
The overview of this paper
Transformer는 매우 강력한 sequence model이지만, sequence의 길이에 따라서 시간과 메모리가 곱절로 필요하다는 단점이 있다. 이 논문에서는 attention 행렬의 sparse factorization을 소개하였는데, 이는 Transformer의 시간 복잡도를 $O(n \sqrt{n})$으로 줄였다. 또한 논문에서는 다음의 내용들을 소개하였다.
- 더욱 깊은 네트워크를 학습시키기 위해 모델의 구조와 초기화에 변동을 주었음.
- attention 행렬의 재계산으로 메모리를 아낌.
- 학습을 위해 fast attention을 사용함.
이러한 변화를 준 모델을 Sparse Transformer라고 부르기로 했다. 이 모델은 수백개의 레이어를 사용해서 수만 개의 시퀀스를 모델링할 수 있음을 보여줬다. 그리고 똑같은 모델을 사용하여 이미지, 오디오, 텍스트를 모델링하였다. 논문에서는 글로벌 일관성과 다양성을 입증하는 unconditional sample을 생성하고 길이가 100만 이상인 모델 시퀀스에 self-attention을 사용하는 것이 가능함을 보여줬다.
Table of Contents
1. Introduction
2. Background
3. Factorized Self-Attention
3-1. Qualitative assessment of learned attention patterns
3-2. Factorized self-attention
3-3. Two-dimensional factorized attention
4. Sparse Transformer
4-1. Factorized attention heads
4-2. Scaling to hundreds of layers
4-3. Modeling diverse data types
4-4. Saving memory by recomputing attention weights
4-5. Mixed-precision training
5. Training
6. Experiments
1. Introduction
복잡하고, 고차원의 데이터 분포를 측정하는 것은 unsupervised learning에서 중심 문제이다. 추가적으로 이것은 unsupervised representation learning의 중요한 요소라고 여겨진다. neural autoregressive 방식은 결합 확률 분포를 조건부 분포의 곱으로 분해한다. 이러한 조건부 분포를 모델링하는 것은 매우 어렵지만, 그만큼 이 분포는 복잡하고, long-range dependencies하고, 학습하기 위해 적절한 expressive model을 필요로 한다.
별도로, Transformer는 여러 NLP task에서 뛰어난 성능을 보여주고 있고, 이는 부분적으로 일정한 수의 레이어에서 임의의 종속성을 모델링하는 기능 때문일 수 있다. 각각의 self-attention 레이어가 global receptive 필드를 가지고 있는 것처럼, 네트워크는 representational 수용력을 입력 영역의 가장 유용한 부분에 할당할 수 있다. 따라서 architecture는 고정된 연결 패턴을 가지고 있는 네트워크보다 더욱 유연하게 다양한 유형의 데이터를 생성할 수 있었던 걸 수도 있다.
하지만, Transformer가 필요로 하는 메모리와 계산량은 sequence의 길이에 따라서 곱절로 늘어난다. 따라서 Transformer는 긴 sequence를 사용하는 것을 배제한다.
이 논문의 주된 contribution은 성능의 저하 없이 sequence 길이에 따라 시간 복잡도 $O(n \sqrt[p]{n})$을 가지는 attnetion 행렬의 여러 sparse factorization을 소개했다는 것이다. 이러한 작업들은 full attention 계산을 여러 개의 faster attention으로 분리하여 작동하며, 결합 될 시에 dense attention 연산에 근접할 수 있다. 논문에서는 이를 사용하여 길이를 모르는 sequence에 self-attention을 적용하였다.
추가적으로 논문에서는 Transformer에 다음의 여러 변화들을 가하였다.
- residual block & 가중치 초기화 재구조화
- sparse attention kernel은 attention 행렬의 서브셋을 효율적으로 계산함
- backward pass일 때, attention 가중치를 재계산해서 메모리의 사용량을 줄였음.
논문에서는 모델이 이런 방식으로 증강된 모델이 자연어, 오디오, 이미지의 생성과 압축에서 SOTA를 달성할 수 있음을 실험적으로 검증하였다. architecture의 단순성으로 인해 많은 task에 대해서 유용할 것이라고 생각하게 만든다.
