
The overview of this paper
기존의 Transformer 기반의 모델들은 long sequence 처리가 불가능하였다. 왜냐하면, 계산량이 기하급수적으로 늘어났기 때문이다. 이러한 제약을 해결하기 위해, sequence length에 따라 선형적으로 스케일링되는 attention mechanism을 가지고 있는 Longformer을 소개하였다. 이는 수천개 또는 더 긴 토큰을 가지는 문서에 대해서도 쉽게 처리할 수 있게 만들어주었다. Longformer의 attention mechanism은 기존의 self-attention에 대한 drop-in 대체이고, local windowed attention과 task motivated global attention을 합쳤다. 이전의 long-sequence transformer 연구를 따라서, character-level language modeling을 평가하고, text8과 enwik8에 대해서 SOTA를 달성하였다. 이전의 대부분의 연구와 달리, 논문에서는 Longformer 또한 훈련하고, 이를 다양한 downstream task에 대하여 fine-tune 하였다. 논문에서 pre-train한 Longformer는 long document task에서 RoBERTa를 넘어서고, 새로운 SOTA를 달성하였다.
Table of Contents
1. Introduction
2. Longformer
2-1. Attention Pattern
2-2. Implementation
3. Autoregressive Language Modeling
3-1. Attention Pattern
4. Pre-training & Fine-tuning
5. Results
6. Longformer-Encoder-Decoder$($LED$)$
1. Introduction
Transformer는 출현하자마자 여러 NLP task들에 대해서 SOTA를 달성하였다. 이렇게 좋은 성능을 얻게 된 부분적 이유는 self-attention 때문인데, 이것은 전체 sequence로부터 네트워크가 문맥적 정보를 캡처할 수 있도록 해준다. self-attention은 매우 강력하지만, sequence length에 따라 기하급수적으로 비용이 증가한다는 문제 때문에, 긴 sequence를 처리하지 못한다는 단점이 있다.
이러한 제약을 해결하기 위해서 논문에서는 self-attention을 손봐서 sequence length에 따라 선형적으로 증가하는 self-attention을 사용하는 Transformer architecture인 Longformer을 소개하였다. 이러한 점은 모델이 긴 sequence를 처리하는 능력을 향상시켜줬다. 이러한 점은 long document에서 행해지는 NLP task에 대해서 장점을 가진다. 반면에, 현존하는 방식들은 긴 문맥을 짧은 sequence로 잘라서 보통 BERT-style pre-trained model처럼 512개의 토큰 내에 들어오도록 하였다. 이러한 분할은 중요한 cross-partition 정보를 손실할 수 있게 되는데, 이를 완화하기 위해, 현존하는 방식들은 종종 복잡한 architecture에 의존해서 해결하려고 한다. 반면에, Longformer는 여러 attention layer를 사용해서 전체 context의 문맥적 representation을 만들 수 있었다. 이로 인해 task-specific한 architecture에 대한 필요가 줄어들었다. 다음의 그림 1은 Longformer가 long document를 처리할 때 강함을 보여주고 있다.

최근의 연구들은 long sequence에 대한 Transformer의 계산적 비효율성을 해결하였다. 하지만, 이들은 주로 autoregressive LM에 집중하는 반면, long document transformer는 transfer learning 세팅의 document-level NLP task에 대한 응용은 아직도 미지의 영역이었다. 이러한 갭을 줄이고, Longformer의 sefl-attention이 pre-trained Transformer의 self-attention을 drop-in 대체할 수 있다는 것을 보여주었다. 그리고 적합한 NLP task에 대해 성능 향상을 보여줬다. 다음의 표 1은 Transformer을 긴 문서에 대해 적용시킨 조건에 대한 요약을 보여주고 있다.

Longformer의 attention mechanism은 windowed local-context self-attention과 end task motivated global attention이 사용되었다. 여기서 windowed local-context self-attention은 window와 새로운 확장된 attention 패턴의 조합으로 이루어져 있다.
Longformer의 능력을 평가하기 위해 현존하는 pre-trained 모델들의 full self-attention을 대체하고, Longformer을 MLM을 사용하여 pre-train하였다. pre-training 후에는, 이 Longformer를 fine-tuning을 통해 downstream language task에 적용하고, Longformer가 대부분의 task에 대해서 RoBERTa를 능가하는 성능을 보여줬다.
마지막으로 encoder-only의 Transformer architecture 대신에, 기존의 Transformer와 유사한 encoder-decoder architecture을 따르는 Longformer의 변형을 소개하였다. 그리고 이것은 seq2seq learning을 위해 의도되었다. 논문에서는 이 모델을 Longformer-Encoder-Decoder$($LED$)$라고 불렀다. LED는 encoder network에서 Longformer의 효율적인 attention pattern을 사용해서 long document seq2seq task에 대해서 수행할 수 있다.
