidden state의 값으로 transformer block에 l-1 번째의 hidden state인 h_l-1의 값을 집어넣었을 때 구할 수 있다. U = (u_-k, ..., u_-1)은 token들의 context vector이고, n은 layer의 개수이고, W_e는 token embedding matrix, W_p는 position embedding matrix이다.
GPT-1에서 사용하는 Transformer의 decoder는 Masked self-attention과 Feed Forward Neural Network로 구성되어 있다.
2-2. Supervised fine-tuning
위의 수식 1에서 처럼 훈련을 마치고, parameters를 supervised target task에 적용하였다. 논문에서는 라벨링이 되어 있는 데이터셋 C를 가정한다. 여기서 각각의 instance는 label y와 함께 input tokens의 시퀀스인 x^1, ..., x^m으로 구성되어 있다. 입력값들은 pre-trained odel을 거쳐가면서 마지막 transformer block의 activation인 h^l_m 을 얻게 된다. 그 다음에 이것은 파라미터 W_y와 함께 y를 예측하기 위해 linear output layer에 넣어지게 된다. 이 수식은 다음과 같다. 다음의 수식 3을 해석하면 m 개의 토큰 시퀀스가 주어졌을 때, y를 예측하는 방법은 GPT의 unsupervised pre-training의 마지막 hidden state 값을 가지고 와서 linear layer를 씌운 다음에 softmax를 거쳐서 확률값을 계산한다.

이것은 maximaize를 위해 다음과 같은 목표를 제공한다. 따라서 다음의 수식 4는 주어진 m 개의 토큰 시퀀스에 대해서 y를 예측하는 확률값을 최대화 시키는 수식이다.

논문에서는 또한 fine-tuning의 보조 목표로 language modeling을 포함하는 것이 다음의 두 장점을 가져온다고 말한다. (a) supervised model의 일반화를 개선 (b) 수렴을 가속화함으로써 학습에 도움이 된다는 것을 발견했다. 구체적으로 논문에서는 다음의 목적 함수를 optimize하였다. (λ는 가중치 값)

위의 수식을 살펴보면 이전의 unsupervised pre-training에서 진행한 학습되지 않은 corpus에 대해 표준 LM을 이용하여 likelihood를 최대화한 값인 L_1(C)에 가중치인 λ를 곱한 값과 이 절에서 구했던 L_2를 더하여 L_3(C)을 구하였다.
전반적으로 fine-tuning과정에서는 W_y와 embedding을 위한 delimiter token(2-3에서 더욱 자세히 설명)을 요구로 한다.
2-3. Task-specific input transformers
GPT의 pre-trained model은 연속적인 text의 시퀀스를 이용하여 학습되었기 때문에, 적은 수정으로도 이것을 여러 task에 적용할 수 있다. 논문에서는 structured input을 pre-trained model이 처리할 수 있는 순서화된 시퀀스로 변환하는 traversal-style을 사용한다. 이러한 input의 변형은 architecture의 구조를 크게 바꾸지 않고 할 수 있게 한다. 다음의 그림 1은 이러한 input representation의 변형에 대해 시각화로 보여주고 있다.
