
The overview of this paper
이 논문에서는 광범위한 vision-language task를 모델링하기 위한 간단하고 유연한 프레임워크인 VisualBERT를 제안하였다. VisualBERT는 self-attention을 사용하여 입력 텍스트와 영역의 요소들을 연관된 입력 이미지로 정렬하는 Transformer layer의 스택으로 이루어져 있다. 논문에서는 VisualBERT를 image caption 데이터에서 pre-training 시키기 위해 추가적으로 두 개의 visually-grounded language model 목표를 제안하였다. VQA, VCR, NLVR, Flickr30K 이렇게 4개의 vision-language task에 진행한 실험은 VisualBERT가 간단하면서도 다른 모델들과 비슷한 성능을 보여주거나 때로는 SoTA를 능가한다는 것을 보여주었다.
Table of Contents
1. Introduction
2. A Joint Representation Model for Vision & Language
2-1. Background
2-2. VisualBERT
2-3. Training VisualBERT
3. Experiments
4. Analysis
4-1. Ablation Study
4-2. Qualitative Analysis
1. Introduction
vision과 language를 혼합한 task는 시각 정보 시스템의 추리 능력을 평가하기 위한 좋은 test-bed로 여겨진다. 왜냐하면 이 task를 진행하면서 시스템은 사물, 특징, 부분, 공간적 관계, 행동과 목적 등의 이러한 어떻게 자연어로 참조되고 기반이 되는지 광범위한 디테일적 의미를 이해해야 하기 때문이다.
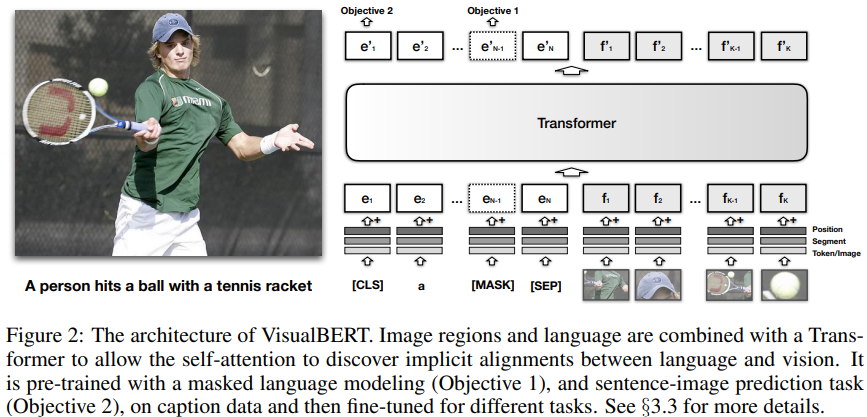
이 논문에서는 이미지와 연관된 텍스트에서 풍부한 의미를 캡처하기 위해 디자인된 간단하고 유연한 모델인 VisualBERT를 제안하였다. VisualBERT는 BERT와 Faster-RCNN을 통합시켰으며 다양한 vision-and-language task에 적용될 수 있다. 특히, 객체 탐지에서 뽑아낸 image feature는 순서가 없는 토큰으로 다뤄져서 text와 함께 VisualBERT로 들어가게 된다. 그리고 입력 텍스트와 이미지는 VisualBERT의 여러 개의 Transformer layer을 사용하여 함께 처리된다$($그림 2. 참고$)$. 단어와 이미지 객체 간의 풍부한 상호작용은 모델이 텍스트와 이미지 간의 복잡한 연관성을 캡처하도록 해준다.
BERT와 유사하게, VisualBERT를 외부 소스에서 pre-training 시키는 것은 downstream 응용에 이익을 가져다 준다. 이미지와 텍스트 간의 연관성을 학습시키기 위해, VisualBERT를 이미지의 디테일한 의미가 자연어로 표현되어 있는 image caption 데이터에서 pre-training 하고자 하였다. 이를 위해 논문에서는 pre-training을 위한 두 개의 visually-grounded language modeling 목표를 제안하였다. 이러한 방식으로 image caption 데이터에서 pre-training을 하는 것이 전파 가능한 text와 visual representation을 학습하기 위한 VisualBERT에 중요하다는 것을 보여줬다.
