
The overview of this paper
이 논문에서는 새로운 vision Transformer인 Swin Transformer을 제안하였다. 이 Swin Transformer는 computer vision에 대해 general-purpose 척추같은 역할을 한다. 시각적 특성의 다양한 scale과 text에 비해 고해상도인 이미지와 같은 computer vision과 NLP 두 영역의 차이 때문에, Transformer을 computer vision에 적용시키는데 많은 문제가 있었다. 이러한 차이점을 극복하기 위해, 논문에서는 representation이 Shifted Windows와 함께 계산되는 hierarchical Transformer을 제안하였다. shifted windowing 기법은 self-attention 계산을 겹치지 않는 로컬 윈도우로 제한하는 동시에 윈도우 간의 연결을 허용함으로써 더욱 뛰어난 효율성을 제공하였다. hierarchical architecture는 다양한 scale에 대해 모델링하는 것에 대해 유연성을 가지고, 이미지의 크기에 대해 선형 계산 복잡도를 가지고 있다. 이러한 Swin Transformer의 퀄리티는 다양한 분야의 vision task와 성능을 나란히 할 수 있게 해주었다.
Table of Contents
1. Introduction
2. Method
2-1. Overall Architecture
2-2. Shifted Windows based Self-Attention
2-3. Architecture Variants
3. Conclusion
1. Introduction
computer vision 분야에서는 AlexNet이 혁명적인 성능을 보여주면서부터 CNN이 꽉 잡게 되었다. CNN architecture는 발전에 발전을 거듭해 강력한 성능을 얻어낼 수 있었다. 이러한 CNN을 토대로 하는 여러 방법들은 다양한 분야의 computer cision task에 대해 좋은 성능을 보여주었다.
이와는 반대로, NLP에서 network의 진화는 다른 경로를 밟았는데, 오늘날에 가장 많이 사용되는 방법은 Transformer이다. 이 Transformer는 sequence modeling과 transduction task를 위해 발명되었고, attention을 사용함으로써 문서 내에서 long-range dependency를 가진다. Transformer의 NLP분야에서 이러한 엄청난 성공은 연구자들로 하게끔, Transformer을 NLP 분야 외에 computer vision 분야에도 적용시킬 수 있지 않을까 하는 연구 동기를 불러 일으켰다.
이 논문에서는 CNN이 computer vision 분야에서 척추를 담당하고 있는 것처럼, Transformer를 어떠한 computer vision 분야든 간에 적용시킬 수 있도록 만들고자 하였다. 논문에서는 NLP분야에서 Transformer의 높은 성능을 computer vision 분야로 변환하는 것에 많은 어려움을 느꼈다. 왜냐하면 두 modaltiry 사이에는 많은 차이점이 존재하기 때문이다. word token이 기본적 요소로 사용된 NLP분야에서의 Transformer와 달리, computer vision에서는 상당한 scale을 입력으로 요구하는 것과 같은 문제도 있다. 기존의 Transformer 기반의 모델에서, 토큰은 모두 고정된 크기이고, 이것은 computer vision에는 부적합한 특성이다. 또다른 차이점은 text와 달리 image는 고해상도의 픽셀로 이루어져 있다. semantic segmentation 같은 visual task는 픽셀 레벨에서의 dense prediction을 요구하고, 이것은 고해상도의 이미지에서 Transformer을 다루기 힘들다는 것은 얘기한다. 왜냐하면 self-attention의 계산 복잡도는 이미지 사이즈의 quadratic이기 때문이다. 이러한 문제점을 해결하기 위해, 논문에서는 Swin Transformer을 제안하였다. 이것은 계층형 피쳐맵을 구성하고 이미지 크기에 대해 선형 게산 복잡도를 가진다. 그림 1의 a에서 묘사되어 있는 것처럼, Swin Transformer는 작은 크기의 patch로부터 시작해서 점차적으로 이웃의 patch들을 합쳐가면서 깊어지는 Transformer layer을 사용함으로써, 계층형 representation을 구성하였다. 선형 계산 복잡도는 이미지를 분할하는 겹치지 않는 창 $($빨간색 윤곽선$)$ 내에서 로컬로 self-attention을 계산하여 달성된다. 각 윈도우에서 patch의 수는 고정되고, 따라서 복잡도는 이미지의 크기에 선형이다. 이러한 장점은 Swin Transformer가 다양한 visual task에 대해 적합한 general-purpose backbone 역할을 한다. 이전의 Transformer 기반 architecture는 하나의 resolution에 대해 quadratic의 복잡도를 가지기 때문에 general-purpose하지 못 했지만, Swin Transformer는 가능하다.
