
얼마 전에 블로그에 구글에서 소개한 PaLM에 대한 리뷰 포스트를 올렸던 기억이 난다. 엄청난 양의 파라미터 수로 인해 깜짝 놀랐던 기억이 나는데, 이제는 이 PaLM이 더욱 multimodal 스러워졌다. 이번 포스트에서는 이제 텍스트를 넘어서 이미지까지도 처리할 수 있는 모델이 되어버린 PaLM-'E'에 대해서 알아보도록 하겠다. 본 포스트는 논문과 구글의 소개 블로그를 참고하여 작성되었다.
The overview of PaLM-E
최근 몇 년 동안 머신 러닝에서는 엄청난 발전을 이룩하였다. 이렇게 발전된 모델들은 조크를 설명하거나 시각적 질문에 응답하는 등의 다양한 언어적 문제를 해결할 수 있게 되었다. 심지어는 텍스트 설명이 주어지면 이미지를 생성해내기도 한다! 😲 이러한 혁신은 큰 데이터셋의 사용성이 늘어나고, 새로운 발전들이 모델이 이러한 데이터셋에서 학습될 수 있게 해줬기 때문에 가능했다고 볼 수 있다. 하지만 robotic model들은 몇몇 성공 사례들을 보이고 있는 반면에, 큰 텍스트 corpora 또는 이미지 데이터셋의 부족으로 다른 도메인에 비해 앞질러 나가고 있어 보이고 있다.
그래서 구글에서 소개한 다양한 시각적 및 언어적 영역으로 얻은 지식을 robotic 시스템에 전달함으로써 이러한 문제를 해결한 다방면으로 뛰어난 robotic model이 바로 PaLM-E이다. PaLM-E는 강력한 LLM인 PaLM을 robotic 에이전트로부터 얻은 센서 데이터로 보완함으로써 "구체화$($embodied$)$"한 것이다. 이것이 기존에 LLM을 robotic으로 가져오려는 시도들과의 가장 큰 차이점이다. 오직 text input에만 의존하기 보다는, PaLM-E을 사용하여 로봇 센서 데이터의 raw stream을 직접 수집하도록 LM을 학습시켰다. 결과로 나온 모델은 로봇 학습에서 뛰어날 뿐만 아니라 일반적인 목적의 visual-language-model에서 훌륭한 language-only task 능력을 유지하면서 SOTA를 달성하였다.
An Embodied language model, and also a visual-language generalist
한편으로 PaLM-E는, robotic을 위한 모델로 개발되었고, 다양한 유형의 로봇과 여러 양식에 대한 다양한 작업을 해결한다. 동시에 PaLM-E는 일반적으로 가능한 vision-language-model이다. PaLM-E는 이미지를 설명하거나 사물을 인식하고, 장면을 분류하는 등의 visual task도 수행 가능하고, 시 인용 또는 수학 방정식을 풀거나 코드를 생성하는 등의 language task도 수행 가능하다.
PaLM-E는 구글에서 가장 최근에 소개한 LLM인 PaLM과 가장 발전된 vision model인 ViT-22B를 결합하였다. 이 방식의 가장 큰 모델은 PaLM-540B로 만들어진 PaLM-E-562B이고, 어떠한 task-specific fine-tuning 없이 visual-language OK-VQA 벤치마크에서 새로운 SOTA를 달성하였다. 그리고 기본적으로 PaLM-540B와 동일한 언어 성능을 유지하였다.
PaLM-E의 주된 contributuon은 다음과 같다.
- embodied 데이터를 multimodal LLM의 학습에 혼합해 범용적 모델, 전이 학습, 다중 구현 의사 결정 에이전트를 교육할 수 있음.
- 현재 SOTA visual-language model은 zero-shot 추론 문제를 잘 다루지 못 함. 하지만, 유능한 범용 visual-language model을 훈련하는 것이 가능함.
- neural scene representation과 entity-labeling multimodal token 같은 새로운 architecture을 제안하였음.
- PaLM-E는 visual과 language과 같이 다방면에 대해서 질적으로 유망한 모습을 보여줌.
- 모델의 크기를 늘리는 것이 적은 catastophic fogetting과 함께 multimodal fine-tuning을 가능하게 함.
How does PaLM-E work?
기술적으로 PaLM-E는 observation을 pre-trained LM에 주입함으로써 작동하였다. 이것은 이미지와 같은 센서 데이터를 LM에 의해 자연어의 단어가 처리되는 것과 비슷한 프로시저로 변환함으로써 실현시킬 수 있었다.
