Fine-tuning method의 발전 과정!! Fine-tuning부터 RLHF까지 🦖➡️🧑
A new spectrum of model learning, Fine-tuning ✨
이번 포스팅에서 다뤄보고자 하는 내용은 모델의 fine-tuning 방식에 대해서이다. 사실 포스팅의 순서가 무언가 잘못되었다는 사실을 느끼고 있기는 한데, 그 점은 양해를 부탁한다..!! 😅 저번 시간에 파라미터 효율적인 fine-tuning을 알아보면서 fine-tuning을 효율적으로 하는 방법에 대해 알아봤는데, 그렇다면 fine-tuning을 좀 더 효과적으로 할 수 있는 방법은 없을까? 당연히 있다!! 이번 포스팅에서는 fine-tuning method가 어떻게 변화 해나갔는지에 대해 알아보고자 한다.
자, 그렇다면 fine-tuning이 무엇일까? 저번 포스팅에서 말했던 것처럼 지금의 수많은 language model들은 pre-training & fine-tuning이라는 방식을 주로 사용하고 있다. 수많은 양의 데이터에서 pre-training을 거치고 나온 모델에 pre-training 때보다는 훨씬 더 적은 양의 domain-specific한 데이터를 활용해서 모델의 파라미터를 재조정해나가며 학습시키는 방법을 fine-tuning이라 한다. 😊 그렇다면 안 그래도 비교적 짧은 fine-tuning을 좀 더 효과적으로 할 수 있는 방법은 없을까? 이와 같은 고민을 통해 나온 method들이 in-context learning, instruction-tuning, RLHF 같은 방식들이다.
Original Fine-tuning method (GPT & BERT)🏆
앞서 말한 것처럼 지금의 많은 모델들은 pre-training & fine-tuning method를 사용하고 있다. 그렇다면 이 pre-training & fine-tuning mechanism은 어디서 처음 소개되었을까? NLP를 접해본 사람이라면 안 들어본 적이 없을 정도로 유명한 모델인 GPT와 BERT로부터 처음 소개되었다! 🥳 GPT의 논문인 'Improving Language Understanding by Generative Pretraining(2018)'과 BERT의 논문인 'Bidirectional Encoder Representations from Transformers(2018)'에서는 각각 다음과 같은 방식으로 fine-tuning을 수행하였다.
- GPT(Generative Pretraining Transformer): 단방향 Transformer Decoder architecture를 사용하여 문장을 생성하는 LM으로, 많은 양의 텍스트 데이터로부터 pre-train하고, 이를 기반으로 다양한 language task에서 fine-tuning을 수행하였음.
- BERT(Bi-directional Encoder Representation Transformer): 양방향으로 문맥을 학습하는 Transformer Encoder architecture로 pre-trained model을 사용하여 다양한 자연어 처리 task에서 fine-tuning을 수행함.
