
The overview of this paper
Transformer architecture는 NLP 분야에서 매우 권위적이다. 하지만, 이를 computer vision에 사용하는 예는 극히 제한되어 있다. convolutional network의 사이에 attention을 사용하거나, convolutional network의 전반적인 구성을 바꾸긴 하지만, 절대 전반적인 구조를 바꾸지는 않는다. 논문에서는 이러한 CNN에 의존할 필요 없이 image의 patch에 직접적으로 Transformer를 적용하는 것이 더 좋은 성능을 보여줬다. 거대한 양의 이미지 데이터에서 pre-train을 하고, 이미지 벤치마크에 적용한 결과, Vision Transformer$($ViT$)$는 더욱 적은 계산 비용으로 SoTA에 견줄만한 성능을 보여줬다.
Table of Contents
1. Introduction
2. Method
2-1. Vision Transformer$($ViT$)$
2-2. Fine-tuning and Higher Resolution
3. Pre-training data requirements
1. introduction
Self-attention 기반의 architecture인, Transformer는 NLP 분야에서 주로 사용되는 방법이다. Transformer의 주된 접근법은 거대한 text corpus에서 pre-train을 하고, 작은 task-specific한 데이터셋에 대해 fine-tuning을 거친다. Transformer의 이러한 computational efficiency와 scalability 덕분에, 전례없는 크기의 모델을 학습시킬 수 있었다. 모델의 크기와 데이터셋의 크기가 늘어남에도 불구하고 성능의 저하는 없었다.
computer vision에서는 아직 CNN이 우세하다. NLP에서의 성공에 영감을 받아 여러 연구들이 CNN-architecture와 self-attention을 결합하기 위해, convolution을 아예 대체하는 방법과 같이 적용하였다. 이는 이론적으로 효율적이지만, 특별화된 attention pattern 때문에 현재의 하드웨어 가속기에 효과적으로 scaling할 수 없다는 문제가 있다. 그래서, large-scale에서의 image recognition은 아직, ResNet과 같은 architecture가 SoTA로 남아있는 것이다.
NLP 분야에서 Transformer의 성공적인 scaling에 영감을 받아 논문에서는 기존의 Transformer와 함께 조금의 수정을 거쳐서 image에 직접적으로 적용해보았다. 이를 위해, image를 patch로 분할하고, 이러한 patch들의 선형 임베딩을 Transformer의 입력으로 주었다. image patch들은 NLP 분야에서 사용되는 token과 유사하게 사용된다.
강력한 regularization 없이 ImageNet 같은 중간 크기의 데이터셋에서 훈련할 때, 이러한 모델은 크기가 비슷한 ResNet보다 조금 더 낮은 성능을 산출하였다. 이것은 예상했던 것보다 실망스러운 결과일 수 있지만, Transformer는 CNN에 비해 inductive bias의 수가 부족하다. 그리고 충분하지 않응 양의 데이터에서는 잘 generalize할 수 없다.
이러한 ViT는 여러 SoTA들에 견줄만한 성능을 내거나, 때로는 능가하는 모습을 보여줬다.
2. Method
모델의 디자인에서, 논문에서는 최대한 기존의 Transformer를 따르고자 하였다. 이렇게 간단한 셋업의 장점은 scalable란 Transformer architecture을 사용함으로써 효율적인 응용을 가능하게 만들었다. 다음은 ViT의 전반적인 구조이다.