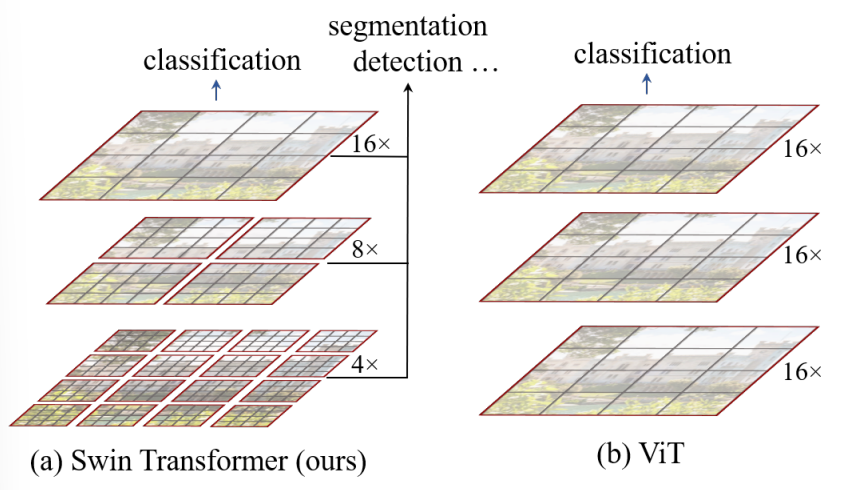
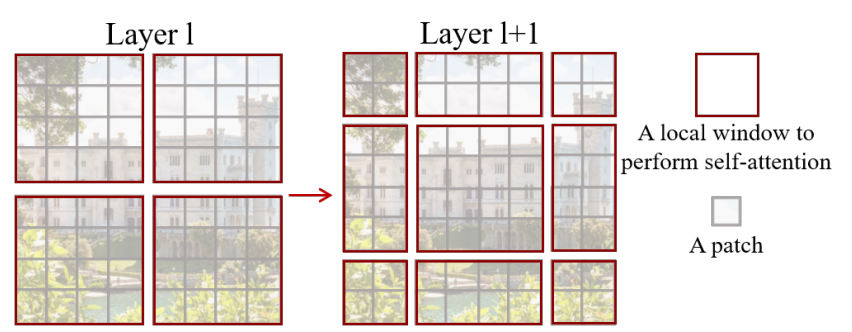
Swin Transformer의 중요한 요소는 그림 2에서 묘사되고 있는, 연속되는 self-attention 간의 window partition의 shift이다. shifted window는 이전 레이어의 window를 이으면서, 이들 사이에 모델의 파워를 향상시키는 connection을 제공한다. 이러한 전략은 또한 real-wordl latency에 대해서 효율적이다. window 내의 모든 query patch는 하드웨어의 메모리 액세스를 용이하게 해주는 key set를 공유한다. 이와는 반대로, 이전의 sliding winodw 기반의 self-attention 기법들은 서로 다른 key set와 quety pixel 때문에 general 하드웨어에서 low latency를 경험하였다. 논문의 실험들은 제안된 shifted window 방식이 sliding window와 비슷한 modeling power에 낮은 latency를 가진다는 것을 보여주었다. shifted window 방식은 또한 모든 MLP architecture에 대해 유리함을 증명하였다.
2. Method
2-1. Overall Architecture
Swin Transformer의 architecture에 대한 개요는 다음의 그림 3에 나타나있다. 그림 3은 Swin Transformer의 tiny 버전을 묘사하고 있다.
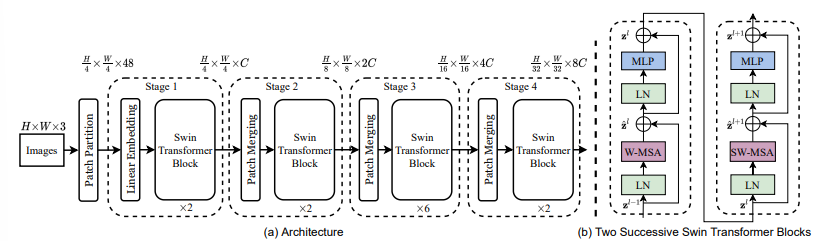
처음에, 입력 RGB 입력 이미지를 ViT와 같은 patch splitting module을 활용하여 non-overlapping patch로 나눈다. 각 patch는 'token'처럼 다뤄지고, feature은 raw pixel RGB 값의 concatenation set이다. 논문의 활용에서는, $4 \times 4$ 크기의 patch를 사용하였고, 그래서 각 patch의 feature 차원은 $4 \times 4 \times 3=48$이다. 선형 임베딩 레이어는 이 raw-valued feature을 임시의 차원으로 project하기 위해 적용된다.
modified self-attentuon과 함께 다양한 Transformer block은 이러한 patch token에 적용된다. Transformer block은 token의 수를 $(\frac{H}{4} \times \frac{W}{4})$로 유지하고, 선형 임베딩과 함께 이 모든 것을 'Stage 1'로 명명하였다.