LM은 text를 신경망이 처리할 수 있도록 수학적으로 표현하는 메커니즘에 의존한다. 이것은 먼저 text를 subword를 인코드하는 so-called token으로 분할하여 달성되며, 각 토큰은 숫자의 고차원 벡터, 토큰 임베딩과 연관되어 있다. LM은 수학적 연산$($행렬곱 같은$)$을 결과로 나온 벡터의 시퀀스에 적용해서 다음에 올 것 같은 word token을 예측한다. 그리고 새롭게 예측된 word를 입력으로 넣어서, LM은 반복적으로 더욱 더 긴 text를 생성할 수 있다.
PaLM-E의 입력은 임의의 순서로 된 text 및 기타 양식$($이미지, robot states, scene embedding 등$)$이며, 이를 "multimodal sentences"라고 한다. 예를 들어 입력은 "<img_1>과 <img_2> 사이에 무슨 일이 발생했나요?"의 형태를 띈다. 여기서 <img_1>과 <img_2>는 두 개의 이미지이다. 출력은 PaLM-E에 의해 auto-regressively하게 생성된 text이다. 이것은 질문의 대답일 수도 있고, text form에서 결정의 시퀀스일 수도 있다.
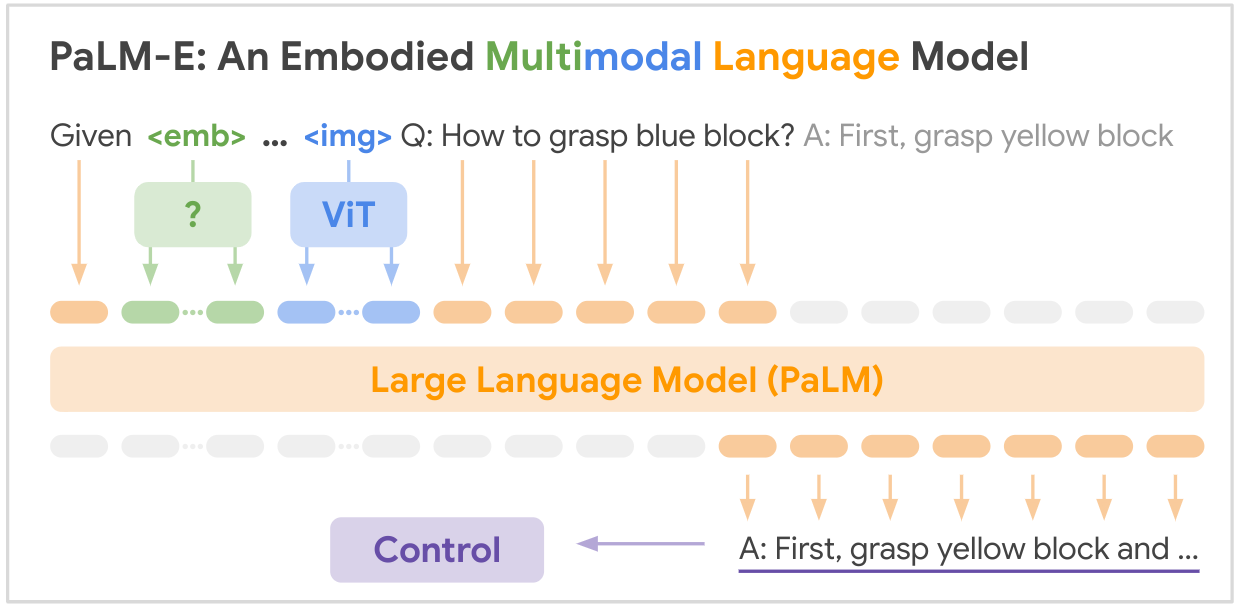
PaLM-E의 아이디어는 다양한 입력을 자연어 단어 토큰 임베딩처럼 똑같은 공간으로 변환하는 encoder를 학습시키는 것이다. 이러한 연속 입력은 "words"와 유사한 것으로 매핑된다. $($비록 이들은 별개의 세트를 형성할 필요가 없음$)$ word와 image embedding 둘은 똑같은 차원을 가지고 있기 때문에, 이들은 LM에 사용될 수 있다.
논문에서는 language(PaLM) 및 vision(ViT) 모두에 대해 pre-trained model을 사용하여 학습을 위해 PaLM-E를 초기화하였다. 모델의 모든 파라미터는 학습 중에 업데이트될 수 있다.