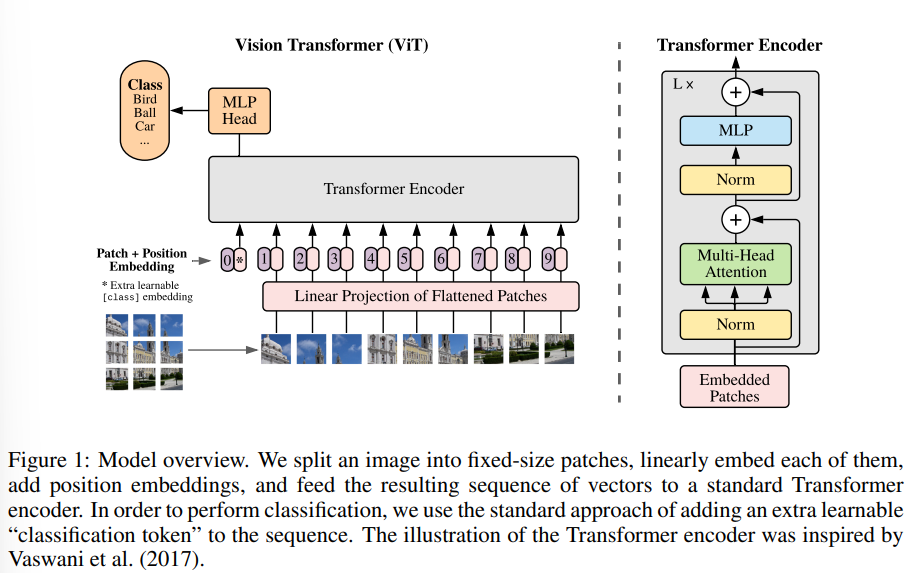
2-1. Vision Transformer$($ViT$)$
위의 그림 1에서 묘사된 모델의 전반적인 개요는 다음과 같다. 기존의 Transformer가 token embedding의 1차원적 sequence를 입력으로 받는다. 2차원의 image를 처리하기 위해, 논문에서는 image $\textbf{x} \in \mathbb{R}^{H \times W \times C}$를 납작해진 patch $\textbf{x}_{p}$으로 reshape한다. 여기서 $(H,W)$는 기존의 이미지의 resolution이고, $C$는 채널의 수이고, $(P,P)$는 각 이미지 패치의 resolution이고, $N=HW/P^{2}$으로 결과의 패치 수로, 이것은 Transformer을 위한 효과적인 입력 시퀀스의 길이로 여겨진다. Transformer는 변함없는 잠재적인 벡터의 크기인 $D$를 모든 레이어에 대해서 사용해서, 논문에서는 patch를 납작하게 만들고, 학습 가능한 선형 프로젝션과 함께 차원 $D$와 매핑한다. 논문에서는 이 과정을 통해 생성된 출력을 patch embedding이라고 부른다.
BERT의 [class] 토큰과 유사하게, Transformer encoder의 출력 상태$(z^{0}_{L})$가 이미지 표현 $y$ 역할을 하는 임베디드 패치 시퀀스 $(z^{0}_{0}=\textbf{x}_{class})$에 학습 가능한 임베딩을 추가한다 $($수식 4$)$. pre-training과 fine-tuning 중에, classification head는 $\textbf{z}^{0}_{L}$에 부착된다. classification head는 pre-training에서 MLP와 하나의 hidden layer와 fine-tuning에서 하나의 선형 레이어로부터 응용된다.
Position embedding은 positional 정보를 얻기 위해 patch embedding에 추가된다. 논문에서는 기존의 학습 가능한 1차원 position embedding을 사용했는데, 왜냐하면 논문에서는 더욱 개선된 2D-aware position embedding을 사용함으로써 상당한 성능 개선을 확인하지 못했기 때문이다. 임베딩 벡터의 결과 시퀀스는 인코더의 입력으로 여겨졌다.
Transformer의 인코더는 multihead self-attention과 MLP block이 번갈아 나타나는 레이어로 구성되어 있다. Layer Normalization$($LN$)$은 모든 블록의 이전에 적용되었고, residual connection이 모든 블록 이후에 적용되었다 $($수식 2, 3$)$. MLP는 두 개의 비선형성 GELU를 포함하고 있다. 다음은 ViT의 구조 수식이다.