이렇게 글로만 보면 제대로 이해가 가질 않으니 각 논문에서 소개한 그림들과 함께 보면서 좀 더 자세히 이해해보자. 먼저 GPT 논문에서 소개된 그림부터 봐보도록 하자. 이 그림이 딱히 GPT의 pre-training & fine-tuning mecahnism을 보여주기 위한 그림은 아니지만, 대강 그와 비슷한 느낌은 받을 수 있는 그림이기에 한 번 살펴보려고 한다! 😊 아래 사진의 왼쪽 부분에서는 GPT 모델의 architecture를 보여주고 있고, 오른쪽에서는 각 task에 따른 서로 다른 형태의 input을 보여주고 있다. 이렇듯 여러 자연어 데이터에서 학습을 거친 뒤 특정 task에 대해서 다시 학습을 함으로써 파라미터를 재조정하는 과정을 fine-tuning이라 하는 것이다! 🤩
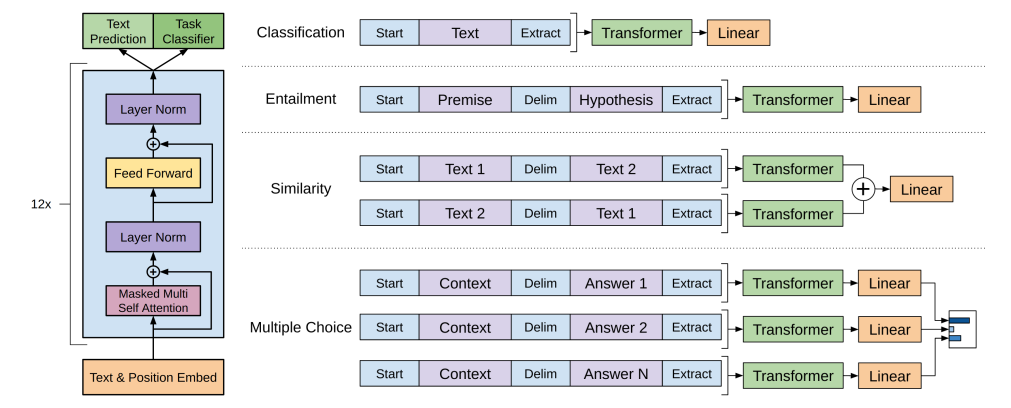
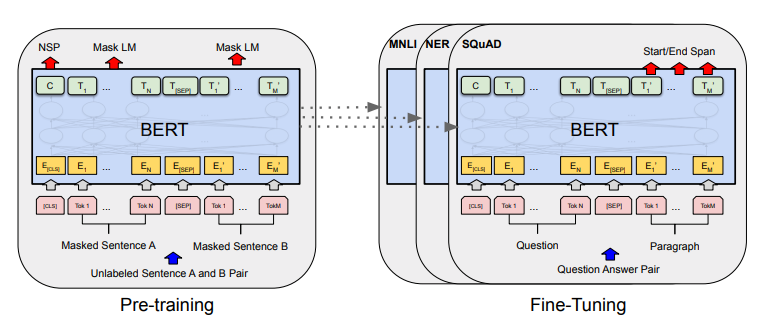
BERT의 fine-tuning은 GPT의 fine-tuning과 상당히 유사한데... 가 아니라 사실 fine-tuning 자체는 거의 모든 모델에 대해서 비슷한 모양새를 갖춘다. fine-tuning 하는 task와 모델 architecture에 따라서 조금조금씩의 차이점을 가질 뿐이지, 그 뼈대 자체는 바뀌지 않는다. 그래도 BERT의 fine-tuning을 살펴보면 다음의 그림과 같다. GPT의 fine-tuning과 마찬가지로 pre-trained model을 특정 task 데이터를 활용하여 fine-tuning 시키는 방식으로 모델의 파라미터를 재조정해나가는 방식이다! 😊
GPT와 BERT에 대해서 더욱 자세한 내용이 궁금하다면 다음의 리뷰를 확인하길 바랍니다! 😉
In-context Learning (GPT-2 & GPT-3) 📃
original fine-tuning의 뒤를 이은 fine-tuning 방식은 바로 in-context learning이다. in-context learning은 GPT-2를 소개한 논문 'Language Models are Unsupervised Multitask Learners(2019)'에서 처음 소개되었다. 이 in-context learning은 특정 작업을 수행할 때 주어진 문맥을 고려하고 이해하여 더 나은 성능을 이끌어낼 수 있도록 하는 방식이다. in-context learning을 하는 방식은 어렵지 않은데 task에 대한 task에 대한 예시를 입력으로 함께 주면 된다. 😄 (n-shot learning에 따라서 예시를 주는지 안 주는지는 달라집니다!)