Transferring knowledge from large-scale training to robots
PaLM-E는 다방면으로 뛰어난 모델을 학습시키기 위한 새로운 패러다임을 제공하였다. 이 패러다임은 robot task와 vision-language task를 함께 하나의 일반적인 representation의 틀로 넣음으로써 달성하였다: text와 image를 입력으로 받아서, text를 출력. 중요한 결과는 PaLM-E가 상당한 긍정적인 지식 전달을 vision과 language 영역으로부터 얻었다는 것이다. 이는 로봇 학습의 효과를 향상시켰다.
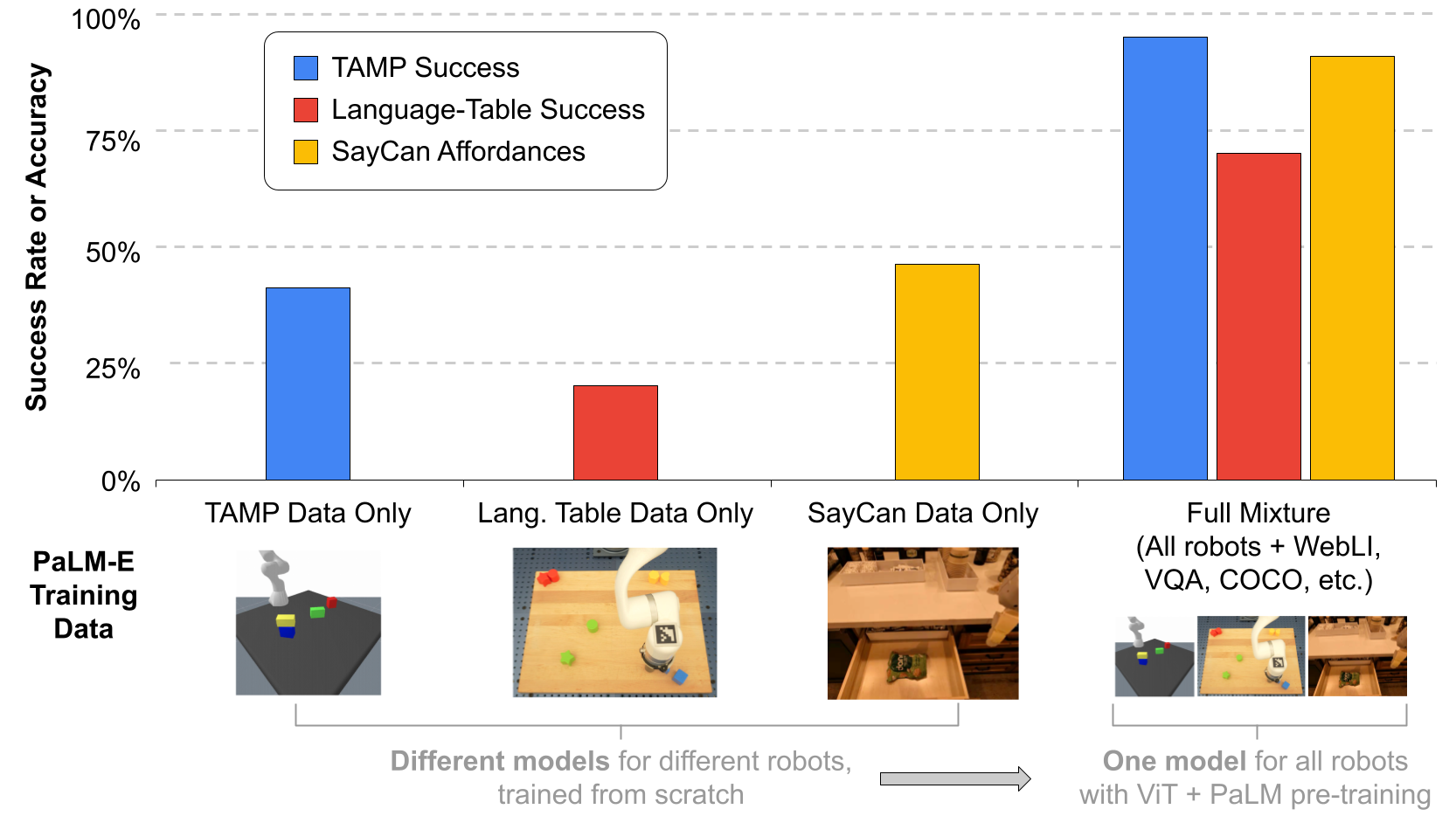
결과들은 PaLM-E가 robotics, vision, language task의 거대한 세트를 각각의 모델을 각각의 task에 대해 학습하는 것에 비하여 성능의 저하 없이 동시에 해결할 수 있었다는 것을 보여주고 있다. 추가적으로, visual-language 데이터는 robot task의 성능을 상당히 향상시킨다. 이러한 전달을 통해 PaLM-E는 task를 해결하는 데 필요한 example 수 측면에서 로봇 작업을 효율적으로 학습할 수 있다.