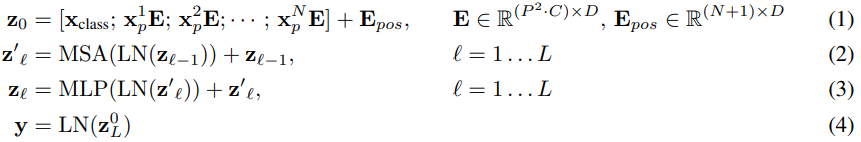
inductive bias
Vision Transformer는 CNN에 비해 더욱 적은 image-specific inductive bias를 가지고 있다. CNN에서는, 지역성과 2차원 이웃 구조 및 변환 등가가 전체 모델의 각 계층에 적용된다. ViT에서는, 오직 MLP layer가 지역적이고, 변환 등가하지만, self-attention은 global하다. 2차원 이웃 구조는 매우 드물게 사용된다. 모델 시작 시에, 이미지를 패치로 자르고, fine-tuning 시간에 다른 해상도의 이미지에 대한 positional embedding을 조정한다. 다른 것보다도, 초기에는 position embedding이 patch의 2차원 position에 대해 어떠한 정보를 전달하지 않고, patch간의 모든 spatial relation은 밑바닥에서부터 학습되어야 한다.
Hybrid Architecture
포기의 이미지 patch에 대한 대안으로, 입력 시퀀스는 CNN의 피쳐맵으로부터 형성될 수 있다. 이러한 hybrid model에서는, patch embedding projection $\textbf{E}$가 CNN의 피쳐맵으로부터 뽑아낸 patch에 대해 적용된다 $($수식 1$)$. 특수한 경우로 패치의 공간 크기는 1x1일 수 있다. 즉, 단순히 피쳐맵의 spatial dimension을 평면화하고 Transformer dimenstion에 투영하여 입력 시퀀스를 얻는다. 분류 입력 embedding과 position embedding은 위에서 언급된 것처럼 추가된다.
2-2. Fine-tuning and Higher Resolution
보통, ViT는 큰 규모의 데이터셋에서 학습되고, 작은 downstream task에 fine-tuning 된다. 이를 위해, 논문에서는 pre-trained prediction head를 제거하고, zero-initialized $D \times K$ feedforward layer를 붙였다. 여기서 $K$는 downstream class의 수이다. 이것은 pre-training 하는 것보다 higher resolution에서 fine-tuning 하는 것이 더 유익하다는 것을 자주 보여준다. higher resolution의 image를 feed할 때, 논문에서는 patch의 크기를 똑같이 유지하였는데, 이것은 더욱 효과적인 시퀀스 길이를 얻을 수 있게 해줬다. Vision Transformer는 임의의 시퀀스 거리를 다룰 수 있지만, pre-trained position embedding은 더 이상 의미가 없을 수도 있다. 따라서 원본 이미지의 위치에 따라 pre-trained된 position embedding의 2D 보간을 수행합니다. 이 resolution 조정 및 patch 추출은 이미지의 2차원 구조에 대한 inductive bias가 수동으로 Vision Transformer에 주입되는 유일한 지점이다.
Vision Transformer는 CNN과 달리 많은 pre-training을 요구한다. 왜냐하면, CNN과 달리 Vision Transformer는 inductive bias가 부족하기 때문이다. CNN은 image-specific한 inductive bias가 많이 있어서 굳이 pre-training을 해야할 필요가 없다. 하지만, Transformer는 modality가 뛰어나기 때문에 inductive bias가 부실해서 pre-training이 필요하다.
3. Pre-training data requirements
Vision Transformer는 거대한 JFT-300M 데이터셋에서 pre-train될 때, 잘 수행되었다. ResNet보다 시각적 inductive bias가 적다면 데이터셋의 크기는 얼마나 중요할까? 그래서 논문에서는 두 가지의 실험을 진행하였다.
첫 번째로, 논문에서는 ViT 모델을 증가된 크기의 데이터셋에 대해서 pre-train하였다. 더 작은 데이터셋에서 성능을 향상시키기 위해, 논문에서는 weight decay, dropout, label smoothing 이렇게 세 개의 일반적인 regularization parameter을 optimize하였다. 가장 작은 데이터셋에서 pre-train을 진행하였을 때, ViT-Base 모델에 비해 ImageNet과 ViT-Large 모델은 regularization에도 불구하고 뒤쳐진 성능을 보여줬다. ImageNet-21k의 pre-training과 함께, 이들의 성능은 비슷했다. 오직 JFT-300M과 함께 했을 때, larger model의 모든 이익을 볼 수 있었다.