2. Longformer
기존의 Transformer model은 sequence length $n$에 대해 $O(n^{2})$의 시간복잡도를 가지는 self-attention을 가지고 있다. 이러한 문제점을 해결하기 위해, 논문에서는 full self-attention 행렬에 대한 성김을 다른 하나를 참조하는 input location의 짝을 명시하는 'attention pattern'에 따라서 풀어나갔다. full self-attention과 달리, 논문에서 제안한 attention pattern은 input sequence에 대해 선형적으로 스케일링해서 longer seuquence에 대해서 효율적이게 만들었다.
2-1. Attention Pattern
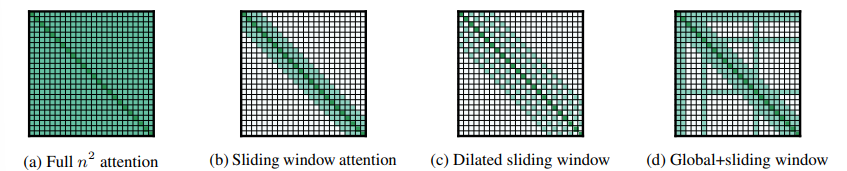
Sliding Window local context의 중요성이 주어지면, Longformer의 attention pattern은 각 토큰의 주변에 대해 고정된 크기의 window를 사용하였다. 이러한 windowed attention의 여러 스택 레이어를 사용하면 큰 receptive field가 생성되며, 여기서 최상위 레이어는 모든 입력 위치에 액세스하고 CNN과 유사하게 전체 입력에 대한 정보를 통합하는 representation을 구축할 수 있다. 고정된 window 크기 $w$가 주어지면, 각각의 토큰은 각각의 면에서 $\frac {1}{2} w$의 토큰을 참조한다. 그림 2의 b를 참고하길 바란다. 이 pattern은 input sequence length $n$을 선형적으로 스켕일링해서 시간 복잡도는 $O(n \times w)$이다. $l$ layer의 transformer에서 top layer의 receptive field size는 $l \times w$이다. 응용에 따라 효율성과 model representation 용량 사이의 균형을 맞추기 위해 각 계층에 대해 서로 다른 $w$ 값을 사용하는 것이 도움이 될 수 있다.
Dilated Sliding Window 계산량을 늘리지 않고 receptive field를 추가적으로 증가시키기 위해, sliding window는 확장$($dilated$)$될 수 있다. 이것은 window가 size dilation $d$의 갭을 가지는 dilated CNN과 유사하다. 그림 2의 c를 참고하길 바란다. 모든 레이어에 대해 고정된 $d$와 $w$를 가하면, receptive field는 $l \times d \times w$이며, 작은 값 $d$에 대해서도 수만 개의 토큰에 도달할 수 있다.
multi-headed attention에서, 각각의 attention head는 서로 다른 attention score를 계산한다. 논문에서는 dilation이 없는 몇 개의 head를 local context에 집중하도록 하는 반면, 다른 것들은 longet context에 집중하도록 하여 각 head에 대한 서로 다른 dilation 구성과 세팅을 찾았다.
Global Attention Longformer의 경우에 windowed & dilated attention은 task-specific한 representation을 배울 수 있을 정도로 유연하지 않다. 그에 따라서, 논문에서는 몇 개의 사전 선택된 input location에 'global attention'을 추가하였다. 이 global attention과 함께하는 토큰들은 sequence의 모든 token을 참조할 수 있다. 그림 2의 d를 보면 몇 개의 custom location token에 대한 global attention과 sliding window의 예시를 보여주고 있다. global attention을 명시하는 것은 task specific한 반면에, model의 attention에 귀납적 편향을 추가하는 것은 쉽고, 현존하는 task specific 방식들이 복잡한 architecture을 사용해서 작은 input chunk에 대해 정보를 합치는 것보다 훨씬 간단하게 할 수 있다.
Linear Projections for Global Attention linear projection $Q, K, V$가 주어지면 Transformer model은 attention score를 다음과 같이 계산한다.
$Attention(Q, K, V) = softmax(\frac {QK^{T}}{\sqrt{d_{k}}})V$
논문에서는 두 개의 projection set를 사용했는데, $Q_s, K_s, V_s$는 sliding window attention의 attention score를 계산하고, $Q_g, K_g, V_g$는 global attention에 대한 attention score를 계산한다. 추가적인 projection은 서로 다른 유형의 attention에게 융통성을 제공한다. 이는 downstream task에 대해서 최고의 성능을 내는데 매우 중요한 요소이다. $Q_g, K_g, V_g$는 $Q_s, K_s, V_s$에 맞춰서 초기화된다.