2. Background
논문에서는 autoregressive sequence 생성의 task를 고려하였다. 여기서 sequence $x = {x_1, x_2, \cdots, x_n}$의 결합 조건부 확률은 조건부 확률 분포의 곱으로 모델링 되었고, 네트워크 $\theta$에 의해서 파라미터화 되었다.
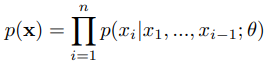
이미지, 텍스트, 오디오를 별개의 토큰처럼 다루어야 한다. 네트워크 $\theta$는 token의 sequence를 입력으로 받아서 next token으로 가능한 $v$값들의 범주 분포를 출력한다. 여기서 $v$는 vocabulary의 크기이다. 훈련 목표는 데이터의 로그 확률을 $\theta$에 관하여 극대화시키는 것이다.
모델 $\theta$에 대한 간단하고 강력한 선택은 decoder-only Transformer이다. 이러한 모델은 전체 시퀀스에 대한 multihead self-attention 블록을 사용하여 입력 시퀀스를 변환한 다음에 각 시퀀스 요소에 대한 조밀한 변환을 수행한다. 네트워크의 self-attention 부분은 각 $n$ 요소에 대해 $n$ 가중치를 계산해야 하지만, 시퀀스의 길이가 늘어남에 따라 빠르게 다루기 어려워진다.
다음 섹션에서는 Transformer architecture을 긴 sequence에 적절하게 모델링할 수 있도록 가해진 변화에 대해 설명하겠다.
3. Factorized Self-Attention
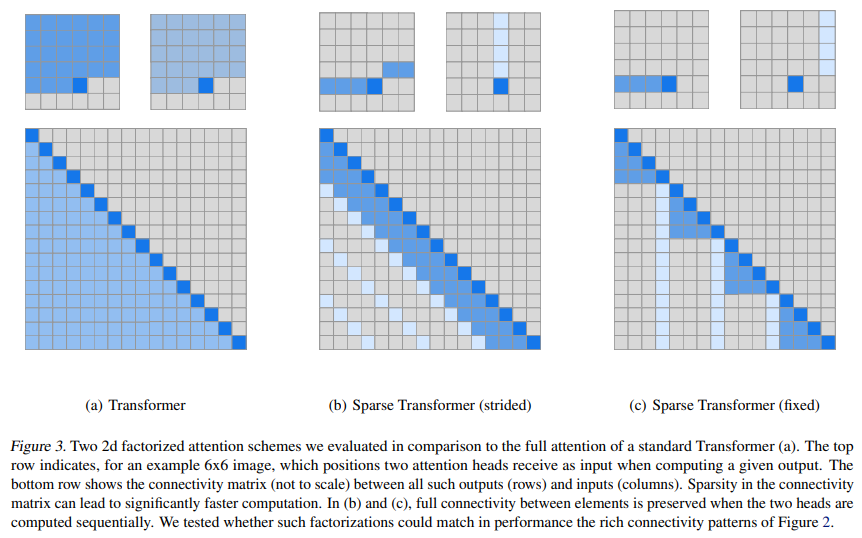
Sparse Transformer는 full self-attention 연산을 다음 그림 1의 b와 c처럼 여러 단계의 attention으로 나누었다.
3-1. Qualitative assessment of learned attention patterns
다음의 그림 2에 128-layer self-attention 네트워크로 학습된 attention 패턴을 CIFAR-10에 표현하였다. 시각적 검사는 대부분의 레이어가 대부분의 데이터 포인트에서 sparse attention 패턴을 가지는 것을 보여줬다. 이는 성능에 큰 영향을 미치지 않고 어떤 형태의 sparsity가 도입될 수 있음을 보여준다. 그림 2의 c에서 몇 개의 레이어는 명확하게 global 패턴을 보여주었고, 그림 2의 d는 데이터 의존적인 sparsity를 보여줬다. 그리고 이 둘은 모든 attention 행렬에 미리 결정된 sparsity 패턴을 도입함으로써 영향을 받는다.