계층형 representation을 생성하기 위해, token의 수는 patch merging layer에 의해 줄어들면서 network는 점점 더 깊어져 간다. 첫 번째 patch merging 레이어는 $2 \times 2$의 이웃 patch들의 각 그룹을 concatenate하고, 4C 차원 연결된 피처에 선형 레이어를 적용한다. 이것은 토큰의 수를 $2 \times 2=4 (2 \times$ resolution의 downsampling$)$에 의해 줄어들고, 출력 차원은 $2C$로 정해진다. Swin Transformer block은 $\frac{H}{8} \times \frac{W}{8}$로 유지되는 해상도로 feature transformation을 위해 나중에 적용된다. patch emerging의 첫 번째 블로과 feature transformation은 "Stage 2"로 나타나있다. 이 과정이 두 번 반복되면, 각각 출력 해상도가 $\frac{H}{16} \times \frac{W}{16}$인 "Stage 3"과 $\frac{H}{32} \times \frac{W}{32}$인 "Stage 4"로 나타내게 된다. 이러한 stage는 공동으로 계층형 representation을 다른 CNN network에서 보통 사용하는 feature map resolution과 함께 수행한다. 그 결과, 제안된 architecture은 손쉽게 다양한 visual task에 존재하는 backbone network를 대체할 수 있다.
Swin Transformer block
Swin Transformer은 기존의 multi-head self attention$($MSA$)$ 모듈을 다른 레이어는 모두 그대로 유지하고, shifted windows 기반의 Transformer block으로 대체함으로써 지어졌다. 그림 3의 b에서 묘사되는 것처럼, Swin Transformer block은 shifted windows 기반의 MSA 모듈로 구성되고, 2 MLP layer 사이에 GELU 비선형성이 적용되는 형태로 계속된다. Layer Normalization$($LN$)$은 각 MSA module과 MLP module 이전에 적용되고, residual connection은 각 모듈의 이후에 적용된다.
2-2. Shifted WIndow based Self-Attention
기존의 Transformer architecture과 이것의 image classification에 대한 적용 모두는 토큰과 모든 다른 토큰의 관계가 계산되는 global self-attention으로 수행된다. global computation은 토큰의 수에 대하여 quadratic한 복잡성을 갖게 하고, 이것은 기존의 Transformer architecture가 dense prediction을 위한 다양한 token을 요구하거나 고해상도 이미지를 표현하는 다양한 vision task에 부적합하게 만든다.
Self-attention in non-overlapped windows
효율적인 모델링을 위해, 논문에서는 local window 안에서 self-attention을 계산하는 것을 제안하였다. window들은 non-overlapping 방식으로 이미지를 균등하게 분할하도록 배열한다. 각 window가 $M \times M$의 patch를 포함한다고 가정하면, global MSA module과 window 기반의 이미지 위의 $h \times w$의 patch의 계산 복잡도는 다음의 수식 1과 같다.
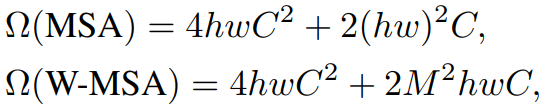
전자는 patch 수 $hw$에 대해 quadratic하고, 후자는 $M$이 고정될 때 선형적이다. global self-attention computation은 일반적으로 큰 $hw$에 대해 너무 많은 비용이 들지만, window 기반의 self-attention은 계산 가능하다.
Shifted window partitioning in successive blocks
window 기반의 self-attention module은 window 사이에 connection이 부족한데, 이것은 modeling power을 감소시킨다. non-overlapping window의 효율적인 computation을 유지하면서 cross-window connection을 소개하기 위해서, 논문에서는 연속된느 Transformer block에서의 두 개의 partitioning 구성을 바꾸는 shifted window partitioning 접근법을 제안하였다.
그림 2에 나타나있는 것처럼, 첫 번쨰 모듈은 top-left 픽셀부터 시작하고, $8 \time 8$의 피쳐맵이 $4\times 4$ zmrldml $2 \times 2$ window로 분할되는 기존의 일반적인 window partitioning 전략이 사용되었다. 그런 다음에, 다음 모듈은 규칙적으로 분할된 창에서 $(\left \lfloor \frac{M}{2} \right \rfloor,\left \lfloor \frac{M}{2} \right \rfloor)$ 픽셀만큼 창을 대체하여 이전 계층의 구성에서 이동된 창 구성을 채택한다.
shifted window 분할 접근법과 함께, 연속된 Swin Transformer block들은 다음과 같이 계산된다.
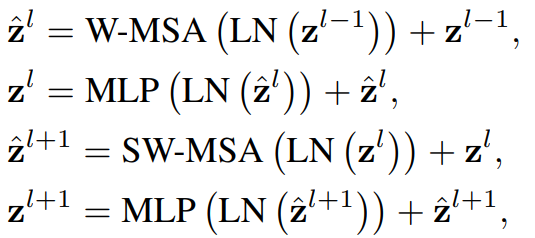
여기서 $\hat{\textbf{z}}^{l}$과 $\textbf{z}^{l}$는 $($S$)$-MSA 모듈과 MLP block의 $l$번째 블록에 대한 출력을 의미한다. W-MSA와 SW-MSA는 일반적인 window partitioning과 shifted winodw partitioning을 사용하는 window 기반의 multi-head self-attention을 나타낸다. 한 마디로, W-MSA는 기존의 window partitioning이고, SW-MSA는 shifed window partitioining을 의미한다.
shifted window partitioning 접근법은 이전 레이어에서 인접한 non-overlapping window 사이의 연결을 도입하고 image classification, object detection 및 sementic segmentation에 효과적인 것으로 밝혀졌다.