- text의 일부분이 마스킹되고 남은 text와 visual context를 사용해서 masked word를 예측
- 제공된 text와 image가 일치하는지 판단하도록 하여 학습
앞서 paper overview에서 언급했던 것처럼 VisualBERT는 VQA, VCR, NLVR, Flickr30K task에 대해 실험을 진행하였고, 그 결과 VisualBERT는 이전의 모델들과 비슷하거나 능가하는 성능을 보여줬다. 그리고 VisualBERT의 어떤 부분이 좋은 성능을 끌어내는지를 ablation study를 통해 밝혀냈다. 논문에서는 pre-training을 통해 VisualBERT는 entity를 ground하고 단어와 이미지 영역 간의 특정 종속성 관계를 인코딩하는 방법을 학습하였다고 하였다. 이는 이미지의 상세한 의미 체계에 대한 모델의 이해를 향상시키는 데 기여한다$($그림 1. 참고$)$.

2. A Joint Representation Model for Vision and Language
이 섹션에서는 vision과 language에 대해 공동 상황화된 representation을 학습하기 위한 모델인 VisualBERT에 대해서 소개하도록 하겠다. BERT의 background에 대해서는 따로 알아보지 않고 어떻게 이미지와 텍스트를 함께 처리하는지에 대한 요약$($2-2$)$와 학습 프로시저$($2-3$)$에 대해서 설명하도록 하겠다.
2-1. Background
논문에서 제안한 VisualBERT는 이름에서부터 알 수 있듯이 BERT가 기반이 되는 모델이다. 따라서 BERT에 대한 이해가 필요한데 본 포스트에서는 따로 다루지 않고 BERT에 관한 포스트를 달아두도록 하겠다. VisualBERT를 이해하는데 꼭 필요한 부분이니 부족하다 싶으면 한 번 확인해보길 바란다.
Pre-trained Language Modeling paper reading(2) - BERT: Pre-training of Deep Bidirectional Transformers for Language Understandin
Pre-trained Language Modeling paper reading 요즘 NLP 분야에서 뜨거운 감자인 pre-trained Language Modeling에 관한 유명한 논문들을 읽고 리뷰를 하였다. 이 Pre-trained Language Modeling paper reading은 이 포스트만으로 끝
cartinoe5930.tistory.com
2-2. VisualBERT
VisualBERT의 핵심 아이디어는 입력 이미지에서 영역과 입력 텍스트의 요소를 정렬하기 위해 Transformer 내부에서 self-attention 메커니즘을 재사용하는 것이다. 그리고 BERT의 모든 구성 요소 외에도 이미지를 모델링하기 위해 일련의 시각적 임베딩 $F$를 도입하였다. 각각의 $f \in F$는 객체 탐지기로부터 얻어진 이미지에서의 바운딩 영역에 해당된다.
$F$의 각각의 임베딩은 3개의 임베딩의 합으로 계산된다.
- $f_{o}$: $f$의 바운딩 영역의 visual feature representation. CNN으로 계산됨.
- $f_{s}$: 텍스트 임베딩이 아니라 이미지 임베딩이라는 것을 나타냄.
- $f_{p}$: position embedding. 단어와 바운딩 영역 사이의 정렬이 입력의 일부로 제공되고 정렬된 단어에 해당하는 position embedding의 합으로 설정될 때 사용됨.
이렇게 얻어진 visual embedding은 text embedding의 기본 세트와 함께 multi-layer Transformer로 들어가고, 모델이 이 두 개의 입력 세트에서 유용한 정렬을 발견할 수 있게 해 주고, 새로운 공동 representation을 만들게 해 준다.
2-3. Training VisualBERT
논문에서는 VisualBERT를 학습시킬 때 BERT와 유사한 학습 프로시저를 사용하고 싶었으나 VisualBERT는 이미지 입력과 텍스트 입력을 둘 다 수용해야 하기 때문에 조금 다른 학습 프로시저를 가져야 했다. 그래서 이미지와 텍스트가 짝을 이루고 있는 데이터인 COCO$($이미지에 독립적인 5개의 캡션이 짝을 이루고 있음$)$ 데이터셋을 사용해야 했다. VisualBERT의 학습 프로시저는 다음의 3개의 페이즈로 이루어져 있다.
