
The overview of this paper
BERT와 같은 LM pre-training은 여러 NLP task에 대해 상당히 성능을 향상시켰다. 하지만, PLM은 보통 계산적 비용이 매우 비싸고, 그에 따라서 자원이 제한된 환경에서 실행하는데 어려움이 있다. 논문에서는 Transformer distillation method를 제안해서 추론 속도를 빠르게 하고, 모델 크기도 줄어들게 하고, 그 대신에 정확도는 유지시켰다. 이 Transformer distillation method는 Transformer 기반 모델에 대해 knowledge distillation$($KD$)$을 적용시켰다. 이를 위해 풍부한 지식을 가지고 있는 큰 'teacher' BERT에서 작은 'student' TinyBERT로 지식을 전달한다. 그리고 논문에서는 TinyBERT를 위한 two-stage learning 프레임워크를 제안하였는데, 이것은 pre-training과 task-specific learning stage에 Transformer disitllation을 수행한다. 이 프레임워크는 TinyBERT가 BERT의 general-domain뿐만 아니라 task-specific 지식 또한 캡처할 수 있도록 보장한다.
TinyBERT with 4layers는 효과적이었고, 성능적으로 teacher model보다 더 좋은 성능을 보여줬다. 무려 7.5배 작고, 9.4배 빠른 추론 속도를 보여줬다.
Table of Contents
1. Introduction
2. Method
3. Experiment Results
4. Ablation Studies
4-1. Effects of Learning Procedure
4-2. Effects of Distillation Objective
5. Effects of Mapping Function
1. Introduction
LM을 pre-training하고, downstream task에 대해 fine-tuning을 하는 것이 NLP에서 하나의 새로운 패러다임으로 부상하고 있다. 그리고 실제로 이 방법들이 NLP 분야에서 좋은 성능들을 보여주고 있다. 하지만, PLM은 보통 많은 수의 파라미터와 긴 추론 시간을 가지고 있어서, 이는 핸드폰과 같은 edge device에 적용하기 어렵다. 최근의 연구들은 PLM에 장황성이 있다는 사실을 밝혀냈다. 따라서 성능은 유지시키면서 PLM에서 계산 overhead와 모델의 저장 용량을 줄이는 것이 중요하다.
여기에는 정확도는 유지시키면서 모델의 크기는 줄이고, 모델의 추론 속도를 가속화하는 많은 모델 압축 기술들이 있다. 이 논문에서는 그 중에서도 teacher-student 프레임워크의 knowledge distillation$($KD$)$에 집중하였다. KD는 거대한 teacher network에서 작은 student network로 지식을 전달해서 teacher network의 행동을 모사한다. 이 프레임워크에 기반해서, 논문에서는 Transformer 기반의 새로운 distillation method를 제안하였다. 그리고 large-scale PLM을 위한 method를 조사하기 위한 예시로 BERT를 사용하였다.
KD는 pre-trained LM 뿐만 아니라 NLP 분야에서 광범위하게 학습하였다. pre-training-then-fine-tuning 패러다임은 large-scale의 비지도학습 text corpus에서 BERT를 학습시키고, task-specific dataset에서 fine-tuning 하였다. 이는 BERT distillation의 어려움을 굉장히 증가시켰다. 따라서, 두 개의 training stage를 위해 효과적인 KD 전략이 필요하다.
경쟁력 있는 TinyBERT를 만들기 위해, 논문에서는 새로운 Transformer Distillation method을 제안해서 teacher BERT에서 embedding된 지식을 증류하였다. 특별히, 논문에서는 BERT layer의 서로 다른 representation에 대한 3개의 loss function을 제안하였다.
- embedding layer의 output
- Transformer layer로부터 나온 hidden state와 attention 행렬
- prediction layer의 logit output
attention 기반의 fitting은 최근의 발견에 의해 영감을 받았다. 최근의 연구들을 통해 BERT에 의해 학습된 attention 가중치는 상당한 언어적 정보를 캡처할 수 있고, 따라서 teacher BERT로부터 student TinyBERT까지 언어적 정보가 잘 전달될 수 있도록 장려할 수 있다. 그래서, 논문에서는 다음의 그림 1과 같이 general distillation과 task-specific distillation을 포함하는 새로운 two-stage learning 프레임워크를 제안하였다.

