
The overview of this paper
논문에서는 텍스트 범위를 더욱 잘 표현하는 pre-training method인 SpanBERT를 소개하였다. 논문에서의 방식은 BERT를 다음과 같이 확장하였다. 1. 랜덤 토큰을 마스킹하기 보다는 인접한 랜덤 토큰을 마스킹 2. Span Boundary Representations$($SBO$)$를 학습시켜 각각의 token representation에 의존하지 않고 masked token의 전체 내용을 예측. SpanBERT는 BERT를 능가하는 성능을 보여줬고, SpanBERT는 QA와 coreference resolution 같은 span selection 문제에서 좋은 성능을 보여줬다.
Table of Contents
1. Introduction
2. Backgorund: BERT
3. Model
3-1. Span Masking
3-2. Span Boundary Objectives$($SBO$)$
3-3. Single-Sequence Training
4. Results
4-1. Per-Task Results
4-2. Overall Trends
5. Ablation Studies
5-1. Masking Schemes
5-2. Auxiliary Objectives
1. Introduction
BERT와 같은 pre-training method들은 각각의 단어들 또는 subword unit을 마스킹하는 self-supervised training을 사용해서 강력한 성능을 보여준다. 하지만, 많은 NLP task들은 두 개 또는 더 많은 텍스트에 간의 관계를 추리하고는 한다. 논문에서는 BERT를 훨씬 뛰어넘는 span-level의 pre-training 방식을 소개하였다.
논문에서 소개한 SpanBERT는 pre-training method로 텍스트 범위를 더욱 잘 표현하고 예측하도록 디자인되었다. 논문의 방법은 masking scheme과 training 목표 면에서 BERT와 달랐다. 첫 번째로, SpanBERT는 각각의 랜덤한 token을 예측하는게 아니라, 랜덤하게 인접한 span을 예측하였다. 두 번째로, 관찰된 토큰의 전체 마스킹된 token을 예측하는 새로운 span-boundary objective$($SBO$)$를 소개하였다. Span-based masking은 모델에게 span이 등장하는 문맥에 대해 예측하도록 한다. 게다가, SBO는 모델에게 boundary token에 span-level의 정보를 저장할 수 있도록 하였다. 다음의 그림 1이 논문의 방식을 설명하고 있다.
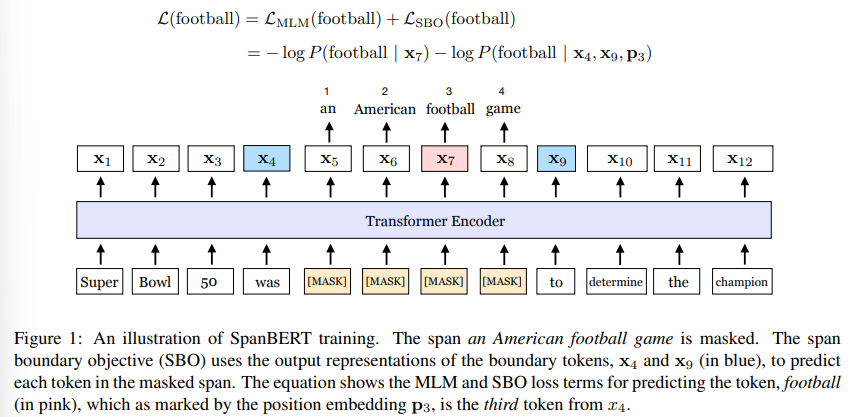
SpanBERT를 활용하기 위해 논문에서는 기존의 BERT를 뛰어넘는 잘 튜닝된 BERT를 만들었다. 논문에 사용된 baseline을 만드는 도중에, two half-length segment로 pre-training을 하는 것보다 single-segement에 NSP와 함께 pre-training을 하는 것이 대부분의 downstream task에서 향상된 성능을 보여준다는 것을 알 수 있었다. 따라서, 논문에서는 이러한 수정 사항을 tuned single-sequence BERT baseline의 맨 위에 추가하였다.
모든 것을 종합하여, 논문의 pre-training 프로세스는 여러 분야에 걸쳐서 BERT baseline을 능가하는 model을 만들어 냈다. 그리고 특히 span selection task에 대해서 상당한 성능 향상을 보여줬다. 그리고 SpanBERT는 새로운 SOTA를 달성하였다!! 🔥
2. Background: BERT
SpanBERT는 이름에서부터 알 수 있듯이, 기본적으로 BERT에 기반을 두고 있는 모델이다. 따라서 논문을 읽을 때, BERT에 대한 사전 지식이 있으면 이해하는데 도움이 된다. 본 블로그에서 이전에 업로드한 포스트 중에 BERT에 관한 포스트가 있으니 참고하길 바란다.