두 번째로, 논문에서는 model을 full JFT-300M 뿐만 아니라 랜덤한 서브셋 9M, 30M, 90M으로 학습하였다. 논문에서는 smaller 데이터셋에 대해서 추가적인 regularization을 수행하지 않고, 모든 세팅에 대해 똑같은 하이퍼 파라미터를 사용하였다. 이런 방법으로, 논문에서는 고유 모델 속성을 평가하고 정규화의 효과를 평가하지 않았다. 하지만, early-stopping을 사용하면 훈련에서 최고의 검증 정확도를 보여줬다.
ViT은 smaller dataset에서 overfitting이 된다. 적은 데이터에서는 CNN의 inductive bias가 더욱 유용하였고, 반면에 많은 데이터에서는 Transformer처럼 relevant pattern을 학습하는 방법이 효과적이다.
참고문헌
https://arxiv.org/abs/2010.11929
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org
'Paper Reading 📜 > Computer Vision' 카테고리의 다른 글
The overview of this paper
Transformer architecture는 NLP 분야에서 매우 권위적이다. 하지만, 이를 computer vision에 사용하는 예는 극히 제한되어 있다. convolutional network의 사이에 attention을 사용하거나, convolutional network의 전반적인 구성을 바꾸긴 하지만, 절대 전반적인 구조를 바꾸지는 않는다. 논문에서는 이러한 CNN에 의존할 필요 없이 image의 patch에 직접적으로 Transformer를 적용하는 것이 더 좋은 성능을 보여줬다. 거대한 양의 이미지 데이터에서 pre-train을 하고, 이미지 벤치마크에 적용한 결과, Vision Transformer$($ViT$)$는 더욱 적은 계산 비용으로 SoTA에 견줄만한 성능을 보여줬다.
Table of Contents
1. Introduction
2. Method
2-1. Vision Transformer$($ViT$)$
2-2. Fine-tuning and Higher Resolution
3. Pre-training data requirements
1. introduction
Self-attention 기반의 architecture인, Transformer는 NLP 분야에서 주로 사용되는 방법이다. Transformer의 주된 접근법은 거대한 text corpus에서 pre-train을 하고, 작은 task-specific한 데이터셋에 대해 fine-tuning을 거친다. Transformer의 이러한 computational efficiency와 scalability 덕분에, 전례없는 크기의 모델을 학습시킬 수 있었다. 모델의 크기와 데이터셋의 크기가 늘어남에도 불구하고 성능의 저하는 없었다.
computer vision에서는 아직 CNN이 우세하다. NLP에서의 성공에 영감을 받아 여러 연구들이 CNN-architecture와 self-attention을 결합하기 위해, convolution을 아예 대체하는 방법과 같이 적용하였다. 이는 이론적으로 효율적이지만, 특별화된 attention pattern 때문에 현재의 하드웨어 가속기에 효과적으로 scaling할 수 없다는 문제가 있다. 그래서, large-scale에서의 image recognition은 아직, ResNet과 같은 architecture가 SoTA로 남아있는 것이다.
NLP 분야에서 Transformer의 성공적인 scaling에 영감을 받아 논문에서는 기존의 Transformer와 함께 조금의 수정을 거쳐서 image에 직접적으로 적용해보았다. 이를 위해, image를 patch로 분할하고, 이러한 patch들의 선형 임베딩을 Transformer의 입력으로 주었다. image patch들은 NLP 분야에서 사용되는 token과 유사하게 사용된다.
강력한 regularization 없이 ImageNet 같은 중간 크기의 데이터셋에서 훈련할 때, 이러한 모델은 크기가 비슷한 ResNet보다 조금 더 낮은 성능을 산출하였다. 이것은 예상했던 것보다 실망스러운 결과일 수 있지만, Transformer는 CNN에 비해 inductive bias의 수가 부족하다. 그리고 충분하지 않응 양의 데이터에서는 잘 generalize할 수 없다.