Efficient batch somputation for shifted configuration
shifted window partitioning의 문제점은 shifted 구조에서 $\left \lceil \frac{h}{M}\right \rceil \times \left \lceil \frac{w}{M}\right \rceil$로부터 $(\left \lceil \frac{h}{M}\right \rceil+1) \times (\left \lceil \frac{w}{M}\right \rceil+1)$까지 더 많은 window를 결과를 내놓는 것이고, 어떤 window는 $M \times M$보다 작을 것이다. 해결책은 작은 window를 $M \times M$ 크기의 window로 padding하고, 계산할 때 padding된 값을 mask로 씌우는 것이다. 일반적인 partitioning에서 window의 수가 적을 때, 예를 들어서 $2 \times 2$일 때, 해결책에 의한 증가된 계산량은 상당하다. $(2 \times 2 \to 3 \times 3$은 2.25배 더욱 많다$)$ 여기서 더욱 효율적인 batch caomputation 접근법을 top-left 방향에서 cyclic-shifting을 하는 것으로 제안하였다. 이에 대한 설명은 다음의 그림 4에 나타나 있다. 이러한 shift 이후에, batched window는 서로 인접해있지 않은 피쳐맵의 다양한 sub-window로 구성될 것이다. 그래서, 각 sub-window 내에서 self-attention 계산을 제한하기 위해 masking mechanism이 사용된다. cyclic-shift을 하고 나면, batched window의 수는 일반적인 window partitioning을 하고 난 후의 window 수와 똑같아지고, 따라서 이것은 효율적이다.
Relative position bias
self-attention을 계산할 때, 논문에서는 유사성 계산에서 각 head에 대한 relative position bias $B\in \mathbb{R}^{M^{2} \times M^{2}}$를 포함하여 따른다.
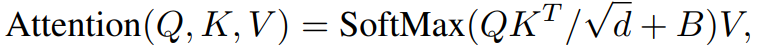
여기서 $Q,K,V\in \mathbb{R}^{M^{2} \times d}$는 query, key, value 행렬이다. $d$는 query와 key의 dimension이고, $M^{2}$은 window의 patch의 수이다. 각 축을 따른 relative position은 범위 $[-M+1,M-1]$에 있기 때문에, 논문에서는 smaller-sized bias 행렬 $\hat{B}\in \mathbb{R}^{(2M-1)\times(2M-1)}$를 파라미터화 하였고, value $B$는 $\hat{B}$로부터 얻어지게 된다.
논문에서는 상당한 성능의 향상을 보여줬다. 입력에 absolute position embedding을 추가하는 것은 성능을 살짝 떨어뜨려서, 논문에서는 채택되지 않았다. pre-training에서 학습된 relative position bias는 bi-cubic 보간을 통해 다른 window 크기로 fine-tuning을 위한 모델을 초기화하는 데에도 사용할 수 있다.
2-3. Architecture Variants
논문에서는 base model을 Swin-B로 부르고, model의 크기와 계산 복잡도를 ViT-B와 DeiT-B와 유사하게 만들었다. 논문에서느 또한 Swin-T, Swin-S와 Swin-L을 소개하였다. 이 버전들은 각각 Swin-B에 비해 0.25배, 0.5배, 그리고 2배의 model 크기와 계산 복잡도를 각각 가진다. window의 크기는 기본적으로 $M=7$로 설정되고, 각 MLP의 expansion layer는 $\alpha=4$로 설정된다. architecture의 hyper-parameter은 다음과 같이 설정된다.
- Swin-T: $C=96$, layer numbers $= {2,2,6,2}$
- Swin-S: $C=96$, layer numbets $= {2,2,18,2}$
- Swin-B: $C=128$, layer numbers $= {2,2,18,2}$
- Swin-L: $C=192$, layer numbers $= {2,2,18,2}$
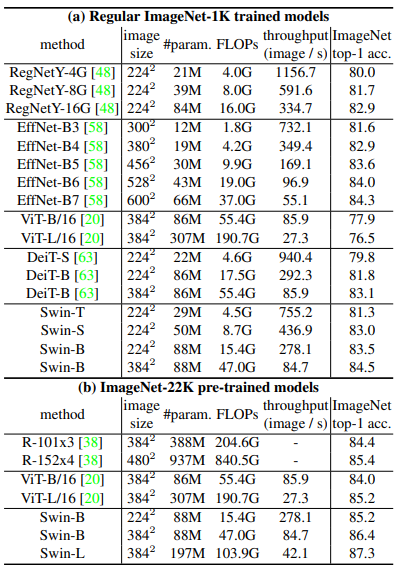
여기서 $C$는 첫 번째 stage에서 hidden layer의 채널 수이다. 모델의 크기, FLOPs, ImageNet image classification을 위한 model variants의 처리량은 표 1에 나타나 있다.