3-2. Factorized self-attention
self-attention 레이어는 입력 임베딩 $X$의 행렬을 출력 행렬로 매핑하고, 연결 패턴 $S = {S_1, \cdots, S_n}$에 의해 파라미터화 된다. 여기서 $S_i$는 $i$번째 출력 벡터가 참조하는 입력 벡터의 인덱스 집합을 나타낸다. 출력 벡터는 변형 입력 벡터의 가중합이다.
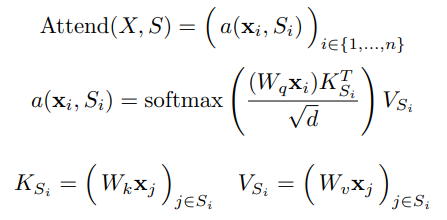
여기서 $W_q, W_k, W_v$는 각각 $\mathbf{x}_i$가 주어지면 query, key, value로 변환하는 가중치 행렬을 나타낸다. 그리고 여기서 $d$는 query와 key의 내부 차원이다. 각 포지션에서의 출력은 key와 query의 scaled dot-product에 의해 가중치가 부여된 값의 합계이다.
autoregressive model을 위한 full self-attetnion은 $S_i = {j: j \leq i}$을 정의해서 모든 원소들이 지언의 모든 포지션과 자기 자신의 포지션을 참조할 수 있게 해준다.
factorized self-attention은 대신에 separate attention head $p$를 가진다. 여기서 $m$ 번째 head는 인덱스 $A_{i}^{(m)} \subset {j : j \leq i}$의 서브셋을 정의하고 $S_i = A_{i}^{(m)}$을 허용해준다. 논문에서는 주로 서브셋 $A$에 대한 효율적인 선택에 관심이 있다. 여기서 $|A_{i}^{(m)}| \propto \sqrt[p]{n}$이다.
또한 당분간 모든 입력 위치가 attention의 $p$단계에 걸쳐 모든 미래 출력 위치에 연결되는 $A$의 유효한 선택을 고려한다.
모든 $j \leq i$ 쌍에 대하여, 논문에서는 최대 길이가 $p + 1$인 위치의 경로를 통해 $i$가 $j$를 참조할 수 있도록 모든 $A$를 설정하였다. 특히 $(j, a, b, c, \cdots, i)$가 인덱스들의 경로이면 $j \in A_{a}^{(1)}, a \in A_{b}^{(2)}, b \in A_{c}^{(3)}$이다.
이러한 두 개의 기준은 Transformer가 일정한 수의 단계에서 임의의 입력 포지션으로부터 임의의 출력 포지션으로 신호를 전파할 수 있도록 하는 능력을 유지할 수 있게 해주면서 총 계산량을 $O(n \sqrt[p]{n})$으로 줄여줬다. 논문에서는 타당성 기준을 누그러뜨리는 것이 특정 도메인에 대해 유용한 inductive bias가 될 수도 있다고 말하였다.
3-3. Two-dimensional factorized attention
factorized attention 패턴을 두 개의 차원으로 정의하는 자연스러운 방식은 이전 $l$ location을 참조하는 하나의 head를 가져야 하고, 다른 head는 모든 $l$번째 location을 참조해야 한다. 여기서 $l$은 stride이고 $\sqrt{n}$에 가깝게 선택되어야 한다. 이러한 방식을 strided attention이라고 부른다.
공식적으로 나타내면 $t = max(0, i-l)$에 대해 $A_{i}^{(1)} = {t, t+1, \cdots, i}$이고, $A_{i}^{(2)} = {j : (i - j) mod l = 0}$이다. 이러한 패턴은 위 그림 3의 b에 나타나있다.