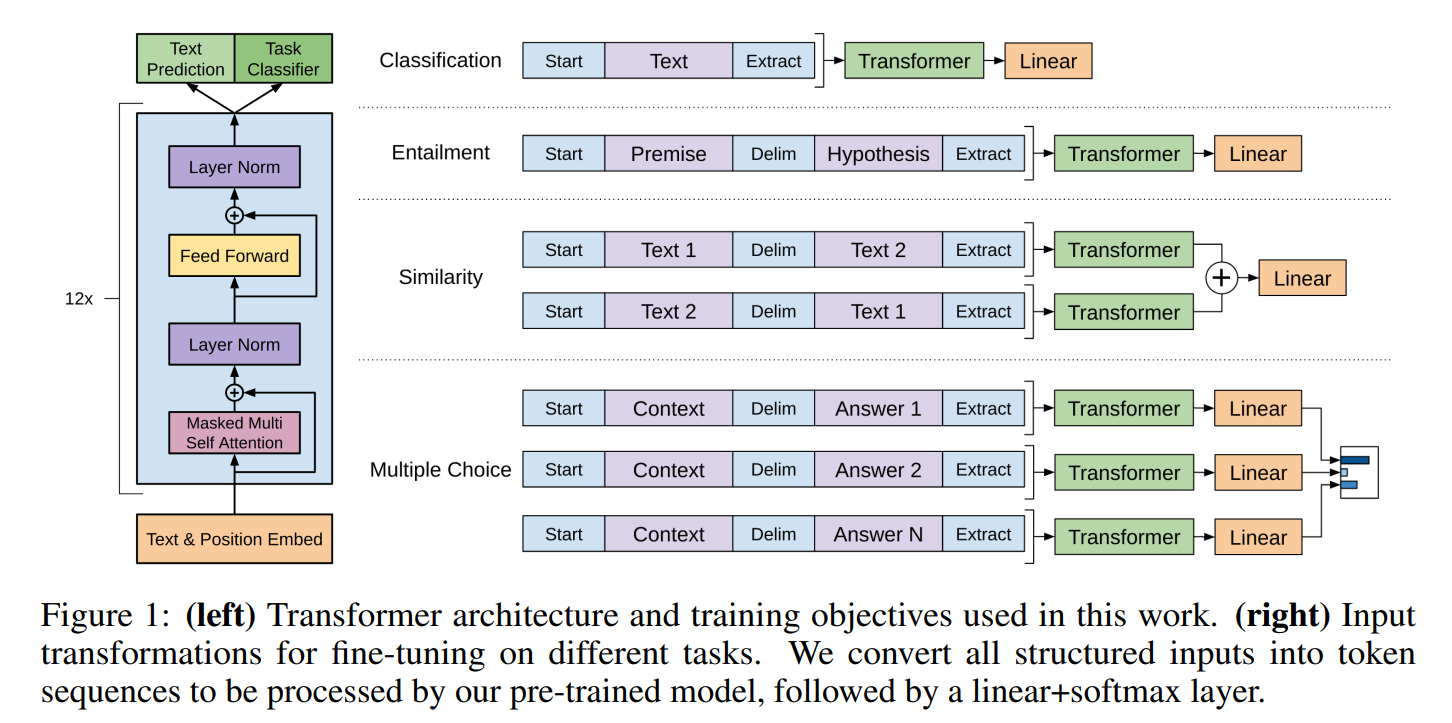
- Textual entailment: entailment task에 대해서 전제 토큰 시퀀스인 p와 가설 토크 시퀀스인 h을 delimiter token인 $사이에 넣어서 합쳤다.
- Similarity: similarity task에 대해서 비교되는 두 문장의 고유한 순서는 없다. 이를 반영하기 위해 입력 시퀀스를 수정하여 가능한 문장 순서(사이에 구분 기호 포함)를 모두 포함하고 linear output layer에 공급되기 전에 요소별로 추가되는 두 시퀀스 representation인 h^m_l을 생성하기 위해 각각을 독립적으로 처리한다.
- QA & Commonsense Reasoning: 이 task를 위해 논문에서는 context document인 z, question인 q, 가능한 대답들의 모임인 {a_k}를 주었다. 그 다음에 document context와 question을 각각의 가능한 대답들에 대해서 합치고, 그 사이에 delimiter token을 추가해서 [z; q; $; a_k]를 얻게 됐다. 각각의 시퀀스들은 model과 독립적으로 진행되고, 가능한 대답들에 대해 출력 분포를 산출하기 위해 softmax layer을 이용하여 일반화되었다.
3. Analysis
Impact of number of layers transferred
논문에서는 다양한 수의 layer를 전달시키는 것의 효과를 unsupervised pre-training으로 부터 supervised target task에 대해 직접 시행해보면서 파악하였다. 아래 그림 2의 왼쪽이 논문의 방식에 대한 performance이다. 결과를 살펴보면 표준 방법은 performance를 향상시킨다는 결과가 나왔고, 각각의 transformer layer은 9% 정도의 성능 향상을 보여줬다.