general distillation의 단계에서, fine-tuning이 되지 않은 기존의 BERT는 teacher model처럼 사용된다. student TinyBERT는 general-domain corpus에 대해 제안된 Transformer distillation을 사용해서 teacher model의 특성을 흉내낸다. 그 후에, 추가적인 distillation을 위한 student model의 초기화 처럼 사용되는 general TinyBERT를 얻을 수 있다. task-specific distillation 단계에서는, 먼저 data augmentation을 수행하고, fine-tuned BERT를 teacher model처럼 사용하여 augmented dataset에 대해 distillation을 수행한다. 이는 two stage가 TinyBERT의 성능과 정규화를 향상시키는데 필수적이라는 것을 보여준다.
이 논문의 주된 contribution은 다음과 같다.
- 새로운 Transformer distillation method 제안. teacher BERT의 언어적 정보가 적절하게 TinyBERT로 전달됨.
- two-stage learning 프레임워크 제안. pre-training & fine-tuning
- ↓ parameter & ↓ 추론 시간에도 불구 준수한 성능을 보여줌.
2. Method
이 섹션에서, 논문에서는 Transformer model을 위한 새로운 distillation method를 제안하고, BERT로부터 증류된 논문의 모델에 대해 two-stage learning 프레임워크를 적용한 TinyBERT를 보여줬다.
2-1. Transformer Distillation
제안된 Transformer Distillation은 Transformer network를 위해 특별히 디자인된 KD method이다. 이 작업에서 student와 teacher network 모두는 Transformer layer로 만들어졌다. 명확한 설명을 위해 논문에서는 method를 설명하기 전에 문제부터 고안하였다.
Problem Formulation $N$개의 layer를 가진 teacher 모델과 $M$개의 layer를 가진 student 모델이 있다고 가정해보자. Transformer distillation을 위해 teacher model에서 N개 중 M개의 Transformer layer를 선택하자. 그 다음에 student layer과 teacher layer 간의 인덱스를 매핑하는 함수인 $n = g(m)$을 정의하였다. 이것은 student model의 $m$번째 layer는 teacher model의 $g(m)$번째 layer로부터 정보를 받아서 학습한다는 의미이다. 여기서 $m = 0$은 index embedding을 의미하고, $M + 1$은 prediction layer를 의미한다. 각각은 $0 = g(0)$과 $N + 1 = g(M + 1)$을 의미한다. 이를 공식화하면 student model은 teacher model로부터 다음의 식을 최소화함으로써 지식을 얻을 수 있다.

여기서 $\mathfrak{L}_{layer}$는 model layer가 주어질 때의 loss function을 뜻하고, $f_{m}(x)$는 behavior function으로 $m$번째 layer로부터 유도되었고, $\lambda_{m}$은 $m$ 번째 layer의 distillation의 중요도를 나타내는 파라미터이다.
Transformer-layer Distillation 논문에서 제안된 Transformer-layer distillation은 attention based distillation과 hidden states based distillation를 포함하고 있는데, 이게 그림 2에 나타나있다. attention based distillation은 BERT에 의해 학습된 attention 가중치가 언어적 정보를 캡처할 수 있다는 사실에 영감을 받았다. 이러한 유형의 언어적 정보는 syntax와 coreference 정보를 포함하고 있고, 이는 자연어 이해에 필수적이다. 따라서 논문에서는 언어적 정보가 teacher로부터 student로 전달되는 attention based distillation을 제안하였다. student는 teacher network의 multi-head attention 행렬을 맞추기 위해 학습되고, objective는 다음과 같이 정의된다.

여기서 $h$는 attention head의 수를 의미하고, $\textbf{A}_{i | \in \mathbb{R}^{l \times l}}$는 teacher 또는 student의 $i$번째 head에 해당하는 attention 행렬이다. $l$는 input text의 길이이고, $MSE()$는 mean squared error 손실함수이다. 이 작업에서 attention 행렬 $\textbf{A}_{i}$는 softmax 출력인 $softmax(\textbf{A}_{i})$ 대신에 fitting target으로 사용된다. 왜냐하면, 논문의 실험에서 이러한 세팅잉 더 빠르게 수렴하고 더 나은 성능을 보여준다고 보여줬기 때문이다.
그리고 attention based distillation에 대해 추가적으로 Transformer layer의 출력으로부터 나온 지식을 증류하였고, objective는 다음과 같다.
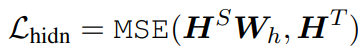
여기서 행렬 $\textbf{H}^{S} \in \mathbb{l \times d^{'}}$와 $\textbf{H}^{T} \in \mathbb{l \times d}$는 각각 student와 teacher의 hidden state를 의미하고, 이는 Transformer의 Position-wise Feed-Forward Network에 의해 계산된다. 스칼라 값인 $d$와 $d^{'}$는 teacher와 student의 hidden size를 의미하고 $d^{'}$는 보통 $d$보다 작은 값을 가지는데, 이는 더 작은 student network를 갖기 위함이다. 행렬 $\textbf{W}_{h} \in \mathbb{R}^{d^{'} \times d}$는 학습 가능한 선형 변환 함수이고, 이는 student network의 hidden state를 teacher network의 state로 똑같이 변환한다.
Embedding-layer Distillation hidden states based distillation과 비슷하게, 논문에서는 embedding-layer distillation을 수행하였고, objective는 다음과 같다.