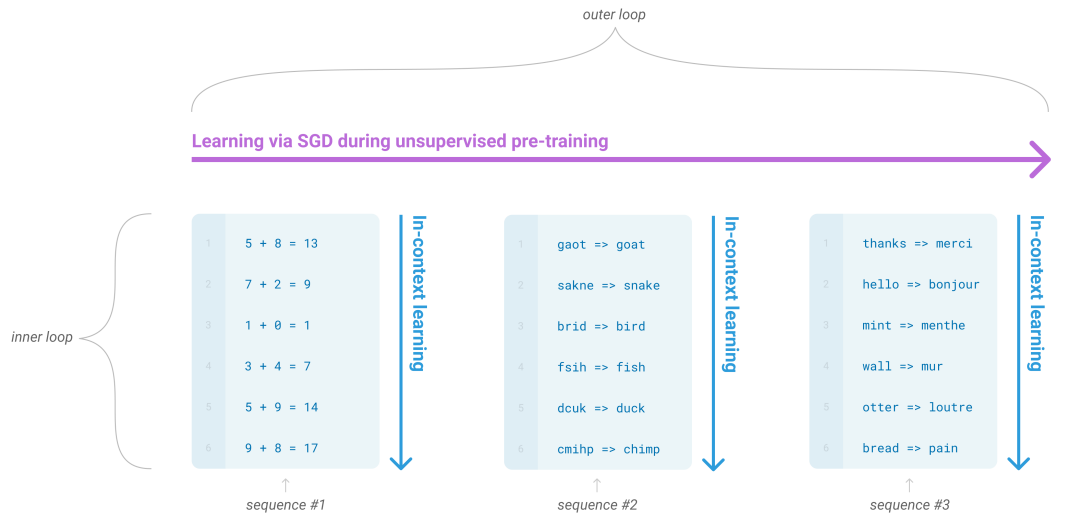
In-context Learning은 모델에게 주어지는 example의 수에 따라서 부르는 이름이 달라지게 되는데, 우선 GPT-2에서는 unsupervised learning을 사용하였기 때문에 자연스레 zero-shot learning을 사용하였다. 이를 토대로 다음과 같이 이름 붙일 수 있다!
- Zero-shot Learning: example의 수가 0인 in-context learning 0️⃣
- One-shot Learning: example의 수가 1인 in-context learning 1️⃣
- Few-shot Learning: example의 수가 1보다는 많지만 적은 수인 in-context learning 🤏
GPT-2의 후속 모델인 GPT-3의 논문 'Language Models are Few-shot Learners(2020)' 에서는 GPT-2의 zero-shot learning에서 벗어나 few-shot learning을 선보이며 본격적인 in-context learning의 문을 열었다! 🚪 GPT-2와 GPT-3에서 선보인 in-context learning은 아직까지도 많은 language model들의 학습 방식으로 굳건하게 자리를 매김하고 있다.
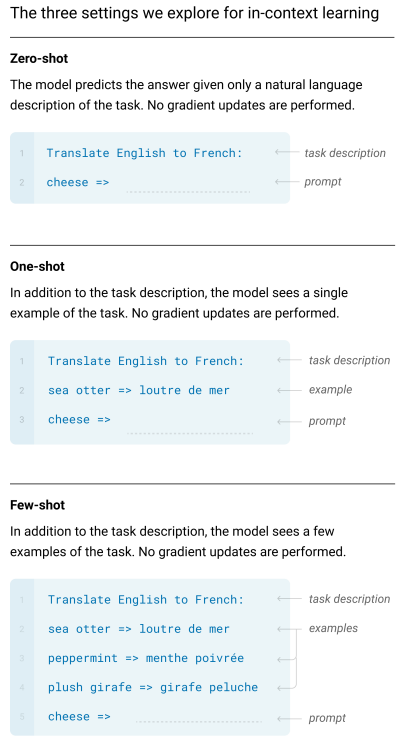
위의 그림을 보면 알 수 있듯이 기본적으로 in-context learning은 task description이 주어지고, 최종적으로 모델로부터 output을 얻기 위한 input인 prompt가 함께 주어진다. 그리고 zero-shot, one-shot, few-shot에 따라서 그에 걸맞은 example들이 주어짐으로써 모델은 이를 참고해 output을 출력해 내는 것이다.