Zero-shot Behaviors
논문에서는 왜 transformer을 활용한 language model의 pre-training이 효과적인지 알고 싶었다. 가설은 기본 generative model이 language modeling 기능을 향상시키기 위해 논문이 평가하는 많은 tasks를 수행하는 방법을 배우고 변환기의 더 구조화된 attention 메모리가 LSTM과 비교하여 transfer을 더 지원한다는 것이다. 논문에서는 generative pre-training에 대한 이런 heuristic적 solution의 효과를 위 그림 2의 오른쪽에 시각화하였다. 그림을 살펴보면 이러한 heuristic적 solution의 performance는 훈련을 거치면서 안정적이고 꾸준하게 상승하고 있는 것을 알 수 있는데, 이는 generative pretraining이 다양한 범위의 작업 관련 기능에 대해 학습하는 것을 지원하고 있다고 제안할 수 있게 된다. 논문은 또한 LSTM이 Transformer architecture의 inductive bias가 전송에 도움이 된다는 것을 암시하는 zero-shot performance에서 더 높은 변동을 나타내는 것을 관찰했다.
출처
https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
https://www.youtube.com/watch?v=o_Wl29aW5XM
'Paper Reading 📜 > Natural Language Processing' 카테고리의 다른 글
Pre-trained Language Modeling paper reading
요즘 NLP 분야에서 뜨거운 감자인 pre-trained Language Modeling에 관한 유명한 논문들을 읽고 리뷰를 하였다. 이 Pre-trained Language Modeling paper reading은 이 포스트만으로 끝나는 것이 아니라 연속된 포스트를 작성할 생각이다. 이번 포스트에서는 저번 포스트의 BERT에 이어서 GPT-1에 대해서 리뷰하였다.
- ELMo: 'Deep contextualized word representations' reading & review
- BERT: 'Pre-training of Deep Bidirectional Transformers for Language Understanding' reading & review
- GPT-1: 'Improving Language Understanding by Generative Pre-Training' reading & review(this post)
Table of Contents
1. Introduction
2. GPT-1
2-1. Unsupervised pre-training
2-2. Supervised fine-tuning
2-3. Task specific input transformations
3. Analysis
1. Introduction
세상에는 labeling이 되지 않은 데이터는 풍부하지만, 라벨링이 되어 있는 데이터는 매우 부족하다. 이러한 점이 모델을 구별되게 학습시켜서 적합한 성능을 내게 하는 것에 어려움을 주고 있다. 논문에서는 이러한 문제점을 해결하기 위해 다양한 라벨링이 되지 않은 corpus에 대해 generative pre-training을 진행하고, 각각의 task에 대해 discriminative fine-tuning을 진행하였다.
learn from raw text
raw text에 대해서 효과적으로 학습을 하는 능력은 NLP에서 지도학습에 대한 의존도를 완화시킬 수 있다. 대부분의 딥러닝 methods는 많은 양의 라벨링이 되어 있는 데이터를 이용하여 학습을 하게 되는데, 이는 이 methods의 가용성(다양한 task들을 해결할 수 있는 능력)을 떨어뜨리게 한다. 이러한 상황에서 라벨링이 되지 않은 데이터의 linguistic information을 활용할 수 있는 모델은 더 많은 annotation을 수집하는 데 유용한 대안을 제공한다. 추가적으로 supervision이 가능하다면, 비지도적으로 좋은 language representation을 학습하게 되면 성능을 더 향상시킬 수 있다.
leveraging problem
라벨링이 되어 있지 않은 text에 대해서 word-level 이상의 정보 활용은 다음의 두 가지 이유로 인해 상당히 어렵다.
- 아직 어떤 optimization이 번역에 useful한 text representation을 학습하는 데에 가장 효율적인지 잘 모른다.
- 학습된 representation을 target task로 번역하는 것에 대해 가장 효과적인 방법인지에 대한 합의가 없다.
이러한 불확실성이 language processing을 위한 효과적인 준지도학습 방법에 대한 발전을 가로막는다.
semi-supervised learning approach
이 논문에서는 비지도 pre-training과 지도 fine-tuning을 합쳐서 준지도학습 방법으로 language understanding에 사용하였다. 논문의 목표는 광범위한 representation을 학습시켜서 조금의 adaptation만으로 광범위한 tasks에 대해 번역을 진행할 수 있도록 만드는 것이다. 논문에서는 라벨링이되지 않은 텍스트의 대규모 corpus와 수동으로 annotation이 달린 훈련 예제(target tasks)가 있는 여러 데이터 세트에 대한 액세스를 가정한다. 논문의 설정에서는 이러한 target tasks가 라벨링이되지 않은 corpus와 동일한 도메인에 있을 필요가 없다. 논문에서는 다음과 같은 2-stage 학습 방식을 채택하였다.