3. Conclusion
Swin Transformer에서 사용된 가장 특징적인 방법은 shifted windows, relative position bias, different self-attention methods이다. 이들을 사용함으로써 어떠한 이익을 얻게 되었는지 살펴보겠다.
Shifted winodws
shifted winodw partitioning과 함께하는 Swin Transformer는 각 스테이지에서 single winodw partioning을 하는 모델보다 더 좋은 성능을 보여줬다. 결과는 shifted window를 사용하여 window 간의 connection을 구축하는 것이 효과적이라는 것을 보여주었다. 그리고 shifted window의 latency overhead 또한 작았다.
Relative position bias
서로 다른 position embedding을 사용하는 접근법들을 비교해보았다. relative position bias를 사용하는 Swin-T는 absolute position encoding을 사용하는 다른 모델보다 더 나은 성능을 보여줬다. absolute position encoding은 image classification의 분야에서 향상된 성능을 보여주지만, object detection과 semantic segementation에서는 성능에 해를 끼쳤다.
현재의 ViT와 DeiT 모델은 visual modeling에 오랫동안 중요한 것으로 나타났음에도 불구하고, 이미지 분류에서 변환 불변성을 포기하였지만, 특정 변환 불변성을 조장하는 inductive bias는 general-purpose visual modeling, 특히 object detection 및 semantic segmentation의 조밀한 예측 작업에 여전히 선호된다.
Different self-attention methods
논문에서의 cyclic 응용은 기존의 padding보다 하드웨어 적으로 효율적이다. 특히, 더욱 깊은 스테이지에 대해서는 더욱 효과적이다. 전반적으로, cyclic 응용은 Swin-T, Swin-B, Swin-B에 대해서 각각 13%, 18%, 18%의 속도 향상을 보여줬다.
제안된 shifted window에서 세워진 self-attention 모듈은 sliding window 방식에서 만들어진 self-attention 모듈보다 훨씬 효율적이었고, 훨씬 빨랐다.
주관적 생각
shifted window는 window 같의 connection을 학습함으로써 detection과 segmentation에 대한 성능 향상에 도움이 되었다. 그리고, relative position bias는 dense prediction의 성능을 향상시켰다.
참고문헌
https://arxiv.org/abs/2103.14030
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as
arxiv.org
https://www.youtube.com/watch?v=2lZvuU_IIMA
'Paper Reading 📜 > Computer Vision' 카테고리의 다른 글
The overview of this paper
이 논문에서는 새로운 vision Transformer인 Swin Transformer을 제안하였다. 이 Swin Transformer는 computer vision에 대해 general-purpose 척추같은 역할을 한다. 시각적 특성의 다양한 scale과 text에 비해 고해상도인 이미지와 같은 computer vision과 NLP 두 영역의 차이 때문에, Transformer을 computer vision에 적용시키는데 많은 문제가 있었다. 이러한 차이점을 극복하기 위해, 논문에서는 representation이 Shifted Windows와 함께 계산되는 hierarchical Transformer을 제안하였다. shifted windowing 기법은 self-attention 계산을 겹치지 않는 로컬 윈도우로 제한하는 동시에 윈도우 간의 연결을 허용함으로써 더욱 뛰어난 효율성을 제공하였다. hierarchical architecture는 다양한 scale에 대해 모델링하는 것에 대해 유연성을 가지고, 이미지의 크기에 대해 선형 계산 복잡도를 가지고 있다. 이러한 Swin Transformer의 퀄리티는 다양한 분야의 vision task와 성능을 나란히 할 수 있게 해주었다.
Table of Contents
1. Introduction
2. Method
2-1. Overall Architecture
2-2. Shifted Windows based Self-Attention
2-3. Architecture Variants
3. Conclusion
1. Introduction
computer vision 분야에서는 AlexNet이 혁명적인 성능을 보여주면서부터 CNN이 꽉 잡게 되었다. CNN architecture는 발전에 발전을 거듭해 강력한 성능을 얻어낼 수 있었다. 이러한 CNN을 토대로 하는 여러 방법들은 다양한 분야의 computer cision task에 대해 좋은 성능을 보여주었다.
이와는 반대로, NLP에서 network의 진화는 다른 경로를 밟았는데, 오늘날에 가장 많이 사용되는 방법은 Transformer이다. 이 Transformer는 sequence modeling과 transduction task를 위해 발명되었고, attention을 사용함으로써 문서 내에서 long-range dependency를 가진다. Transformer의 NLP분야에서 이러한 엄청난 성공은 연구자들로 하게끔, Transformer을 NLP 분야 외에 computer vision 분야에도 적용시킬 수 있지 않을까 하는 연구 동기를 불러 일으켰다.