Task-Agnostic Pre-Training 논문에서는 VisualBERT를 COCO 데이터셋에서 두 개의 visually-grounded language modeling 목표를 사용해서 학습시켰다.
- 이미지에 MLM을 적용. 텍스트 입력의 일부분이 마스킹되고 이미지 바운딩에 해당하는 벡터는 마스킹되지 않은 상태에서 마스킹된 텍스트 입력을 예측
- Sentence-image 예측. COCO 데이터셋을 보면 하나의 이미지에 대해 여러 개의 캡션을 가지고 있는 것을 알 수 있다. 논문에서는 두 개의 캡션으로 구성된 text segment를 제공해 주었다. 하나의 캡션은 이미지를 설명하는 캡션이고, 다른 하나는 50%의 확률로 다른 해당 캡션이고, 50%의 확률로 무작위 캡션이 주어진다. 모델은 이 두 개의 캡션을 구분하기 위해 학습된다.
Task-Specific Pre-Training VisualBERT를 downstream task에 대해 fine-tuning하기 전에 이미지 목표에 MLM을 사용하여 task의 데이터를 사용해 모델을 학습시키는 것이 좋다는 것을 알아내었다. 이 스텝은 모델이 새로운 타깃 도메인에 적용되게 해 준다.
Fine-Tuning 이 스텝은 BERT의 fine-tuning 단계를 모방하였다. 여기서 task-specific한 입력, 출력, 목표들이 소개되고 Transformer는 task에 대한 성능을 극대화하기 위해 학습된다.
3. Experiments
논문에서는 VisualBERT를 사용하여 4개의 서로 다른 vision-language 응용에 적용해 보았다: VQA, VCR, NLVR, Flickr30K. VIsualBERT를 pre-train할 때 COCO 데이터셋을 사용하였고, Transformer encoder는 모두 BERT_BASE 모델을 사용하였다. 파라미터들 또한 pre-trained BERT_BASE model과 똑같이 초기화하였다.
image representation을 위해, 각각의 데이터셋에서 서로 다른 object detector을 사용하였다. 이들을 비교하기 위해 이들의 세팅을 따른 결과 서로 다른 image feature가 서로 다른 task에 사용되었다. 일관성을 위해 COCO에서 task-agnostic pre-training 도중에 end task와 똑같은 image feature을 사용하였다. 각각의 데이터셋에 대해 논문에서는 3개의 변형 모델을 사용하였다.
- VisualBERT: COCO 데이터셋에서 pre-training을 하고, task data에 대해서도 pre-training을 하고, task에 대해 fine-tuning한 BERT로부터 나온 파라미터 초기화를 사용한 전체 모델
- VIsualBERT w/o Early Fusion: 초기의 Transformer layer에서 image representation과 text가 섞이지 않고 마지막 Transformer layer에서 섞이게 된다. 이는 language와 visual 간의 상호작용이 얼마나 중요한지를 검사할 수 있다.
- VisualBERT w/o Pre-training: COCO 데이터셋에서 하는 task-agnostic pre-training을 건너뛴 VisualBERT이다.
이렇게 해서 VisualBERT의 Experiments를 진행하였다. 총 4개의 task에 대해서 실험을 진행하였으나 그 모든 걸 다루지는 않고 이전 모델보다 성능의 향상을 보인 NLVR과 Flickr30K task에 대해서만 알아보도록 하겠다.