그렇다면 과연 몇 개의 자연어를 포함한 prompt를 추가하는 in-context learning은 좋은 효과를 보여줄 수 있었을까? 결과부터 말하자면,, 그렇다!! 다음의 GPT-3 실험 결과를 보면 알 수 있듯이 in-context learning을 통해 확실히 더 개선된 성능을 얻을 수 있었고, one-shot의 경우에는 자연어 prompt가 있을 때와 없을 때 상당한 성능 차이를 보여줬다! 😲
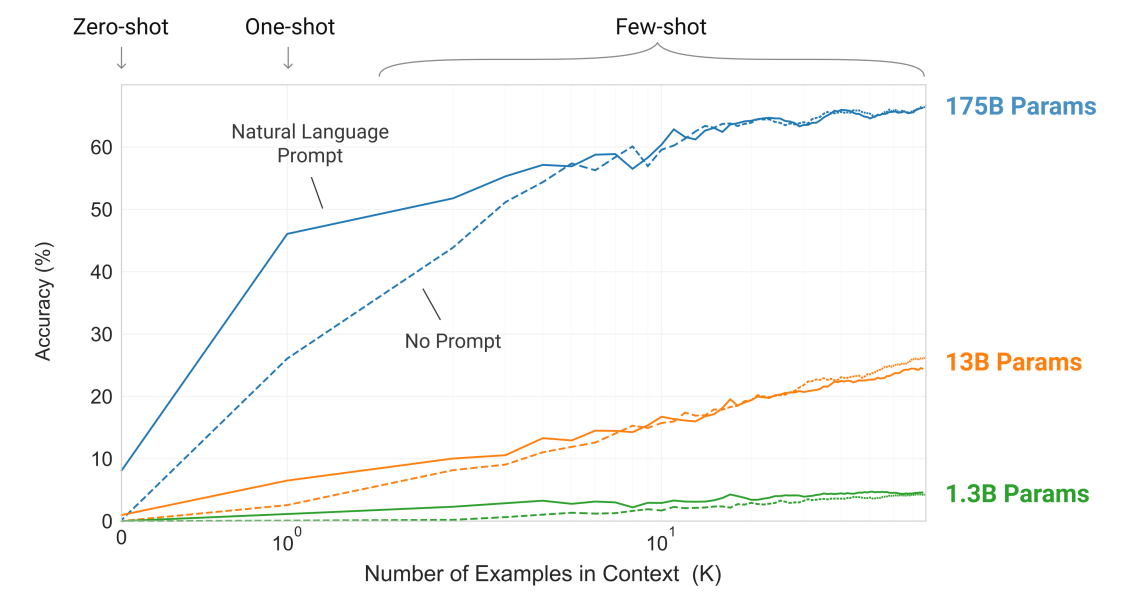
이번 섹션에서 알아본 in-context learning은 fine-tuning을 대체할 완전히 새로운 방법은 아니고, 기존의 fine-tuning에 부가적으로 자연어 prompt를 추가하여 좀 더 효과적인 방법을 제안한 것이다. 따라서 이러한 방식은 fine-tuning이라기 보다는 prompt-tuning에 더 가깝다고 볼 수 있다. in-context learning을 통해 prompt-tuning의 효과를 알게 되고, 나중에 prompt-tuning을 통해 LM의 성능을 개선시키고자 한 많은 논문들이 나오게 되었다. (궁금하다면 이 포스팅을 확인해보시길!) 그리고 이러한 in-context learning은 향후에 제안된 instruction-tuning의 발판이 되어주었다! 😉
GPT-2와 GPT-3에 대해서 더욱 자세한 내용이 궁금하다면 다음의 리뷰를 확인하길 바랍니다! 😉
Instruction-tuning (FLAN) 📝
앞서 설명한 original fine-tuning method는 상당히 효과적인 모습을 보여줬고, 여기에 추가적으로 prompting을 거친 in-context learning은 기존의 fine-tuning에 비해 좀 더 개선된 성능을 보여줬다. 하지만, 이 method들을 보면 한 가지 공통점을 가지고 있는데, 그것은 바로 test를 수행할 task의 데이터를 활용하여 fine-tuning을 하였다는 것이다. 그렇다면 만약 fine-tuning 시에 target task에 대해서 학습을 하지 않고도 target task를 수행할 수 있게 된다면 어떨까? '이건 또 무슨 뚱딴지같은 소리지? fine-tuning은 target task에 대해서 추가적으로 학습함으로써 target task를 더 잘 수행할 수 있게 도와주는 방법이라고 지금까지 설명한 거 아니야?'라고 생각할 수도 있겠지만, 우리의 LM은 우리의 생각보다 훨씬 더 유능하기에 이것이 가능하다!