이 논문에서는 CNN이 computer vision 분야에서 척추를 담당하고 있는 것처럼, Transformer를 어떠한 computer vision 분야든 간에 적용시킬 수 있도록 만들고자 하였다. 논문에서는 NLP분야에서 Transformer의 높은 성능을 computer vision 분야로 변환하는 것에 많은 어려움을 느꼈다. 왜냐하면 두 modaltiry 사이에는 많은 차이점이 존재하기 때문이다. word token이 기본적 요소로 사용된 NLP분야에서의 Transformer와 달리, computer vision에서는 상당한 scale을 입력으로 요구하는 것과 같은 문제도 있다. 기존의 Transformer 기반의 모델에서, 토큰은 모두 고정된 크기이고, 이것은 computer vision에는 부적합한 특성이다. 또다른 차이점은 text와 달리 image는 고해상도의 픽셀로 이루어져 있다. semantic segmentation 같은 visual task는 픽셀 레벨에서의 dense prediction을 요구하고, 이것은 고해상도의 이미지에서 Transformer을 다루기 힘들다는 것은 얘기한다. 왜냐하면 self-attention의 계산 복잡도는 이미지 사이즈의 quadratic이기 때문이다. 이러한 문제점을 해결하기 위해, 논문에서는 Swin Transformer을 제안하였다. 이것은 계층형 피쳐맵을 구성하고 이미지 크기에 대해 선형 게산 복잡도를 가진다. 그림 1의 a에서 묘사되어 있는 것처럼, Swin Transformer는 작은 크기의 patch로부터 시작해서 점차적으로 이웃의 patch들을 합쳐가면서 깊어지는 Transformer layer을 사용함으로써, 계층형 representation을 구성하였다. 선형 계산 복잡도는 이미지를 분할하는 겹치지 않는 창 $($빨간색 윤곽선$)$ 내에서 로컬로 self-attention을 계산하여 달성된다. 각 윈도우에서 patch의 수는 고정되고, 따라서 복잡도는 이미지의 크기에 선형이다. 이러한 장점은 Swin Transformer가 다양한 visual task에 대해 적합한 general-purpose backbone 역할을 한다. 이전의 Transformer 기반 architecture는 하나의 resolution에 대해 quadratic의 복잡도를 가지기 때문에 general-purpose하지 못 했지만, Swin Transformer는 가능하다.
Swin Transformer의 중요한 요소는 그림 2에서 묘사되고 있는, 연속되는 self-attention 간의 window partition의 shift이다. shifted window는 이전 레이어의 window를 이으면서, 이들 사이에 모델의 파워를 향상시키는 connection을 제공한다. 이러한 전략은 또한 real-wordl latency에 대해서 효율적이다. window 내의 모든 query patch는 하드웨어의 메모리 액세스를 용이하게 해주는 key set를 공유한다. 이와는 반대로, 이전의 sliding winodw 기반의 self-attention 기법들은 서로 다른 key set와 quety pixel 때문에 general 하드웨어에서 low latency를 경험하였다. 논문의 실험들은 제안된 shifted window 방식이 sliding window와 비슷한 modeling power에 낮은 latency를 가진다는 것을 보여주었다. shifted window 방식은 또한 모든 MLP architecture에 대해 유리함을 증명하였다.
2. Method
2-1. Overall Architecture
Swin Transformer의 architecture에 대한 개요는 다음의 그림 3에 나타나있다. 그림 3은 Swin Transformer의 tiny 버전을 묘사하고 있다.
처음에, 입력 RGB 입력 이미지를 ViT와 같은 patch splitting module을 활용하여 non-overlapping patch로 나눈다. 각 patch는 'token'처럼 다뤄지고, feature은 raw pixel RGB 값의 concatenation set이다. 논문의 활용에서는, $4 \times 4$ 크기의 patch를 사용하였고, 그래서 각 patch의 feature 차원은 $4 \times 4 \times 3=48$이다. 선형 임베딩 레이어는 이 raw-valued feature을 임시의 차원으로 project하기 위해 적용된다.
modified self-attentuon과 함께 다양한 Transformer block은 이러한 patch token에 적용된다. Transformer block은 token의 수를 $(\frac{H}{4} \times \frac{W}{4})$로 유지하고, 선형 임베딩과 함께 이 모든 것을 'Stage 1'로 명명하였다.
계층형 representation을 생성하기 위해, token의 수는 patch merging layer에 의해 줄어들면서 network는 점점 더 깊어져 간다. 첫 번째 patch merging 레이어는 $2 \times 2$의 이웃 patch들의 각 그룹을 concatenate하고, 4C 차원 연결된 피처에 선형 레이어를 적용한다. 이것은 토큰의 수를 $2 \times 2=4 (2 \times$ resolution의 downsampling$)$에 의해 줄어들고, 출력 차원은 $2C$로 정해진다. Swin Transformer block은 $\frac{H}{8} \times \frac{W}{8}$로 유지되는 해상도로 feature transformation을 위해 나중에 적용된다. patch emerging의 첫 번째 블로과 feature transformation은 "Stage 2"로 나타나있다. 이 과정이 두 번 반복되면, 각각 출력 해상도가 $\frac{H}{16} \times \frac{W}{16}$인 "Stage 3"과 $\frac{H}{32} \times \frac{W}{32}$인 "Stage 4"로 나타내게 된다. 이러한 stage는 공동으로 계층형 representation을 다른 CNN network에서 보통 사용하는 feature map resolution과 함께 수행한다. 그 결과, 제안된 architecture은 손쉽게 다양한 visual task에 존재하는 backbone network를 대체할 수 있다.