- 라벨링이 되지 않은 데이터에 대하여 LM을 사용하여 신경망 모델의 초기 parameters를 학습시켰다.
- 이 학습된 parameters를 지도학습을 사용하여 target task에 적용하였다.
moder architecture
모델의 architecture을 위해 Transformer을 사용하였다. Transformer을 사용함으로써 text에 대해 더 long-term dependency하기 위한 structured된 memory를 제공하였다. 번역을 진행하는 중에 traversal-style로부터 유래된 task-specific한 input adaptation을 활용하였다. traversla-style은 structured text input을 하나의 연속된 토큰 시퀀스로 나누는 것을 말한다. 이러한 방법은 pre-trined model의 architecture에 조금의 변화만으로 효과적으로 fine-tune 할 수 있도록 도와줬다.
2. GPT-1
학습 과정은 두 개의 stage로 이루어져있다. 첫 번째 스테이지에서는 대량의 큰 text corpus에 대해서 high-capacity language model을 학습한다. 두 번째 스테이지에서는 model을 각각의 task에 대해서 라벨링된 데이터와 함께 적용하는 fine-tuning을 진행한다.
2-1. Unsupervised pre-training
학습되지 않은 corpus인 U = {u_1, u_2, ... , u_n} 이 주어졌을 때, 표준 language modeling 목표를 사용하여 다음과 같이 가능성을 최대화하였다.
위의 수식에서 k는 context windows의 크기이고, 조건부 확률 P는 신경망과 parameter Θ 를 활용하여 modeling 된다. 이 파라미터들은 SGD(Stochastic Gradient Descent) 을 이용하여 학습된다. 위의 식을 풀어서 설명하면 u_i 이전의 단어들을 가지고 u_i번째 단어를 예측하는 것을 최대화하는 수식이라고 할 수 있다.
논문에서는 multi-layer Transformer Decoder을 language modeling을 위하여 사용하였다. 이 말인 즉슨, GPT-1은 Transformer의 Decoder을 쭈욱 올려쌓아서 language modeling을 진행한다고 할 수 있다. 이 모델은 대상 token에 대한 출력 분포를 생성하기 위해 위치별 feed-forward layer가 뒤따르는 input context token에 대해 multi-headed self-attention을 적용한다.
위의 수식은 transformer block들 에서의 hidden state들을 계산하는 방식을 보여주고 있다. 여기서 h_l은 l번째 hidden state의 값으로 transformer block에 l-1 번째의 hidden state인 h_l-1의 값을 집어넣었을 때 구할 수 있다. U = (u_-k, ..., u_-1)은 token들의 context vector이고, n은 layer의 개수이고, W_e는 token embedding matrix, W_p는 position embedding matrix이다.
GPT-1에서 사용하는 Transformer의 decoder는 Masked self-attention과 Feed Forward Neural Network로 구성되어 있다.
2-2. Supervised fine-tuning
위의 수식 1에서 처럼 훈련을 마치고, parameters를 supervised target task에 적용하였다. 논문에서는 라벨링이 되어 있는 데이터셋 C를 가정한다. 여기서 각각의 instance는 label y와 함께 input tokens의 시퀀스인 x^1, ..., x^m으로 구성되어 있다. 입력값들은 pre-trained odel을 거쳐가면서 마지막 transformer block의 activation인 h^l_m 을 얻게 된다. 그 다음에 이것은 파라미터 W_y와 함께 y를 예측하기 위해 linear output layer에 넣어지게 된다. 이 수식은 다음과 같다. 다음의 수식 3을 해석하면 m 개의 토큰 시퀀스가 주어졌을 때, y를 예측하는 방법은 GPT의 unsupervised pre-training의 마지막 hidden state 값을 가지고 와서 linear layer를 씌운 다음에 softmax를 거쳐서 확률값을 계산한다.
이것은 maximaize를 위해 다음과 같은 목표를 제공한다. 따라서 다음의 수식 4는 주어진 m 개의 토큰 시퀀스에 대해서 y를 예측하는 확률값을 최대화 시키는 수식이다.