위에서 말한 이런 능력을 얻기 위해서 제안된 방법이 Instruction-tuning이다. 이 instruction-tuning은 구글에서 소개한 모델인 FLAN을 소개한 논문 'FLAN: Finetuned Language Models Are Zero-Shot Learners(2021)' 에서 처음 소개되었다. 그렇다면 이 instruction-tuning은 자세하게 무엇인 걸까? FLAN 논문에 있는 기존 fine-tuning과 in-context learning, instruction-tuning 비교 그림을 보면서 한 번 파악해 보도록 해보자! 😋
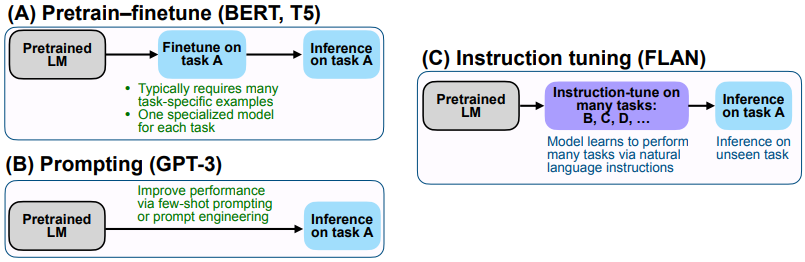
먼저 기존의 fine-tuning 방식은 target task에 대해서 fine-tuning을 거침으로써 LM의 target task에 대한 능력을 기르는 방식이다. 두 번째로 Prompting(in-context learning)은 few-shot prompting과 prompt engineering을 통해 target task에 대해서 추론을 할 수 있게 도와준다. 마지막으로 instruction-tuning은 target task가 아닌 다른 task들에 대해서 instruction + input + output 데이터를 활용하여 tuning 함으로써 target task에 대해 추론할 수 있게 해 준다. 한 마디로 여러 task를 수행함으로써 target task를 수행할 수 있는 능력을 기를 수 있게 해주는 방식인 것이다. FLAN에서 제안한 instruction-tuning 방식에 대해서 다음 그림을 통해 더욱 자세하게 알아보도록 하자.

instruction-tuning 이름에 걸맞게 task에 대한 instruction, input, target을 제공하고, 이 데이터들에 대해 학습을 하는 방식으로 instruction-tuning은 진행된다. 그렇다면 이렇게 target task와 다른 task에 대한 instruction, input, target 데이터를 활용해서 학습시킨다고 해서 모델의 성능이 정말 향상되었을까? 그 정답은 다음의 그림을 보면 알 수 있을 것이다! 😊