이 공식은 데이터가 이미지 또는 음악같은 유형의 자연적으로 stride에 알맞은 구조를 가지고 있다면 편리하다. 텍스트 같이 주기적 구조가 없는 데이터는 네트워크가 strided 패턴을 사용하여 적절하게 정보를 보낼 수 없다. 마치 요소에 대한 공간 좌표는 요소가 미래에 가장 관련될 수 있는 포지션과 반드시 상관관계가 있는 것은 아닌 것처럼 말이다.
이러한 경우에는, fixed attention 패턴$($그림 3의 c$)$을 사용한다. 여기서 특정 셀은 이전의 location을 요약하고 이 정보를 모든 미래 셀로 전파한다.
공식적으로 나타내면 $A_{i}^{(1)} = {j : (\left \lfloor j/l \right \rfloor = \left \lfloor i/l \right \rfloor)}$인데, 여기서 괄호는 바닥 함수를 나타낸다. 그리고 $A_{i}^{(2)} = {j : j mod l \in {t, t+1, \cdots, l}}$인데, 여기서 $t = l - c$와 $c$는 하이퍼 파라미터이다.
만약 stride가 128이고 $c = 8$이면, 모든 미래 포지션은 128보다 크고 포지션 120-128을 참조할 수 있다. 만약 모든 포지션이 256보다 크면 248-256을 참조할 수 있다.
$c=1$을 사용하는 fixed-attention 패턴은 네트워크의 많은 representation들은 오직 하나의 블록에만 사용되는 반면 소수의 위치는 모든 블록에서 사용되는 것처럼 네트워크의 표현성을 상당히 제한한다. 그래서 논문에서는 보통 $l \in {128, 256}$의 값을 가질 때 $c \in {8, 16, 32}$를 사용하는 것이 적당하다고 말했다. 비록 이 방식은 strided attention에 비해 $c$에 의해 계산 비용이 증가한지만 말이다.
또한 여러 head를 사용할 때 크기 $l$의 블록 내에서 길이가 $c$인 별개의 하위 블록을 참조하도록 하는 것이 동일한 하위 블록을 참조하는 것보다 더 낫다는 것을 발견했다.
4. Sparse Transformer
4-1. Factorized attention heads
일반적인 dense attention은 앞서 attend 함수의 선형 변환을 간단하게 수행한다.
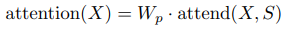
여기서 $W_p$는 post-attention 가중치 행렬을 나타낸다. factorized self-attention을 통합하는 가장 간단한 기술은 각 residual block에 하나의 attention type을 사용하고, 이들을 순차적 혹은 하이퍼파라미터에 의해 결정되는 비율로 끼워넣는 것이다.
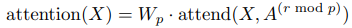
여기서 $r$은 현재 residual block의 인덱스이고 $p$는 factorized attention head의 수이다.
두 번째 방식은 하나의 head가 factorized된 두 head가 참조할 픽셀의 위치을 참조하도록 하는 것이다. 이를 merged head라고 한다.
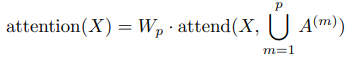
이것은 좀 더 계산 집약적이지만, 일정한 factor에 의해서만 가능하다. 세 번째 방식은 multi-head attention을 사용하는 것이다. 여기서 $n_h$ attention 곱은 병렬로 계산된 다음 feature dimension과 함께 합쳐진다.
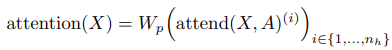
여기서 $A$는 분리된 attention 패턴, merged 패턴 혹은 attend 함수와 같이 끼워진 패턴일 수도 있다. 또한 attend 함수의 안에 있는 가중치 행렬의 차원은 $1/n_h$의 계수로 줄어들어 파라미터의 수가 $n_h$의 값에 따라 변하지 않는다. 논문에서는 일반적으로 여러 head가 잘 작동하는 것을 발견하였지만, 매우 긴 시퀀스의 경우 한 번에 하나씩 순차적으로 수행하는 것이 더 가치가 있다.
4-2. Scaling to hundreds of layers
Transformer가 여러 레이어를 사용하여 학습하는 것에 어려움이 있다는 것을 발견하였다. auxillary loss를 포함하는 대신에, 다음의 구조적 변화를 적용하였다.