논문에서는 또한 fine-tuning의 보조 목표로 language modeling을 포함하는 것이 다음의 두 장점을 가져온다고 말한다. (a) supervised model의 일반화를 개선 (b) 수렴을 가속화함으로써 학습에 도움이 된다는 것을 발견했다. 구체적으로 논문에서는 다음의 목적 함수를 optimize하였다. (λ는 가중치 값)
위의 수식을 살펴보면 이전의 unsupervised pre-training에서 진행한 학습되지 않은 corpus에 대해 표준 LM을 이용하여 likelihood를 최대화한 값인 L_1(C)에 가중치인 λ를 곱한 값과 이 절에서 구했던 L_2를 더하여 L_3(C)을 구하였다.
전반적으로 fine-tuning과정에서는 W_y와 embedding을 위한 delimiter token(2-3에서 더욱 자세히 설명)을 요구로 한다.
2-3. Task-specific input transformers
GPT의 pre-trained model은 연속적인 text의 시퀀스를 이용하여 학습되었기 때문에, 적은 수정으로도 이것을 여러 task에 적용할 수 있다. 논문에서는 structured input을 pre-trained model이 처리할 수 있는 순서화된 시퀀스로 변환하는 traversal-style을 사용한다. 이러한 input의 변형은 architecture의 구조를 크게 바꾸지 않고 할 수 있게 한다. 다음의 그림 1은 이러한 input representation의 변형에 대해 시각화로 보여주고 있다.
- Textual entailment: entailment task에 대해서 전제 토큰 시퀀스인 p와 가설 토크 시퀀스인 h을 delimiter token인 $사이에 넣어서 합쳤다.
- Similarity: similarity task에 대해서 비교되는 두 문장의 고유한 순서는 없다. 이를 반영하기 위해 입력 시퀀스를 수정하여 가능한 문장 순서(사이에 구분 기호 포함)를 모두 포함하고 linear output layer에 공급되기 전에 요소별로 추가되는 두 시퀀스 representation인 h^m_l을 생성하기 위해 각각을 독립적으로 처리한다.
- QA & Commonsense Reasoning: 이 task를 위해 논문에서는 context document인 z, question인 q, 가능한 대답들의 모임인 {a_k}를 주었다. 그 다음에 document context와 question을 각각의 가능한 대답들에 대해서 합치고, 그 사이에 delimiter token을 추가해서 [z; q; $; a_k]를 얻게 됐다. 각각의 시퀀스들은 model과 독립적으로 진행되고, 가능한 대답들에 대해 출력 분포를 산출하기 위해 softmax layer을 이용하여 일반화되었다.
3. Analysis
Impact of number of layers transferred
논문에서는 다양한 수의 layer를 전달시키는 것의 효과를 unsupervised pre-training으로 부터 supervised target task에 대해 직접 시행해보면서 파악하였다. 아래 그림 2의 왼쪽이 논문의 방식에 대한 performance이다. 결과를 살펴보면 표준 방법은 performance를 향상시킨다는 결과가 나왔고, 각각의 transformer layer은 9% 정도의 성능 향상을 보여줬다.
Zero-shot Behaviors
논문에서는 왜 transformer을 활용한 language model의 pre-training이 효과적인지 알고 싶었다. 가설은 기본 generative model이 language modeling 기능을 향상시키기 위해 논문이 평가하는 많은 tasks를 수행하는 방법을 배우고 변환기의 더 구조화된 attention 메모리가 LSTM과 비교하여 transfer을 더 지원한다는 것이다. 논문에서는 generative pre-training에 대한 이런 heuristic적 solution의 효과를 위 그림 2의 오른쪽에 시각화하였다. 그림을 살펴보면 이러한 heuristic적 solution의 performance는 훈련을 거치면서 안정적이고 꾸준하게 상승하고 있는 것을 알 수 있는데, 이는 generative pretraining이 다양한 범위의 작업 관련 기능에 대해 학습하는 것을 지원하고 있다고 제안할 수 있게 된다. 논문은 또한 LSTM이 Transformer architecture의 inductive bias가 전송에 도움이 된다는 것을 암시하는 zero-shot performance에서 더 높은 변동을 나타내는 것을 관찰했다.
출처
https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
https://www.youtube.com/watch?v=o_Wl29aW5XM