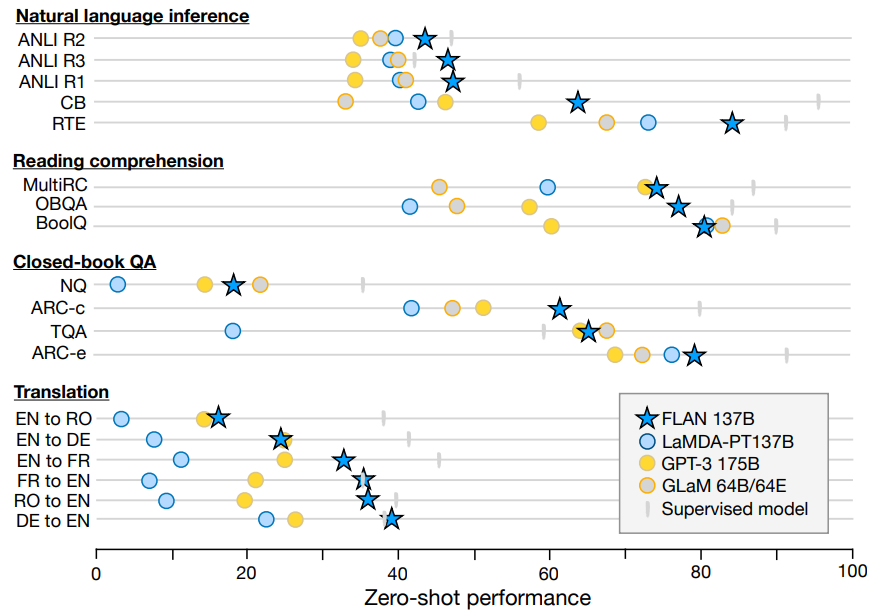
위 그림을 보면 FLAN의 instruction-tuning은 확실히 효과적인 method라는 것을 알 수 있다. 현재는 기존의 fine-tuning에서 벗어나 instruction-tuning을 많이 사용하는 추세이다. (ex. Alpaca, WizardLM, etc.) FLAN에 대해 더욱 자세한 내용이 궁금하다면 다음의 리뷰를 확인하시길 바랍니다!
Reinforcement Learning from Human Feedback(RLHF) 🧑🏫
지금까지는 LM에게 기본적인 상식을 가르치는 느낌이었다면, 이번에 알아보고자 하는 RLHF는 살짝 다른 목표를 가지고 모델을 학습시키는 방식이다. RLHF를 풀어서 써보면 'Reinforcement Learning from Human Feedback', 즉 사람의 피드백으로부터 강화학습을 하는 것이다. 기존의 fine-tuning method들은 사람의 간섭없이 모델 스스로 학습한 것에 반해, RLHF는 사람의 피드백을 필요로 한다. 왜 그래야 했던 걸까? 그것은 바로 RLHF가 모델이 채팅에 더욱 특화되도록 만들기 위한 방법이기 때문이다.
RLHF를 처음으로 소개하고 발전된 과정을 살펴보면 더 많은 논문들이 존재하는데 가장 유명하게 알려져 있는 ChatGPT 직전의 모델인 InstructGPT을 소개한 논문인 'Training language models to follow instructions with human feedback(2022)'에 대해서 얘기해보며 RLHF에 대해 얘기해보고자 한다. InstructGPT에서 사용된 RLHF의 프로세스는 다음의 그림과 같다.
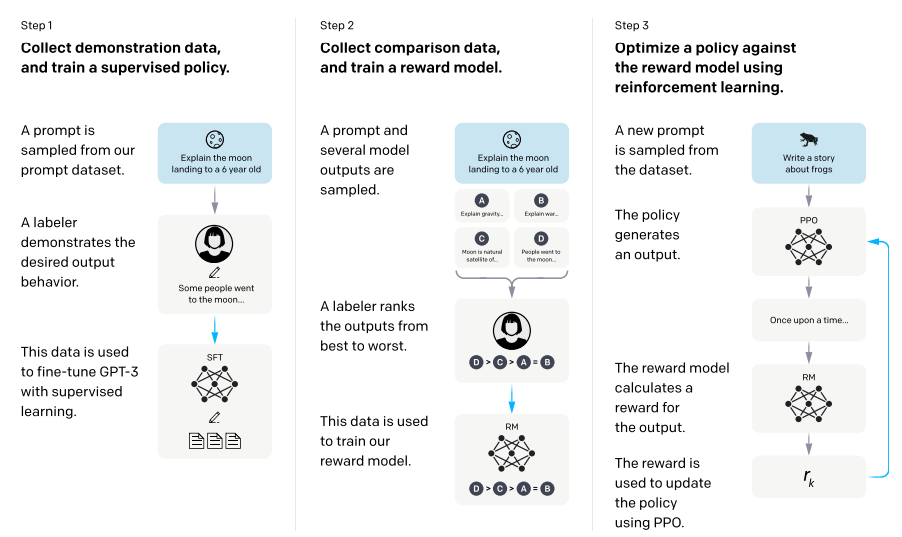
InstructGPT의 전체적인 RLHF 프로세스를 설명하면 다음과 같다.