Pre-trained Language Modeling paper reading(2) - BERT: Pre-training of Deep Bidirectional Transformers for Language Understandin
Pre-trained Language Modeling paper reading 요즘 NLP 분야에서 뜨거운 감자인 pre-trained Language Modeling에 관한 유명한 논문들을 읽고 리뷰를 하였다. 이 Pre-trained Language Modeling paper reading은 이 포스트만으로 끝
cartinoe5930.tistory.com
3. Model
논문에서는 텍스트 범위를 더욱 잘 표현하고 예측하는 self-supervised pre-training method인 SpanBERT를 소개하였다. SpanBERT는 BERT에서 영감을 받았는데, BERT의 bi-text 분류 프레임워크로부터 다음의 세 부분에서 일탈하였다.
- 토큰 하나 보다는 토큰 범위를 마스킹하기 위한 서로 다른 랜덤 프로세스를 사용하였다.
- span boundary에서 token의 representation만을 사용해서 전체 masked span을 예측하는 새로운 auxiliary 목표인 SBO를 소개하였다.
- SpanBERT는 각각의 training example에 대해 text의 하나의 인접한 segment를 샘플링하였고, BERT의 NSP를 사용하지 않았다.
3-1. Span Masking
token sequence $X = (x_1, x_2, ..., x_n)$이 주어지면 masking budget에 따라서 토큰의 서브셋인 $Y \subseteq X$를 선정한다. 각각의 반복에서, 처음에 기하학적 분포 $l ~ Geo(p)$로부터 span length를 샘플링해온다. 그 다음에 랜덤하게 마스킹되어야할 soan의 시작 지점을 선정해야 한다. 논문에서는 항상 완성된 단어들의 sequence를 샘플링하고, 시작 지점은 무조건 한 단어의 시작 부분이어야 한다. 이전의 시도들에 따라 $p = 0.2$와 $l_{max}=10$으로 설정하였다. 이것은 평균 span length $mean(l) = 3.8$를 내놓았다. 다음의 그림 2는 span mask length의 분포를 보여주고 있다.

masking 전략은 BERT의 전략과 똑같이 진행하였다. 그저 각각의 token에 대해 했던 것이 span-level으로 바뀌었다는 점만 다르다. span안에 들어가 있는 모든 토큰은 [MASK] 토큰으로 변환된다.
3-2. Span Boundary Objectives $($SBO$)$
Span selection model은 이것의 boundary token을 사용해서 span의 고정된 길이의 representation을 생성한다. 이러한 모델을 지원하기 위해, 논문에서는 가능한 한 많은 내부 범위 콘텐츠를 요약하기 위해 범위의 끝에 대한 표현을 이상적으로 원했다. 그래서 boundary에서 관찰된 representation만을 사용해서 각각의 masked span의 token을 예측하는 것을 포함하는 SBO를 소개하였다.
공식적으로, 논문에서는 sequence에서의 각각의 토큰 $x_1, ..., x_n$에 대한 transformer encoder의 출력을 나타내었다. token의 masked span $(x_s, ..., x_e) \in Y$$($여기서 $(s, e)$는 시작과 끝지점을 나타냄.$)$가 주어지면, SBO는 external boundary token $x_{s-1}$과 $x_{e+1}$의 output encoding을 사용해서 각각 span의 toekn $x_i$를 표현한다. 뿐만 아니라, target token $\textbf{p}_{i-s+1}$도 사용한다.
$\textbf{y}_i = f(\textbf{x}_{s-1}, \textbf{x}_{e+1}, \textbf{p}_{i-s+1})$
여기서 postion embedding $\textbf{p}_1, \textbf{p}_2,...$은 왼쪽 boundary token $x_{s-1}$에 관하여 masked token의 상대적 위치를 마크한다. 논문에서는 representation function $f(\cdot)$을 2-layer feed-forward network와 GeLU 활성화 함수와 layer normalization로 활용하였다.
$\textbf{h}_0 = [\textbf{x}_{s-1}; \textbf{x}_{e+1}; \textbf{p}_{i-s+1}]$
$\textbf{h}_1 = LayerNorm(GeLU(\textbf{W}_{1}\textbf{h}_{0}))$
$\textbf{y}_{i} = LayerNorm(GeLU(\textbf{W}_{2}\textbf{h}_{1}))$
논문에서는 vector representation $\textbf{y}_{i}$를 사용하서 token $x_i$를 예측하고 MLM 목표와 비슷하게 cross-entropy loss를 계산한다.
SpanBERT는 span boundary와 masked span의 각 token $x_i$에 대한 기존 MLM의 목표에 대한 loss를 합하였다. 수식은 다음과 같다.