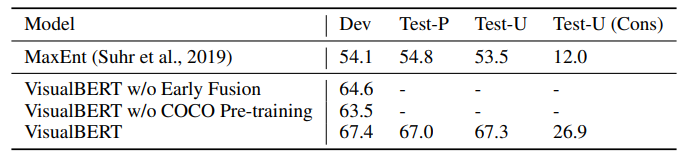
NLVR
NLVR은 자연어와 이미지에 대해 함께 추론하는 데이터셋이다. 이 task는 이미지 짝에 대해 자연어 캡션이 참인지를 결정하는 task이다. 논문에서는 VisualBERT의 embedding 메커니즘을 손봐서 서로 다른 segment embedding을 사용하여 서로 다른 이미지로부터 feature을 할당하도록 하였다. NLVR에 대한 결과는 다음의 표 3에 나타나있다. VIsualBERT w/o Early Fusion과 VisualBERT w/o COCO Pre-training은 이전의 best model인 MaxEnt를 능가하였고, VisualBERT는 큰 마진으로 능가하는 모습을 보여줬다.
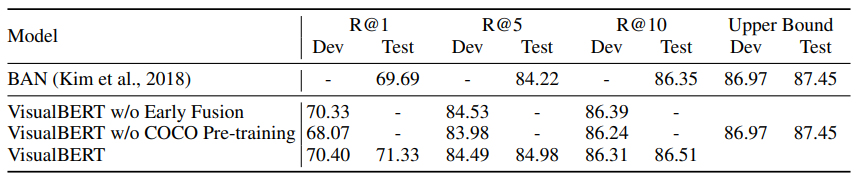
Flickr30K Entities
Flickr30K Entities 데이터셋 시스템이 이미지의 경계 영역에 대한 캡션의 문구를 접지하는 기능을 테스트한다. 이 task는 문장으로부터 span이 주어지면 해당하는 바운딩 영역을 선택하는 task이다. Visual Genome에서 사전 훈련된 Faster R-CNN의 이미지 기능이 사용되었고, task별 fine-tuning을 위해 추가적으로 self-attention 블록이 도입되고 각 head의 평균 attention 가중치를 사용하여 박스와 캡션 사이의 정렬을 예측한다.
VisualBERT는 현재의 SoTA 모델인 BAN을 능가하는 성능을 보여줬다. 이 세팅에서는 ablation model과 baseline과의 차이는 그리 크지 않았다. 따라서, 이 task에 대해서는 얕은 구조로도 충분한 성능을 얻을 수 있음을 알 수 있었다.
4. Analysis
이 섹션에서는 어떠한 방법이 VisualBERT가 강력한 성능을 낼 수 있도록 도와주는지 ablation study를 통해 알아보았다$($4-1$)$. 그다음에 VisualBERT가 어떻게 여러 개의 Transformer layer로 모호한 grounding을 해결할 수 있는지에 대한 qualitative analysis를 알아보았다$($4-2$)$.
4-1. Ablation Study
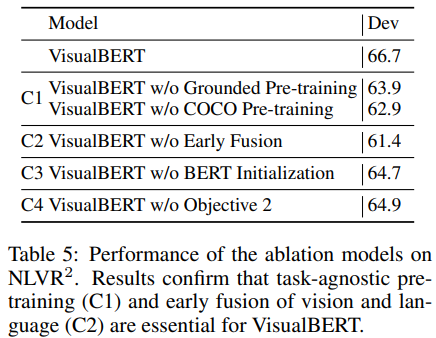
논문에서는 Experiment에서 알아봤던 2개의 ablation model을 포함한 총 4개의 VisualBERT 변형으로 NLVR에서 ablation study를 진행하였다. 이러한 분석의 목표는 VisualBERT의 4개의 변형이 성능에 어떤 영향을 미치는지를 조사하려는 것이다.
- C1: Task-agnostic Pre-training. task-agnostic pre-training을 통째로 건너뛰고$($VisualBERT w/o COCO Pre-training$)$, 이미지 없이 텍스트만으로 학습을 하였다$($VisualBERT w/o Grounded Pre-training$)$. 그 결과 두 변형 모두 안 좋은 결과를 보여줬고 vision과 language 짝 데이터로 학습하는 것이 중요함을 보여줬다.
- C2: Early Fusion. 이미지와 텍스트 feature의 이른 상호작용의 중요성을 입증하기 위해 Experiment에서 소개한 VisualBERT w/o Early Fusion을 사용하였다. 이는 이미지와 텍스트 간의 상호작용이 매우 중요함을 보여줬다.