- SFT: labeler로부터 prompt에 대한 answer를 수집하고, 이 데이터를 이용해서 모델을 지도 학습함.
- Reward Modeling: 하나의 prompt에 대해 여러 모델들의 output을 수집하고, 이 output을 labeler들이 평가하게 하여, 이 평가 데이터를 활용해 reward model을 학습시킴.
- RL with PPO: policy가 output을 생성하고, 학습된 reward model은 output에 대한 reward를 계산한 뒤, 이 reward와 PPO를 활용하여 policy를 업데이트함.
과정이 복잡하게 느껴질 수도 있지만, 다시 생각해 보면 결국, 사람의 피드백을 통해 학습된 reward model을 활용하여 모델의 output에 reward를 매기고, 이 reward를 PPO를 활용하여 policy 업데이트에 사용하는 방식으로 모델이 더 나은 output을 내놓을 수 있도록 학습시키는 방법이다. 따라서 당연하게도 RLHF를 거친 모델은 채팅 능력이 훨씬 더 우수한데, 이는 사람이 reward model을 학습시키는 과정에서 피드백을 제공할 때, 좀 더 잘 만들어진 output에 대해 높은 reward를 부여하기 때문이다. 이렇게 완벽해 보이는 RLHF에도 단점이 있었으니,, 일단 RLHF를 거친 모델들의 공통적인 특징은 benchmark에서는 성능이 떨어진다는 점이다! 😥 이러한 문제를 Alignment Problem이라 칭한다. 실제로 RLHF model과 일반 SFT 모델의 benchmark 성능을 보면 비슷하거나, 오히려 더 떨어지는 성능을 보여주기도 한다. 물론 human preference와 benchmark 둘 중 무엇이 더 중요한 가냐에 따라서 다르게 가치 판단이 가능하겠지만, 이 두 마리 토끼를 모두 잡을 수 있는 방법이 개발되길 바라는 마음이다. 🥲
RLHF와 InstructGPT에 대해 더욱 자세한 내용이 궁금하다면 다음 리뷰를 확인해주시길 바랍니다!
What should be the next step of Fine-tuning? 🧐
이 포스팅의 마지막을 장식할 이 섹션의 제목은 어찌보면 잘못됐을 수도 있다. 어떻게 현재의 필자가 미래를 예측하고 그렇게 되어야만 한다고 말하는 것은 잘못됐을 수도 있으나, 만약 RLHF와 instruction-tuning이 미래의 fine-tuning 판도를 이끌어나갈 method라고 한다면 그렇게 틀린 말도 아니라고 생각한다. 이 둘은 명확한 한계를 가지기 때문이다! 두 method는 목표로 하는 방향이 살짝은 다른데, 하나는 모델이 benchmark에서 좋은 성능을 낼 수 있게 하는 것이 목적이고, 다른 하나는 모델이 채팅에 더욱 특화되도록 돕는 것이 목적이다. 따라서 이 둘은 alignment problem을 가지는데, 이 말인즉슨, benchmark 성능과 채팅 능력, 이 두 마리 토끼를 함께 잡지 못하고 있다는 것이다.
RLHF와 instruction-tuning이 이러한 문제를 가지는 한 앞으로 나아가야 할 방향은 명확하다고 필자는 생각한다. 이 alignmnet problem을 해결할 수 있는 방향으로 나아가야 한다고 생각한다! 🔥 물론 정확히 어떤 방식으로 해야하는지는 필자도 잘 모르지만, alignmnet problem을 해결하고, 더 나은 performance를 보여주는 fine-tuning method가 개발되기를 진심으로 바라며 포스팅을 마친다. 이 포스팅을 끝까지 읽어주신 모든 분들께 감사드립니다. 🙇