
Why I read this paper?
지난 번 포스트에서 다뤘던 DistilBERT에 대해서 자세히 공부하던 중 이 DistilBERT의 메인이 되는 Knowledge Distillation에 대해서 더욱 자세하게 알아보고자 Knowledge Distillation에 대해 처음으로 소개한 이 논문을 찾아 읽게 되었다. 이 Knowledge Distillation은 현재 신경망 모델들의 문제점인 급격하게 증가하는 파라미터 수로 인한 모델의 용량 문제를 완화시켜 줄 수 있는 방법으로 조금의 성능 손실이 있긴 해도 획기적인 시간 절약을 보여줬다. 본 포스트는 기존의 포스트들과는 다르게 좀 더 유연한 전개를 가져가 보고자 한다. $($노력은 했으나, 그렇지 않을 수도 있습니다~ ^^$)$
The overview of this paper
이 논문의 서론에서는 곤충의 '애벌레' 시절에 대해 묘사한다. 곤충은 애벌레 시기를 거치면서 획기적으로 영양분을 섭취하고 성장하게 된다. 이러한 메커니즘을 신경망 모델에도 적용하면 어떨까? 라는 아이디어를 바탕으로 논문은 시작한다. 이러한 개념을 신경망 모델에 적용하게 되면, ensemble model의 지식을 single model이 학습하여 압축된 지식을 갖게하는 것이 더욱 효과적으로 모델을 사용할 수 있게 만들어준다는 것이다. 논문에서는 이러한 지식을 제공하는 모델을 cumbersome model이라 표현하고, 지식을 받아서 학습하는 모델을 그냥 small model이라 표현한다.
Distillation
기존의 신경망 모델들은 신경망을 거쳐서 마지막에 softmax layer을 지나서 최종 출력값에 대해 백분위 값을 가진 다음, one-hot encoding을 통하여 가장 높은 probability를 가지는 class에 대해서만 '1'값을 부여하고, 그렇지 않은 class에게는 모조리 '0'값을 부여한다. 다음의 그림 1이 이 과정을 보여주고 있다.

논문에서는 이와 같이 softmax layer을 거쳐서 마지막 one-hot encoding을 거쳐 나온 값을 'hard target'이라고 부른다. 이 과정을 수식으로 나타내면 다음과 같다.
$q_i=\frac {exp(z_i/T)}{\sum_{j} exp(z_j/T)}$
여기서 처음 보는 변수가 하나 등장하는데, 이 $T$는 Temperature이다. 이 Temperature의 용도는 조금 뒤에서 설명하도록 하겠다. 아무튼 이 $T$가 1값을 가질 때, 이 수식의 결과는 one-hot encoding의 결과가 된다.
다시 본론으로 돌아와서 one-hot encoding의 값을 보면 정답인 class에 대해서만 1값을 가지고 정답이 아닌 class에 대해서는 0값을 가진다. 하지만, softmax function을 거쳐서 나온 값을 보면 정답이 아닌 class에 대해서도 작지만 값을 가지고 있긴 하다. 논문에서는 이 점을 이용하여 cumbersome model로부터 small model을 학습시킬 수 있을 것이라는 제안을 하였다. 예를 들어서, 고양이는 개와 닮았기 때문에 조금이나마 높은 확률을 부여받게 되지만, 소와는 완전히 다른 모습이기 때문에 더욱 낮은 확률을 부여받게 된다. 이러한 정보를 small model이 학습할 수 있게 되면 어떨까? 라는 느낌인 것이다. 이를 위해 논문에서는 'soft target' 즉, softmax function을 통해 나온 결과에 대해 집중한다.

논문에서는 cumbersome model로부터 small model을 학습시키기에 앞서서, 앞서 설명했던 Temperature라는 개념을 사용하였다. 이 Temperature의 역할은 softmax function을 통해 나온 값을 조금 더 smooth하게 만들어준다. 따라서 이 값이 1일 때는 기존의 softmax function과 똑같은 결과를 보여주지만, 이 값이 커지게 되면 softmax function을 통해 나오는 값들 간의 차이가 많이 완화되게 된다.
이제 cumbersome model로부터 어떻게 small model이 학습하는지 알아보자. 여기서 teacher와 student 개념으로 이해하면 알기 쉽다! 당연히 teacher은 cumbersome model 즉, ensemble model이고, student는 small model이 되게 된다. 이러한 구조에서 student가 어떻게 학습하는지는 다음의 그림에 나타나있다.
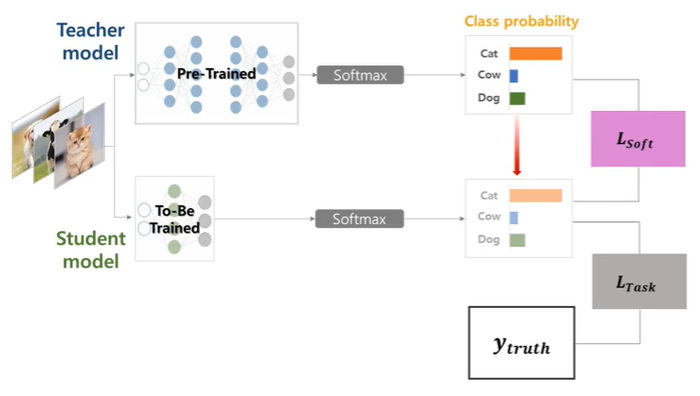
teacher는 사전에 학습되어서 모든 예측값을 가지고 있게 된다. 그 후에 student도 동일한 데이터를 사용하여 학습된 뒤에 최대한 teacher의 예측 분포와 유사하게 예측하도록 학습된다. 그렇게 teacher의 logit 값인 $f_t(x_i)$와, student의 logit 값인 $f_s(x_i)$에 scaling역할의 하이퍼 파라미터인 $T$를 이용하여 다음과 같이 $L_{soft}$의 값을 구할 수 있다.
$L_{soft} = \sum_{x_i\in X} KL(softmax(\frac {f_t(x_i)}{T}), softmax(\frac {f_s(x_i)}{T}))$
그리고 $L_{task}$의 값은 student의 logit값과 실제 값과의 cross entropy를 통해 구할 수 있다.
$L_{task} = CrossEntropy(softmax(f_s(x_i)), y_{truth})$
마지막으로 최종 $L_{total}$은 다음과 같이 구해진다.
$Student$ $L_{total} = L_{task} + \lambda \cdot L_{soft}$
이와 같은 과정을 통해 small model은 big model로부터 지식을 전달받을 수 있게 되는 것이다!! 실제로 이 Knowledge Distillation은 많이 사용되는 기술이다.
참고문헌
https://arxiv.org/abs/1503.02531
Distilling the Knowledge in a Neural Network
A very simple way to improve the performance of almost any machine learning algorithm is to train many different models on the same data and then to average their predictions. Unfortunately, making predictions using a whole ensemble of models is cumbersome
arxiv.org
https://www.youtube.com/watch?v=pgfsxe8sROQ
https://www.youtube.com/watch?v=k63qGsH1jLo
'Paper Reading 📜 > Deep Learning' 카테고리의 다른 글
| Zero-shot, One-shot, Few-shot Learning이 무엇일까? (3) | 2023.03.12 |
|---|---|
| Prompt Engineering이 무엇일까? (0) | 2023.03.01 |
| LSTM vs GRU 뭐가 더 나을까?: Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling 논문 리뷰 (1) | 2023.01.30 |
| 알기 쉽게 LSTM networks 이해하기 (2) | 2023.01.27 |
| CNN network의 역사 (0) | 2022.12.14 |