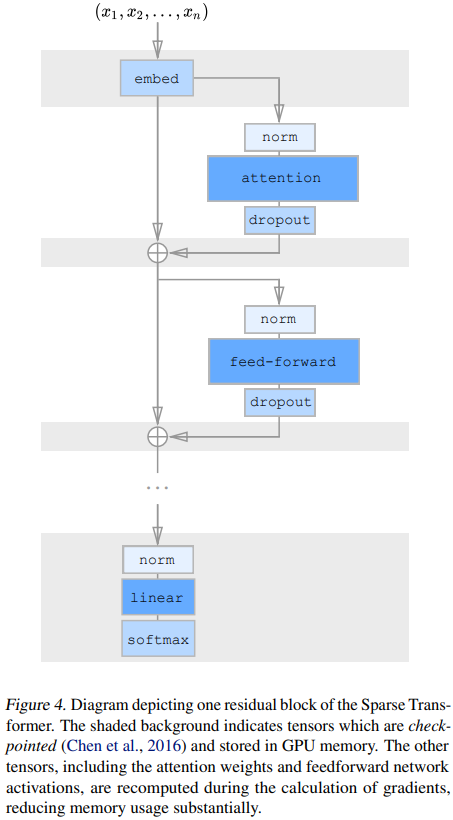
첫 번째로, 논문에서는 pre-activation residual block을 사용하였다. 그래서 $N$ 레이어의 네트워크는 다음과 같은 방법으로 정의되었다.
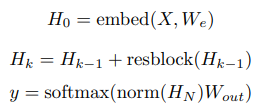
여기서 embed는 다음 섹션에서 설명한 함수이고, $W_{out}$은 가중치 행렬, $resblock(h)$는 attention 블록의 입력과 position wise feedforward 네트워크를 다음과 같은 방식으로 정규화한다.
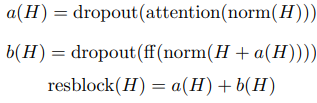
norm 함수는 layer Normalization을 나타내고, $ff(x) = W_{2}f(W_{1}x + b_{1}) + b_{2}$이다. $f$로는 Gaussian Error Linear Unit$($GELU$)$가 사용되었는데, $f(X) = X \odot sigmoid(1.702 \cdot X)$의 형식으로 사용된다. 따로 정의되어 있지 않으면 $W_{1}$의 출력 차원은 입력 차원의 4.0배이다.
$H_{N}$이 함수 $a$와 $b$의 $N$ 응용의 합이고, 따라서 각각의 함수 블록은 출력 레이어로부터 직접 기울기를 받게 된다. 논문에서는 $W_2$와 $W_{p}$의 초기화를 $\frac {1}{\sqrt{2N}}$에 의해 scale하면서 input embedding scale 대 residual block scale의 비율을 $N$ 값에 걸쳐 불변으로 유지한다.
4-3. Modeling diverse data types
input symbol의 임베딩에 더하여 positional encoding은 보통 Transformer와 다른 location-agnostic architecture에 데이터의 공간적 관계를 인코드하기 위해 사용된다. 데이터의 구조 또는 factorized attention 패턴을 인코드하는 학습된 임베딩을 사용하는 것은 모델의 성능에 매우 중요하다.
논문에서는 $n_{emb} = d_{data}$ 또는 $n_{emb} = d_{attn}$ 임베딩을 각 input location에 추가했다. 여기서 $d_{data}$는 데이터의 차원의 수이고, $d_{attn}$은 factorized attention의 차원의 수이다. 만약 $\mathbf{x}_{i}$가 시퀀스에서 $i$번째 요소의 one-hot 인코딩된 값이고, $\mathbf{o}_{i}^{(j)}$는 $j$번째 차원에서 $\mathbf{x}_{i}$의 one-hot 인코딩된 포지션을 나타낸다.