여기서 행렬 $\textbf{E}^{S}$와 $\textbf{H}^{T}$는 각각 student와 teacher의 embedding이다. 논문에서는 이들이 hidden state 행렬처럼 똑같은 모양을 가지고 있다. 행렬 $\textbf{W}_{e}$는 $\textbf{W}_{h}$와 비슷한 역할의 선형 변환이다.
Prediction-layer Distillation 중간 레이어의 특성을 모방하기 위해, 논문에서는 teacher model의 prediction에 KD를 적용하였다. 논문에서는 student logit과 teacher logit 간에 soft cross-entropy loss를 적용하였다.

여기서 $z^{S}$와 $z^{T}$는 각각 student와 teacher에 의해 예측되는 logit vector이다. CE는 cross entropy loss를 의미하고 $t$는 temperature 값을 의미한다. 이 $t$값은 $t = 1$이 가장 적당하다.
위의 distillation objective들을 이용해서, 논문에서는 각 teacher와 student 간의 레이어에 해당하는 distillation loss를 다음과 같이 통합하였다.

2-2. TinyBERT Learning
BERT는 보통 두 개의 learning stage로 구성되어 있다: pre-training & fine-tuning. pre-training 단계에서 BERT에 의해 학습된 풍부한 지식은 매우 중요하고 압축된 모델로 전달되어야만 한다. 그래서, 논문에서는 general distillation과 task-specific distillation을 포함하는 새로운 two-stage learning 프레임워크를 그림 1과 같이 제안하였다. general distillation은 pre-trained BERT의 풍부한 embedded 지식을 학습하게 하고, 이는 TinyBERT의 정규화 능력을 향상시키는데 중요한 역할을 한다. task-specific distillation은 fine-tuned TinyBERT로부터 추가적으로 TinyBERT를 학습시킨다. two-step distillation과 함께, 논문에서는 teacher과 student의 갭을 상당히 줄였다.
General Distillation 논문에서는 fine-tuning이 되지 않은 BERT를 teacher로 사용하고, large-scale text corpus를 학습 데이터로 사용하였다. general domain의 text에 대해 Transformer distillation을 수행함으로써, downstream task에 대해 fine-tune할 수 있는 TinyBERT를 얻었다. 하지만, hidden/embedding 크기와 layer 수의 상당한 감소로 인해 general TinyBERT는 BERT에 비해 좋지 않은 성능을 보여준다.
Task-specific Distillation 이전의 연구들에서 fine-tuned BERT 같이 복잡한 모델들은 domain-specific task에 대해서 over-parameterization을 겪고 있음을 밝혀냈다. 따라서, BERT보다 작은 모델도 BERT에 필적하는 성능을 낼 수 있다는 가능성을 보여준다. 이를 위해, 논문에서는 task-specific distillation을 통해 경쟁력 있는 fine-tuned TinyBERT를 제안하였다. task-specific distillation에서, 제안된 augmented task-specific dataset에 대해서 Transformer distillation을 재수행하였다. fine-tuned BERT가 teacher로 사용되고, data augmentation method는 task-specific 학습 셋을 늘리기 위해 제안되었다. 더 많은 task관련 example과 함께 학습하면, student model의 정규화 능력을 추가적으로 향상시킬 수 있다.
Data Augmentation 논문에서는 pre-trained LM인 BERT와 GloVe word embedding을 합쳐서 data augmentation을 위한 대체를 하였다. 그리고 LM을 사용하여 single-piece 단어의 단어 대체를 예측하고, word embedding을 사용해서 multiple-peices 단어 대체를 위해 가장 비슷한 단어를 되찾는다. 몇몇 하이퍼 파라미터들은 문장의 대체 비율과 augmented dataset의 양을 조절하기 이해 정의된다. data augmentation 프로시저의 추가적 디테일은 알고리즘 1에 나와 있다. 여기서 $p_{t}=0.4, N_{a}=20, K=15$이다.

위의 두 learning stage는 서로 상호보완적이다. general distillation은 task-specific distillation을 위한 좋은 초기화를 제공하는 반면, augmented data에서의 task-specific distillation은 task-specific한 지식을 학습하는 것에 집중함으로써 TinyBERT를 추가적으로 향상시켰다. model size의 상당한 감소에도 불구하고, data augmentation과 함께 제안된 Transformer distillation을 pre-training과 fine-tuning stage에 수행함으로써, TinyBERT는 다양한 NLP task에 대해서 경쟁력 있는 성능을 달성하였다.
3. Experiment Results
논문에서는 논문의 model을 GLUE 데이터셋의 test set에 대해 실험을 진행하였다. 그 결과가 다음의 표 1에 나타나 있다.