2-2. Implementation
일반적인 transformer에서 attention score는 위의 수식처럼 계산된다. 저기서 계산 비용이 비싼 연산은 행렬곱 연산인 $QK^{T}$인데, 왜냐하면 $Q$와 $K$는 둘 다 $n$개의 projection을 가지기 때문이다. Longformer에 대해, dilated sliding window attention은 고정된 수의 $QK^{T}$의 대각선만 계산한다. 그림 1에 나와있는 것처럼, 이것은 full self-attention이 이차식으로 증가하는 거에 비해 메모리 사용량이 선형적으로 증가한다는 결과를 보여준다.
3. Autoregressive Language Modeling
Autoregressive 또는 left-to-right language modeling은 input sequence의 이전 token 또는 character가 주어지면, 지금의 token 또는 character의 확률 분포를 측정한다. 이 task는 자연어의 기본 task 중 하나로 간주되며 transformer를 사용하여 긴 시퀀스를 모델링하는 최근의 연구들은 이 task를 주요 평가로 사용했다.
3-1. Attention Pattern
autoregressive language modeling을 위해 논문에서는 dilated sliding window attention을 사용하였다. 이전 연구를 따라서 layer에 따라 서로 다른 window size를 사용하였다. 특히, 낮은 layer에 대해서는 작은 window size를 사용하였고, 높은 layer로 올라갈수록 더욱 큰 window size를 사용하였다. 이는 top layer가 낮은 layer가 local information을 캡처하고 있을 때, 전체 sequence의 higher-level representation을 학습하도록 허락해준다. 게다가, 이것은 효율성과 성능에 밸런스를 제공해준다.
논문에서는 낮은 layer에 대해 dilated sliding window을 사용하지 않았는데, 즉각적인 local context를 학습하고 이용하기 위해 이들의 수용력을 극대화하기 위해서이다. 높은 layer에 대해 논문에서는 오직 2개의 head에서 증가하는 dilation의 작은 양을 사용하였다. 이는 모델에게 local context를 희생하지 않고 거리가 먼 token을 직접 참고할 수 있는 능력을 주었다.
4. Pre-training & Fine-tuning
현재의 많은 NLP task에 대한 SOTA system은 task supervision과 함께 fine-tune된 pre-trained model을 사용한다. 이 논문에서 하고자 했던 것은 더욱 긴 document task에 적합한 모델을 개발하는 것이었다. 이를 위해, 논문에서는 Longformer를 document corpus에서 pre-train 하고, 6개의 task에 대해서 fine-tune 하였다. 결과적으로 나온 모델은 4,096개 이상의 토큰을 갖고 있는 sequence를 처리할 수 있다. 이는 BERT에 비해 8배 더 긴 것이다.
논문에서는 Longformer를 MLM을 이용해서 pre-train 하였다. 여기서 목표는 sequence에서 랜덤하게 masking된 token을 회복하는 것이다. Longformer의 attention pattern은 어떠한 pre-trained transformer model에도 model의 architecture을 수정할 필요 없이 바로 사용될 수 있다.
- Attention Pattern: window size가 512인 sliding winodw attention을 사용
- Position Embeddings: RoBERTa는 최대 길이가 512인 학습된 absolute position embedding을 사용. long document를 지원하기 위해, 추가적인 position embedding을 4,096까지 제공
- Continued MLM Pre-training: 편집된 long document의 corpus에 대해 fairset를 사용해서 Longformer을 pre-train함
- Frozen RoBERTa Weights: 모든 RoBERTa 가중치를 동결하고 새로운 position embedding만 학습하면서, Longformer를 학습시켰음
5. Results
Main Results 다음의 표 2는 모든 fine-tuning 실험의 결과를 요약한 것이다. 그 결과, Longformer가 RoBERTa의 baseline을 능가한다는 것을 알 수 있었다. Longformer의 성능 향상은 long context를 요구로 하는 task에 대해서 분명하게 나타났다. 반면에, short document task에 대해서는 조금의 성능 향상을 보여줄 뿐이었다.

Ablations on WikiHop 다음의 표 3은 development set에서 WikiHop에 대한 ablation study를 보여주고 있다. 모든 결과들은 동일한 파라미터로 다섯 에폭 동안 fine-tune된 Longformer을 사용해서 나왔다. Longformer는 긴 sequence, global attention, global attention에 대한 분리된 projection 행렬, MLM pre-training, longer training로부터 이익을 얻는다. 게다가 RoBERTa-base의 Longformer는 RoBERTa-base보다 살짝 떨어지는 성능을 보여준다. 이는 성능 향상이 추가적인 pre-training으로 인한 것이 아니라는 것을 보여준다. 추가 position embedding만 고정 해제할 때 pre-trained RoBERTa 모델을 사용하면 성능이 약간 떨어진다. 이는 Longformer가 WikiHop과 같은 대규모 훈련 데이터 세트로 task별 fine-tuning에서 long range context를 사용하는 방법을 배울 수 있음을 보여준다.