이러한 ViT는 여러 SoTA들에 견줄만한 성능을 내거나, 때로는 능가하는 모습을 보여줬다.
2. Method
모델의 디자인에서, 논문에서는 최대한 기존의 Transformer를 따르고자 하였다. 이렇게 간단한 셋업의 장점은 scalable란 Transformer architecture을 사용함으로써 효율적인 응용을 가능하게 만들었다. 다음은 ViT의 전반적인 구조이다.
2-1. Vision Transformer$($ViT$)$
위의 그림 1에서 묘사된 모델의 전반적인 개요는 다음과 같다. 기존의 Transformer가 token embedding의 1차원적 sequence를 입력으로 받는다. 2차원의 image를 처리하기 위해, 논문에서는 image $\textbf{x} \in \mathbb{R}^{H \times W \times C}$를 납작해진 patch $\textbf{x}_{p}$으로 reshape한다. 여기서 $(H,W)$는 기존의 이미지의 resolution이고, $C$는 채널의 수이고, $(P,P)$는 각 이미지 패치의 resolution이고, $N=HW/P^{2}$으로 결과의 패치 수로, 이것은 Transformer을 위한 효과적인 입력 시퀀스의 길이로 여겨진다. Transformer는 변함없는 잠재적인 벡터의 크기인 $D$를 모든 레이어에 대해서 사용해서, 논문에서는 patch를 납작하게 만들고, 학습 가능한 선형 프로젝션과 함께 차원 $D$와 매핑한다. 논문에서는 이 과정을 통해 생성된 출력을 patch embedding이라고 부른다.
BERT의 [class] 토큰과 유사하게, Transformer encoder의 출력 상태$(z^{0}_{L})$가 이미지 표현 $y$ 역할을 하는 임베디드 패치 시퀀스 $(z^{0}_{0}=\textbf{x}_{class})$에 학습 가능한 임베딩을 추가한다 $($수식 4$)$. pre-training과 fine-tuning 중에, classification head는 $\textbf{z}^{0}_{L}$에 부착된다. classification head는 pre-training에서 MLP와 하나의 hidden layer와 fine-tuning에서 하나의 선형 레이어로부터 응용된다.
Position embedding은 positional 정보를 얻기 위해 patch embedding에 추가된다. 논문에서는 기존의 학습 가능한 1차원 position embedding을 사용했는데, 왜냐하면 논문에서는 더욱 개선된 2D-aware position embedding을 사용함으로써 상당한 성능 개선을 확인하지 못했기 때문이다. 임베딩 벡터의 결과 시퀀스는 인코더의 입력으로 여겨졌다.
Transformer의 인코더는 multihead self-attention과 MLP block이 번갈아 나타나는 레이어로 구성되어 있다. Layer Normalization$($LN$)$은 모든 블록의 이전에 적용되었고, residual connection이 모든 블록 이후에 적용되었다 $($수식 2, 3$)$. MLP는 두 개의 비선형성 GELU를 포함하고 있다. 다음은 ViT의 구조 수식이다.
inductive bias
Vision Transformer는 CNN에 비해 더욱 적은 image-specific inductive bias를 가지고 있다. CNN에서는, 지역성과 2차원 이웃 구조 및 변환 등가가 전체 모델의 각 계층에 적용된다. ViT에서는, 오직 MLP layer가 지역적이고, 변환 등가하지만, self-attention은 global하다. 2차원 이웃 구조는 매우 드물게 사용된다. 모델 시작 시에, 이미지를 패치로 자르고, fine-tuning 시간에 다른 해상도의 이미지에 대한 positional embedding을 조정한다. 다른 것보다도, 초기에는 position embedding이 patch의 2차원 position에 대해 어떠한 정보를 전달하지 않고, patch간의 모든 spatial relation은 밑바닥에서부터 학습되어야 한다.