Swin Transformer block
Swin Transformer은 기존의 multi-head self attention$($MSA$)$ 모듈을 다른 레이어는 모두 그대로 유지하고, shifted windows 기반의 Transformer block으로 대체함으로써 지어졌다. 그림 3의 b에서 묘사되는 것처럼, Swin Transformer block은 shifted windows 기반의 MSA 모듈로 구성되고, 2 MLP layer 사이에 GELU 비선형성이 적용되는 형태로 계속된다. Layer Normalization$($LN$)$은 각 MSA module과 MLP module 이전에 적용되고, residual connection은 각 모듈의 이후에 적용된다.
2-2. Shifted WIndow based Self-Attention
기존의 Transformer architecture과 이것의 image classification에 대한 적용 모두는 토큰과 모든 다른 토큰의 관계가 계산되는 global self-attention으로 수행된다. global computation은 토큰의 수에 대하여 quadratic한 복잡성을 갖게 하고, 이것은 기존의 Transformer architecture가 dense prediction을 위한 다양한 token을 요구하거나 고해상도 이미지를 표현하는 다양한 vision task에 부적합하게 만든다.
Self-attention in non-overlapped windows
효율적인 모델링을 위해, 논문에서는 local window 안에서 self-attention을 계산하는 것을 제안하였다. window들은 non-overlapping 방식으로 이미지를 균등하게 분할하도록 배열한다. 각 window가 $M \times M$의 patch를 포함한다고 가정하면, global MSA module과 window 기반의 이미지 위의 $h \times w$의 patch의 계산 복잡도는 다음의 수식 1과 같다.
전자는 patch 수 $hw$에 대해 quadratic하고, 후자는 $M$이 고정될 때 선형적이다. global self-attention computation은 일반적으로 큰 $hw$에 대해 너무 많은 비용이 들지만, window 기반의 self-attention은 계산 가능하다.
Shifted window partitioning in successive blocks
window 기반의 self-attention module은 window 사이에 connection이 부족한데, 이것은 modeling power을 감소시킨다. non-overlapping window의 효율적인 computation을 유지하면서 cross-window connection을 소개하기 위해서, 논문에서는 연속된느 Transformer block에서의 두 개의 partitioning 구성을 바꾸는 shifted window partitioning 접근법을 제안하였다.
그림 2에 나타나있는 것처럼, 첫 번쨰 모듈은 top-left 픽셀부터 시작하고, $8 \time 8$의 피쳐맵이 $4\times 4$ zmrldml $2 \times 2$ window로 분할되는 기존의 일반적인 window partitioning 전략이 사용되었다. 그런 다음에, 다음 모듈은 규칙적으로 분할된 창에서 $(\left \lfloor \frac{M}{2} \right \rfloor,\left \lfloor \frac{M}{2} \right \rfloor)$ 픽셀만큼 창을 대체하여 이전 계층의 구성에서 이동된 창 구성을 채택한다.
shifted window 분할 접근법과 함께, 연속된 Swin Transformer block들은 다음과 같이 계산된다.
여기서 $\hat{\textbf{z}}^{l}$과 $\textbf{z}^{l}$는 $($S$)$-MSA 모듈과 MLP block의 $l$번째 블록에 대한 출력을 의미한다. W-MSA와 SW-MSA는 일반적인 window partitioning과 shifted winodw partitioning을 사용하는 window 기반의 multi-head self-attention을 나타낸다. 한 마디로, W-MSA는 기존의 window partitioning이고, SW-MSA는 shifed window partitioining을 의미한다.
shifted window partitioning 접근법은 이전 레이어에서 인접한 non-overlapping window 사이의 연결을 도입하고 image classification, object detection 및 sementic segmentation에 효과적인 것으로 밝혀졌다.
Efficient batch somputation for shifted configuration
shifted window partitioning의 문제점은 shifted 구조에서 $\left \lceil \frac{h}{M}\right \rceil \times \left \lceil \frac{w}{M}\right \rceil$로부터 $(\left \lceil \frac{h}{M}\right \rceil+1) \times (\left \lceil \frac{w}{M}\right \rceil+1)$까지 더 많은 window를 결과를 내놓는 것이고, 어떤 window는 $M \times M$보다 작을 것이다. 해결책은 작은 window를 $M \times M$ 크기의 window로 padding하고, 계산할 때 padding된 값을 mask로 씌우는 것이다. 일반적인 partitioning에서 window의 수가 적을 때, 예를 들어서 $2 \times 2$일 때, 해결책에 의한 증가된 계산량은 상당하다. $(2 \times 2 \to 3 \times 3$은 2.25배 더욱 많다$)$ 여기서 더욱 효율적인 batch caomputation 접근법을 top-left 방향에서 cyclic-shifting을 하는 것으로 제안하였다. 이에 대한 설명은 다음의 그림 4에 나타나 있다. 이러한 shift 이후에, batched window는 서로 인접해있지 않은 피쳐맵의 다양한 sub-window로 구성될 것이다. 그래서, 각 sub-window 내에서 self-attention 계산을 제한하기 위해 masking mechanism이 사용된다. cyclic-shift을 하고 나면, batched window의 수는 일반적인 window partitioning을 하고 난 후의 window 수와 똑같아지고, 따라서 이것은 효율적이다.