4-layer student model에 대한 실험의 결과는 다음과 같다.
- $BERT_{tiny}$와 $BERT_{base}$ 간에 큰 성능의 갭이 있었음. 이는 극적인 model size의 감소 때문
- TinyBERT가 $BERT_{tiny}$보다 훨씬 나음. 제안된 KD가 성능 향상에 효과적이었음.
- TinyBERT가 KD baseline보다 성능 면에서 우수
- teacher $BERT_{base}$와 비교해서 TinyBERT가 더 작고, 더 빨랐음
- CoLA 데이터셋에 대해 4-layer-distilled model은 teacher model에 비해 큰 성능 갭을 보여줬음. TinyBERT는 상당한 성능 향상을 보여줬음.
- 적은 layer 수에도 불구하고 TinyBERT는 Mobile BERT-24layer와 비슷한 score를 받음
- capacity를 늘리면 teacher에 필적하는 성능을 얻을 수 있을 정도로 성능이 향상함
- TinyBERT의 general distillation 후에 task-specific stage를 겪음. 이는 다른 KD 모델들과 반대되는 순서
논문의 two-stage distillation 프레임워크에서 TinyBERT는 general distillation을 통해 초기화되면서, 모델의 구조를 선택하는데 더욱 유동적이게 만들어주었다.
4. Ablation Studies
이 섹션에서는 다음의 두 가지 contribution에 대해 abalation study를 진행하였다.
- two-stage TinyBERT 학습 프레임워크의 서로 다른 프로시저
- 서로 다른 distillation objective
4-1. Effects of Learning Procedure
two-stage TinyBERT 학습 프레임워크는 3개의 중요한 프로시저로 구성되어 있다: GD$($general distillation$)$, TD$($task-specific distillation$)$, DA$($data augmentation$)$. 각각의 학습 프로시저를 제거했을 때 성능의 차이를 분석했는데, 이 결과가 다음의 표 2에 나타나 있다. 결과적으로 3개의 학습 프로시저 모두 중요하지만, TD와 DA는 비슷한 성능 향상을 보여주는 반면에, GD가 성능에 가장 큰 영향을 주고 있다.

4-2. Effects of Distillation Objective
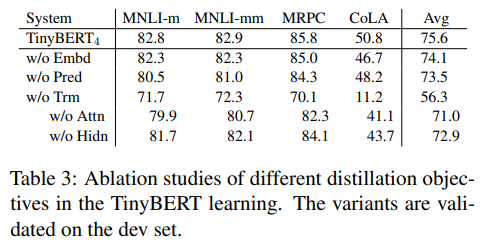
TinyBERT 학습에 대한 distillation objective의 효과를 조사하였다. 다양한 baseline들에 대해 Transformer-layer distillation이 없는 학습과 embedding-layer distillation이 없는 학습, prediction-layer distillation이 없는 학습을 각각 조사하였다. 이에 대란 결과가 다음의 표 3에 나타나 있다. 결과를 살펴보면, Transformer-layer distillation이 없는 경우 상당한 성능 감소를 보여준다는 것을 알 수 있다. 이는 student model의 초기화와 연과되어 있기 때문이다. 여기서 attention based distillation이 hidden states based distillation이 더 강한 영향력을 가지고 있음을 알 수 있었다.
5. Effects of Mapping Function
논문에서는 TinyBERT 학습에 대해 서로 다른 mapping function $n = g(m)$의 효과에 대해서도 조사하였다. 기존 TinyBERT의 uniform 전략과 두 개의 전형적인 baseline인 top strategy$(g(m) = m + N - M; 0 < m \leq M)$와 bottom-strategy$(g(m) =m; 0 < m \leq M)$을 비교하였다.
비교 결과는 다음의 표 4에 나타나 있다. 그 결과 top-strategy가 bottom-strategy보다 MNLI에 대해 더 좋은 성능을 보여줬지만, MRPC와 CoLA에 대해서는 더 안 좋은 성능을 보여줬다. 이는 서로 다른 BERT layer로부터의 지식에 대해 의존하는 서로 다른 task에 대한 관찰을 입증하였다. 그리고 uniform strategy가 다른 두 baseline보다 좋은 성능을 보여줬다.

출처
https://arxiv.org/abs/1909.10351
TinyBERT: Distilling BERT for Natural Language Understanding
Language model pre-training, such as BERT, has significantly improved the performances of many natural language processing tasks. However, pre-trained language models are usually computationally expensive, so it is difficult to efficiently execute them on
arxiv.org