Hybrid Architecture
포기의 이미지 patch에 대한 대안으로, 입력 시퀀스는 CNN의 피쳐맵으로부터 형성될 수 있다. 이러한 hybrid model에서는, patch embedding projection $\textbf{E}$가 CNN의 피쳐맵으로부터 뽑아낸 patch에 대해 적용된다 $($수식 1$)$. 특수한 경우로 패치의 공간 크기는 1x1일 수 있다. 즉, 단순히 피쳐맵의 spatial dimension을 평면화하고 Transformer dimenstion에 투영하여 입력 시퀀스를 얻는다. 분류 입력 embedding과 position embedding은 위에서 언급된 것처럼 추가된다.
2-2. Fine-tuning and Higher Resolution
보통, ViT는 큰 규모의 데이터셋에서 학습되고, 작은 downstream task에 fine-tuning 된다. 이를 위해, 논문에서는 pre-trained prediction head를 제거하고, zero-initialized $D \times K$ feedforward layer를 붙였다. 여기서 $K$는 downstream class의 수이다. 이것은 pre-training 하는 것보다 higher resolution에서 fine-tuning 하는 것이 더 유익하다는 것을 자주 보여준다. higher resolution의 image를 feed할 때, 논문에서는 patch의 크기를 똑같이 유지하였는데, 이것은 더욱 효과적인 시퀀스 길이를 얻을 수 있게 해줬다. Vision Transformer는 임의의 시퀀스 거리를 다룰 수 있지만, pre-trained position embedding은 더 이상 의미가 없을 수도 있다. 따라서 원본 이미지의 위치에 따라 pre-trained된 position embedding의 2D 보간을 수행합니다. 이 resolution 조정 및 patch 추출은 이미지의 2차원 구조에 대한 inductive bias가 수동으로 Vision Transformer에 주입되는 유일한 지점이다.
Vision Transformer는 CNN과 달리 많은 pre-training을 요구한다. 왜냐하면, CNN과 달리 Vision Transformer는 inductive bias가 부족하기 때문이다. CNN은 image-specific한 inductive bias가 많이 있어서 굳이 pre-training을 해야할 필요가 없다. 하지만, Transformer는 modality가 뛰어나기 때문에 inductive bias가 부실해서 pre-training이 필요하다.
3. Pre-training data requirements
Vision Transformer는 거대한 JFT-300M 데이터셋에서 pre-train될 때, 잘 수행되었다. ResNet보다 시각적 inductive bias가 적다면 데이터셋의 크기는 얼마나 중요할까? 그래서 논문에서는 두 가지의 실험을 진행하였다.
첫 번째로, 논문에서는 ViT 모델을 증가된 크기의 데이터셋에 대해서 pre-train하였다. 더 작은 데이터셋에서 성능을 향상시키기 위해, 논문에서는 weight decay, dropout, label smoothing 이렇게 세 개의 일반적인 regularization parameter을 optimize하였다. 가장 작은 데이터셋에서 pre-train을 진행하였을 때, ViT-Base 모델에 비해 ImageNet과 ViT-Large 모델은 regularization에도 불구하고 뒤쳐진 성능을 보여줬다. ImageNet-21k의 pre-training과 함께, 이들의 성능은 비슷했다. 오직 JFT-300M과 함께 했을 때, larger model의 모든 이익을 볼 수 있었다.
두 번째로, 논문에서는 model을 full JFT-300M 뿐만 아니라 랜덤한 서브셋 9M, 30M, 90M으로 학습하였다. 논문에서는 smaller 데이터셋에 대해서 추가적인 regularization을 수행하지 않고, 모든 세팅에 대해 똑같은 하이퍼 파라미터를 사용하였다. 이런 방법으로, 논문에서는 고유 모델 속성을 평가하고 정규화의 효과를 평가하지 않았다. 하지만, early-stopping을 사용하면 훈련에서 최고의 검증 정확도를 보여줬다.
ViT은 smaller dataset에서 overfitting이 된다. 적은 데이터에서는 CNN의 inductive bias가 더욱 유용하였고, 반면에 많은 데이터에서는 Transformer처럼 relevant pattern을 학습하는 방법이 효과적이다.
참고문헌
https://arxiv.org/abs/2010.11929
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org