- C3: BERT Initialization. BERT initialization의 효과를 파악하기 위해 랜덤 하게 초기화된 파라미터를 사용하였다. 하지만 딱히 큰 영향을 받지는 않았는데, 이는 이미 모델이 COCO pre-training 중에 grounded language에 대한 유용한 것들을 학습했기 때문이다.
- C4: Sentence-image prediction objective. task-agnostic pre-training 중에 sentence-image prediction 목표를 사용하지 않는 모델을 제안하였다. 그에 대한 결과는 이 목표가 긍정적이긴 하지만 다른 요소에 비해 상당한 효과는 적다고 보여줬다.
전반적으로 결과들을 보면 가장 중요한 디자인 선택은 task-agnostic pre-training$($C1$)$와 early fusion of vision and language$($C2$)$이다. pre-training에서는 추가 COCO 데이터를 포함하고 이미지와 캡션을 모두 사용하는 것이 가장 중요하다.
4-2. Qualitative Analysis
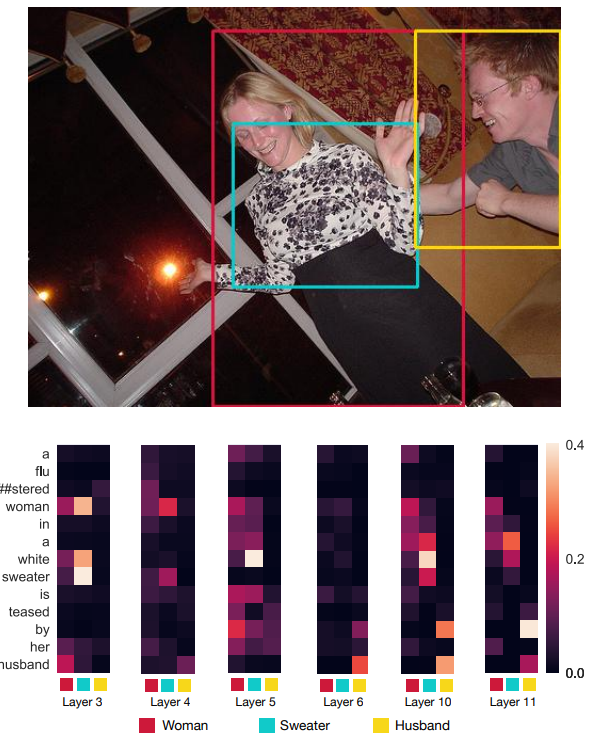
마지막으로, VisualBERT가 이미지와 텍스트를 처리할 때 레이어를 지남에 따라 attention이 어떻게 변화하는지에 대해 예시를 살펴보면서 알아보았다. 앞서 그림 1에서도 이 과정이 보여지고 있고, 다음의 그림 3$($원래 더 많은 예시를 포함하고 있으나 포스트에 담기에는 이미지의 크기가 커서 하나만 가져왔다$)$도 이 과정을 보여주고 있다.
전반적으로 논문에서는 VisualBERT가 연속적인 Transformer 레이어를 통해 정렬을 구체화하는 것으로 보았다. 예를 들어, 그림 3을 보면, 처음에는 'woman' 바운딩 영역에 해당하는 부분에 'husband'와 'woman' 모두 강한 attention 가중치를 가지고 있는 것을 알 수 있다. 하지만 깊은 레이어로 넘어갈수록 VisualBERT는 여성과 남성을 구분하고 이 둘을 알맞게 정렬하는 것을 알 수 있다. 또한 구문 정렬의 많은 예가 있는데, 예를 들어 같은 이미지에서 'teased'이라는 단어는 남성과 여성 모두에게 맞춰지고 'by'는 남자에게 맞춰진다. 마지막으로, 같은 이미지에서 her'라는 단어가 여성으로 해결됨에 따라 일부 상호 참조가 해결된 것 같다.
출처
https://arxiv.org/abs/1908.03557
VisualBERT: A Simple and Performant Baseline for Vision and Language
We propose VisualBERT, a simple and flexible framework for modeling a broad range of vision-and-language tasks. VisualBERT consists of a stack of Transformer layers that implicitly align elements of an input text and regions in an associated input image wi
arxiv.org