6. Longformer-Encoder-Decoder $($LED$)$
기존의 Transformer는 seq2seq task를 위한 encoder-decoder architecture로 구성되어 있다. encoder-only의 Transformer는 다양한 NLP task에 대해 효과적인 반면, pre-trained encoder-decoder Transformer model과 T5는 요약과 같은 task에서 강력한 성능을 보여준다. 이러한 모델은 longer input에 대해 seq2seq task를 효율적으로 scale할 수 없다.
seq2seq learning을 위한 long sequence modeling을 용이하게 하기 위해, 논문에서는 encoder와 decoder Transformer 스택을 모두 가지고 있지만, encoder의 full self-attention 대신 Longformer의 효율적인 local + global attention pattern을 사용하는 Longformer의 변형을 제안하였다. decoder는 전체 encoded token과 이전의 decoded location에 대해 full self-attention을 사용한다. 이 모델을 Longformer-Encoder-Decoder$($LED$)$로 부르기로 하였다. 이 LED는 input을 선형적으로 scale한다. pre-training LED의 계산 비용이 비싸기 때문에, 논문에서는 LED의 파라미터를 BART로 초기화하고, BART의 정확한 architecture을 따르도록 하였다. 유일한 차이점은 더욱 긴 input을 처리한다는 것이다. 실제로 position embedding은 기존의 1,000개에서 16,000개의 token으로 연장시키고 새로운 position embedding 행렬을 BART의 1,000개의 position embedding을 16번 반복적으로 곱해서 사용하였다. BART를 따라서 LED도 총 두 개의 사이즈로 나왔는데, LED-base는 6개의 레이어로 이루어져 있고, LED-large는 12개의 레이어로 이루어져 있다. 그리고 둘 다 모두 encoder와 decoder의 스택으로 이루어져 있다.
논문에서는 LED를 arxiv 문서 요약 데이터셋에 대하여 평가하였다. 이 데이터셋은 과학 영역에서 long document 요약에 집중하고 있다. 90% 정도의 document의 길이가 14,500개 이상의 토큰으로 이루어져 있고, 이는 LED를 평가하기 위한 완벽한 testbed이다. LED의 encoder는 document를 읽고, LED의 decoder는 output 요약을 생성한다. encoder는 window size가 1,024개의 토큰인 local attention과 첫 번째 <s> token에 대해 global attention을 사용하였다. decoder는 전체 encoder와 이전의 decoded location에 full attention을 사용하였다. 기존의 seq2seq model처럼 LED는 gold summaries에 teacher forcing을 사용하고, 추론에 beam search를 사용해서 학습하였다.
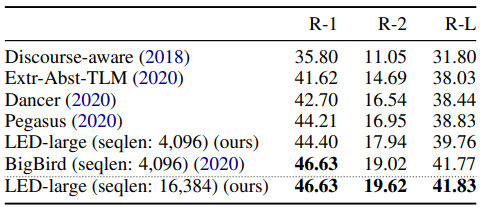
다음의 표 4는 arXiv 요약 task에 대해 LED-large 16K의 결과를 보여주고 있다. 이 모델은 pre-training 없이 단순히 BART로부터 초기화되었다. 논문에서는 LED가 arXiv에 대해서 SOTA를 달성하고, BigBird를 살짝 능가하는 모습을 보여줬다. BigBird 요약 모델은 4K 개의 토큰 길이를 지원하지만, 요약을 위해 특별히 설계되고 pre-trained model인 Pegasus에서 시작하여 pre-train을 계속한다. pre-training 또는 task-specific한 초기화 없이, 오직 longer input을 처리할 수 있는 능력으로 LED는 BigBird를 살짝 능가하는 모습을 보여줬다. 추가적인 개선은 LED의 pre-training을 통해 가능하다.
다음의 그림 3을 보면 longer input을 처리할 수 있는 능력이 결과를 상당히 향상시킨다는 것으로 sequence length의 중요성을 설명하고 있다.

출처
https://arxiv.org/abs/2004.05150
Longformer: The Long-Document Transformer
Transformer-based models are unable to process long sequences due to their self-attention operation, which scales quadratically with the sequence length. To address this limitation, we introduce the Longformer with an attention mechanism that scales linear
arxiv.org