$L(x_i) = L_{MLM}(x_i) + L_{SBO}(x_i) = -log P(x_i | \textbf{x}_i) - log P(x_i | \textbf{y}_i)$
3-3. Single_sequence Training
BERT의 학습 방법을 보면 알 수 있듯이, BERT는 두 개의 텍스트 시퀀스 $(X_A, X_B)$를 가지고, 모델은 이 두 문장이 이어진 문장인지 예측하는 NSP를 통해 학습된다. 이러한 세팅은 NSP 목표 없이 그저 single sequence를 사용하는 것보다 안 좋은 성능을 보여주는 것을 알 수 있었다. 논문에서는 single-sequence 학습이 bi-sequence 학습보다 우월한 이유를 다음과 같이 추측하였다.
- 모델이 더욱 길고 full-length context에서 잘 작동
- 연관되어 있지 않은 문서로부터 나온 context는 MLM에 noise를 생성할 수 있음
따라서, 이러한 방식에서, 논문에서는 NSP objective와 two-segment sampling 프로시저를 제거하고, 두 개의 짧은 문장을 샘플링하기 보다는 최대 512개의 토큰을 가지는 하나의 인접한 segment를 샘플링하도록 하였다.
요약하면, SpanBERT는 span representation을 다음과 같이 pre-train 하였다.
- masking scheme에 기반을 둔 기하학적 분포를 사용해서 full word의 span을 masking
- auxiliary span-boundary objective를 최적화하고, MLM을 할 때 single-sequence pipeline을 사용함
4. Results
논문에서는 각 task에 대한 baseline과 SpanBERT를 비교하고, 전반적인 트렌드에 대한 결론을 그렸다.
4-1. Overall Trends
실험의 결과에 대한 전반적인 경향은 다음과 같다.
- SpanBERT는 거의 모든 task에 대해 BERT를 능가하였음. ✅
- SpanBERT는 특히 extractive question answering에서 좋은 성능을 보여줌. 💪
- single-sequence training이 NSP와 함께한 bi-sequence training보다 상당히 좋은 성능을 보여줌. 🔥
5. Ablation Studies
논문에서는 SpanBERT의 랜덤 span masking scheme과 linguistically-informed masking scheme과 비교하였고, 랜덤 span masking이 경쟁력이 있고, 종종 더 좋은 결과를 보여준다는 것을 알 수 있었다. 그 다음에, SBO의 효과에 대해 연구하였고, 이 SBO를 BERT의 NSP와 비교하였다.
5-1. Masking Schemes
이전의 연구들은 pre-training 중에 linguistically-informed span을 마스킹함으로써 downstream task의 성능을 향상시킬 수 있다는 것을 보여줬다. 그래서 논문에서는 SpanBERT의 random span masking을 linguisticall-informed span과 비교하였다. 특히, 논문에서는 다음의 다섯 개의 baseline model에 대해서 학습시키고 비교를 진행하였다.
- Subword Tokens: WordPiece token을 랜덤하게 샘플링
- Whole Words: word의 모든 subword token을 마스킹
- Names Entities: 50%에 대해서는 text의 named entities에 따라 샘플링하고, 50%에 대해서는 랜덤한 전체 단어를 샘플링
- Noun Phrases: Named Entities와 비슷하게, 50%에 대해서는 명사구문에 대해 샘플링
- Geometric Spans: SpanBERT의 geometric 분포로부터 랜덤한 span을 샘플링
다음의 표 1은 서로 다른 pre-training masking scheme이 task에 대해 어떠한 성능을 보여주는지를 보여주고 있다. 표를 살펴보면, coreference resolution을 제외하고는 모든 task에 대해서 random span을 마스킹하는 것이 더 좋은 성능을 보여줬다. linguistic masking scheme$($named entities & noun phrases$)$도 경쟁력 있는 성능을 보여줬으나, 이들의 성능은 일관되지 않는 모습을 보여줬다.

5-2. Auxiliary Objectives
결과 장에서 봐서 알 수 있듯이 single-sequence training과 비교해서, NSP와 함께한 bi-sequence training은 downstream task의 성능에 안 좋은 영향을 끼칠 수가 있다. 실제로 이런지를 확인하기 위해 span masking으로 학습된 모델을 평가하고, NSP를 제거한 효과를 알아보았다.
다음의 표 2를 보면 single-sequence training이 성능을 향상시킨다는 것을 알 수 있다. SBO를 추가하는 것이 추가적으로 성능을 향상시키고, span masking을 혼자 사용하는 것보다 coreference resoultion에 대해 상당한 성능 향상을 준다. NSP와 달리 SBO는 딱히 부정적인 효과가 나타나지 않았다.

출처
https://arxiv.org/abs/1907.10529
SpanBERT: Improving Pre-training by Representing and Predicting Spans
We present SpanBERT, a pre-training method that is designed to better represent and predict spans of text. Our approach extends BERT by (1) masking contiguous random spans, rather than random tokens, and (2) training the span boundary representations to pr
arxiv.org