Relative position bias
self-attention을 계산할 때, 논문에서는 유사성 계산에서 각 head에 대한 relative position bias $B\in \mathbb{R}^{M^{2} \times M^{2}}$를 포함하여 따른다.
여기서 $Q,K,V\in \mathbb{R}^{M^{2} \times d}$는 query, key, value 행렬이다. $d$는 query와 key의 dimension이고, $M^{2}$은 window의 patch의 수이다. 각 축을 따른 relative position은 범위 $[-M+1,M-1]$에 있기 때문에, 논문에서는 smaller-sized bias 행렬 $\hat{B}\in \mathbb{R}^{(2M-1)\times(2M-1)}$를 파라미터화 하였고, value $B$는 $\hat{B}$로부터 얻어지게 된다.
논문에서는 상당한 성능의 향상을 보여줬다. 입력에 absolute position embedding을 추가하는 것은 성능을 살짝 떨어뜨려서, 논문에서는 채택되지 않았다. pre-training에서 학습된 relative position bias는 bi-cubic 보간을 통해 다른 window 크기로 fine-tuning을 위한 모델을 초기화하는 데에도 사용할 수 있다.
2-3. Architecture Variants
논문에서는 base model을 Swin-B로 부르고, model의 크기와 계산 복잡도를 ViT-B와 DeiT-B와 유사하게 만들었다. 논문에서느 또한 Swin-T, Swin-S와 Swin-L을 소개하였다. 이 버전들은 각각 Swin-B에 비해 0.25배, 0.5배, 그리고 2배의 model 크기와 계산 복잡도를 각각 가진다. window의 크기는 기본적으로 $M=7$로 설정되고, 각 MLP의 expansion layer는 $\alpha=4$로 설정된다. architecture의 hyper-parameter은 다음과 같이 설정된다.
- Swin-T: $C=96$, layer numbers $= {2,2,6,2}$
- Swin-S: $C=96$, layer numbets $= {2,2,18,2}$
- Swin-B: $C=128$, layer numbers $= {2,2,18,2}$
- Swin-L: $C=192$, layer numbers $= {2,2,18,2}$
여기서 $C$는 첫 번째 stage에서 hidden layer의 채널 수이다. 모델의 크기, FLOPs, ImageNet image classification을 위한 model variants의 처리량은 표 1에 나타나 있다.
3. Conclusion
Swin Transformer에서 사용된 가장 특징적인 방법은 shifted windows, relative position bias, different self-attention methods이다. 이들을 사용함으로써 어떠한 이익을 얻게 되었는지 살펴보겠다.
Shifted winodws
shifted winodw partitioning과 함께하는 Swin Transformer는 각 스테이지에서 single winodw partioning을 하는 모델보다 더 좋은 성능을 보여줬다. 결과는 shifted window를 사용하여 window 간의 connection을 구축하는 것이 효과적이라는 것을 보여주었다. 그리고 shifted window의 latency overhead 또한 작았다.
Relative position bias
서로 다른 position embedding을 사용하는 접근법들을 비교해보았다. relative position bias를 사용하는 Swin-T는 absolute position encoding을 사용하는 다른 모델보다 더 나은 성능을 보여줬다. absolute position encoding은 image classification의 분야에서 향상된 성능을 보여주지만, object detection과 semantic segementation에서는 성능에 해를 끼쳤다.
현재의 ViT와 DeiT 모델은 visual modeling에 오랫동안 중요한 것으로 나타났음에도 불구하고, 이미지 분류에서 변환 불변성을 포기하였지만, 특정 변환 불변성을 조장하는 inductive bias는 general-purpose visual modeling, 특히 object detection 및 semantic segmentation의 조밀한 예측 작업에 여전히 선호된다.
Different self-attention methods
논문에서의 cyclic 응용은 기존의 padding보다 하드웨어 적으로 효율적이다. 특히, 더욱 깊은 스테이지에 대해서는 더욱 효과적이다. 전반적으로, cyclic 응용은 Swin-T, Swin-B, Swin-B에 대해서 각각 13%, 18%, 18%의 속도 향상을 보여줬다.
제안된 shifted window에서 세워진 self-attention 모듈은 sliding window 방식에서 만들어진 self-attention 모듈보다 훨씬 효율적이었고, 훨씬 빨랐다.
주관적 생각
shifted window는 window 같의 connection을 학습함으로써 detection과 segmentation에 대한 성능 향상에 도움이 되었다. 그리고, relative position bias는 dense prediction의 성능을 향상시켰다.
참고문헌
https://arxiv.org/abs/2103.14030
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as
arxiv.org
https://www.youtube.com/watch?v=2lZvuU_IIMA