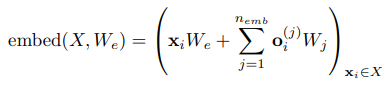
이미지에 대해서는 열과 행, 채널을 표현하기 위해 $d_{data} = 3$을 사용하고, 텍스트와 오디오에 대해서는 2차원 attention embedding을 사용해서 $d_{attn} = 2$를 사용한다.
4-4. Saving memory by recomputing attention weights
기울기를 체크포인트 해두는 것은 심층 신경망을 학습하기 위해 요구되는 메모리를 줄이는 효과적인 방법으로 보여진다. 이 기술은 딱히 효과가 없지만, 긴 시퀀스가 처리될 때 self-attention 레이어에 대해 특히 효과적이다. 이러한 레이어의 컴퓨팅 비용에 비해 메모리 사용량이 높기 때문이다.
재계산만을 혼자 사용하면 16,384의 시퀀스 길이에 수백개의 레이어를 사용하는 dense attention 네트워크를 학습시킬 수 있다. 그렇지 않으면 최신 하드웨어에서는 실행이 불가능하다.
실험에서는 backward pass 도중에 attention과 feedforward block을 재계산하였다. 시행을 간단하게 하기 위해 attention block 내에서 dropout을 적용하지 않았고, 대신에 각 residual 추가의 마지막에 적용하였다. 이는 그림 3에 나타나있다.
4-5. Mixed-precision training
논문에서는 네트워크의 가중치를 single-precision floating-point에 저장하였는데, 그렇지 않은 경우 네트워크 activation 및 기울기를 half-precision으로 계산한다. 이것은 학습을 가속화시킨다.
5. Training
모든 임베딩은 일정한 차원 $d$이고, 보통 ${256, 512, 1024}$중 하나이다. 기본적으로 모든 선형 변환은 입력을 4d로 투영하는 feedforward 네트워크를 제외하고는 동일한 차원이다. 또한, 가끔 query와 key 변환의 크기는 반으로 줄인다.
6. Experiments
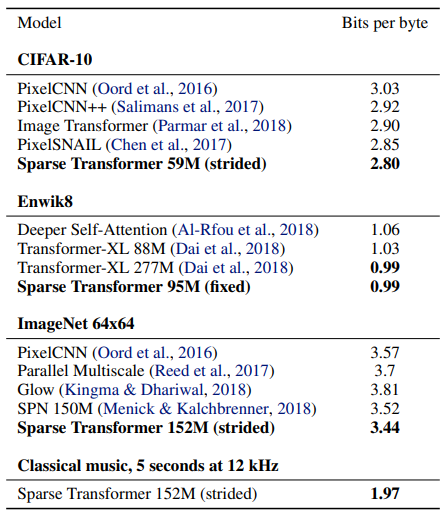
논문에서는 architecture을 이미지, 자연어, 오디오를 포함하는 density modeling task에 대해 평가하였다. 이에 대한 결과의 요약은 다음의 표 1에 나타나있다.
출처
https://arxiv.org/abs/1904.10509
Generating Long Sequences with Sparse Transformers
Transformers are powerful sequence models, but require time and memory that grows quadratically with the sequence length. In this paper we introduce sparse factorizations of the attention matrix which reduce this to $O(n \sqrt{n})$. We also introduce a) a
arxiv.org
https://sh-tsang.medium.com/review-sparse-transformer-80cbba4ebaa4
Review: Sparse Transformer
Capture Long-Sequence Attentions
sh-tsang.medium.com
'Paper Reading 📜 > Natural Language Processing' 카테고리의 다른 글
| GPT-4 Techinal Report Review (0) | 2023.03.28 |
|---|---|
| BigBird: Transformers for Longer Sequences 논문 리뷰 (0) | 2023.03.25 |
| GPT-3: Language Models are Few-Shot Learners 논문 리뷰 (0) | 2023.03.21 |
| TinyBERT: Distilling BERT for Natural Language Understanding 논문 리뷰 (0) | 2023.03.12 |
| Pre-LN Transformer: On Layer Normalization in the Transformer Architecture 논문 리뷰 (2) | 2023.03.09 |