Results
논문에서는 PaLM-E를 3개의 robotic 환경에서 평가하였고, 그 중에 두 개는 실제 로봇을 포함하고 있다. 뿐만 아니라 visual question answering(VQA), 이미지 캡셔닝, 일반적인 language task 같은 일반적인 vision-language task에 대해서도 평가를 진행하였다. PaLM-E가 로봇에 대한 결정을 내리는 task를 수행할 때 텍스트를 하위 수준의 로봇 동작으로 변환하기 위해 하위 수준 language-visual 정책과 쌍을 이루게 하였다.
아래의 첫 번째 예시는 사람이 모바일 로봇에게 칩 한 봉지를 가져오게 시키는 예시이다. task를 성공적으로 완료하기 위해, PaLM-E는 서랍을 찾고 여는 계획을 세우고 task를 수행하는 것처럼 계획을 업데이트함으로써 세상의 변화에 대응하게 하였다. 두 번째 예시에서는, 로봇에게 초록색 블록을 집게 하였다. 만약 로봇에게 블록이 보이지 않더라도, PaLM-E는 계속 로봇의 학습 데이터를 일반화하는 step-by-step 계획을 생성한다.


아래 그림의 두 번째 환경에서 동일한 PaLM-E 모델은 다른 유형의 로봇에서 "색상별로 블록을 모서리로 정렬"과 같은 매우 길고 정확한 작업을 해결한다. 이것은 이미지를 보고 더 짧은 textually-represented action의 시퀀스를 생성한다. 예를 들어 "파란색 큐브를 아래 오른쪽 코너에 밀어둬라.", "파란색 삼각형도 같이 밀어둬라." 와 같이 말이다. 장기적인 과제는 자율적인 완성의 범위에서 벗어난다. 또한 빨간색 블록을 커피 컵에 밀어넣는 것과 같이 학습 시간 동안 볼 수 없었던 새로운 task$($제로샷 일반화$)$로 일반화하는 능력을 보여준다.


세 번째 로봇 환경은 매우 많은 수의 가능한 행동 순서로 로봇에 직면하는 조합적으로 도전적인 계획 task를 연구하는 task and motion planning$($TAMP$)$의 필드로부터 영감을 받았다. 전문가 TAMP planner로부터 얻은 보통의 양의 학습 데이터를 사용하여 PaLM-E는 이 task를 해결할 뿐만 아니라 또한 보다 효과적으로 수행하기 위해 visual 및 language 지식 전달을 활용한다.


visual-language 다방면에 뛰어난 모델로써 PaLM-E는 최고의 vision-language-only 모델과 비교하여도 경쟁력있는 모델이다. 특히, PaLME-E-562B는 어려운 OK-VQA 데이터셋에 대해 최고의 성능을 기록하였다. 이 task는 시각적 이해 뿐만 아니라 세상의 외부적인 지식도 필요로 한다. 또한 이 결과는 특정 task에 대해서만 fine-tuning하지 않고 일반 모델로 도달하였다.
Conclusion
PaLM-E는 어떻게 generally-capable model이 vision과 language, robotic을 동시에 처리할 수 있도록 학습할 수 있는 방법의 경계를 넓히는 동시에 시각 및 언어에서 robotic 영역으로 지식을 전달할 수 있게 하였다. 논문에는 추가적인 주제들의 디테일에 대해서 다루고 있으니 한 번 확인해보길 바란다.
PaLM-E는 다른 데이터 소스로부터 이점을 얻을 수 있는 더 유능한 로봇을 구축할 수 있는 경로를 제공할 뿐만 아니라 지금까지 분리된 것처럼 보였던 작업을 통합하는 기능을 포함하여 multimodal 학습을 사용하는 다른 광범위한 응용 프로그램에 대한 핵심 enabler가 될 수 있다.
출처
https://arxiv.org/abs/2303.03378
PaLM-E: An Embodied Multimodal Language Model
Large language models excel at a wide range of complex tasks. However, enabling general inference in the real world, e.g., for robotics problems, raises the challenge of grounding. We propose embodied language models to directly incorporate real-world cont
arxiv.org
https://ai.googleblog.com/2023/03/palm-e-embodied-multimodal-language.html
PaLM-E: An embodied multimodal language model
Posted by Danny Driess, Student Researcher, and Pete Florence, Research Scientist, Robotics at Google Recent years have seen tremendous advances across machine learning domains, from models that can explain jokes or answer visual questions in a variety of
ai.googleblog.com