
요즘 들어서는 한 가지 기술로는 성공할 수 없는 시대라고 한다. 한 마디로 '융합'이 필요가 아닌 필수가 되어가고 있는 세상이다. 이번에 OpenAI에서 공개한 GPT-4도 이전의 GPT 모델들과 달리 이미지 데이터도 처리할 수 있는 multimodal 성을 보여줬다. 실로 엄청난 발전이라고 할 수 있는데, 이번 포스트에서는 multimodal model의 한 종류인 Vision-Language Model$($VLM$)$에 대해 알아보도록 하겠다! 이 포스트는 HuggingFace의 블로그를 참고하여 작성되었다.
HuggingFace Blog: https://huggingface.co/blog/vision_language_pretraining#supporting-vision-language-models-in-%F0%9F%A4%97-transformers
A Dive into Vision-Language Models
A Dive into Vision-Language Models Human learning is inherently multi-modal as jointly leveraging multiple senses helps us understand and analyze new information better. Unsurprisingly, recent advances in multi-modal learning take inspiration from the effe
huggingface.co
Table of Contents
1. Introduction
2. Learning Strategies
2-1. Contrastive Learnings
2-2. PrefixLM
2-3. Multi-modal Fusing with Cross Attention
2-4. MLM / ITM
2-5. No Training
Introduction
모델을 'vision-language' model이라고 부르는 데에는 무슨 의미가 있을까? 이 모델은 시각적 및 언어적 특성을 합친 것일까? 아리송한데 그렇다면 이 모델의 정확한 정의는 어떻게 될까?
이 모델을 정의하는데 도움되는 한 가지 특성은 이 모델이 이미지$($vision$)$와 자연어 텍스트$($language$)$를 함께 처리한다는 것이다. 이 프로세스는 모델이 수행하도록 요청받은 입력, 출력, task에 따라서 달라진다.
예를 들어 zero-shot 이미지 분류 task가 있다고 가정해보자. 이미지와 몇 개의 prompt를 같이 모델에 보내면, 모델은 입력 이미지에 가장 그럴듯한 prompt를 출력하게 된다.
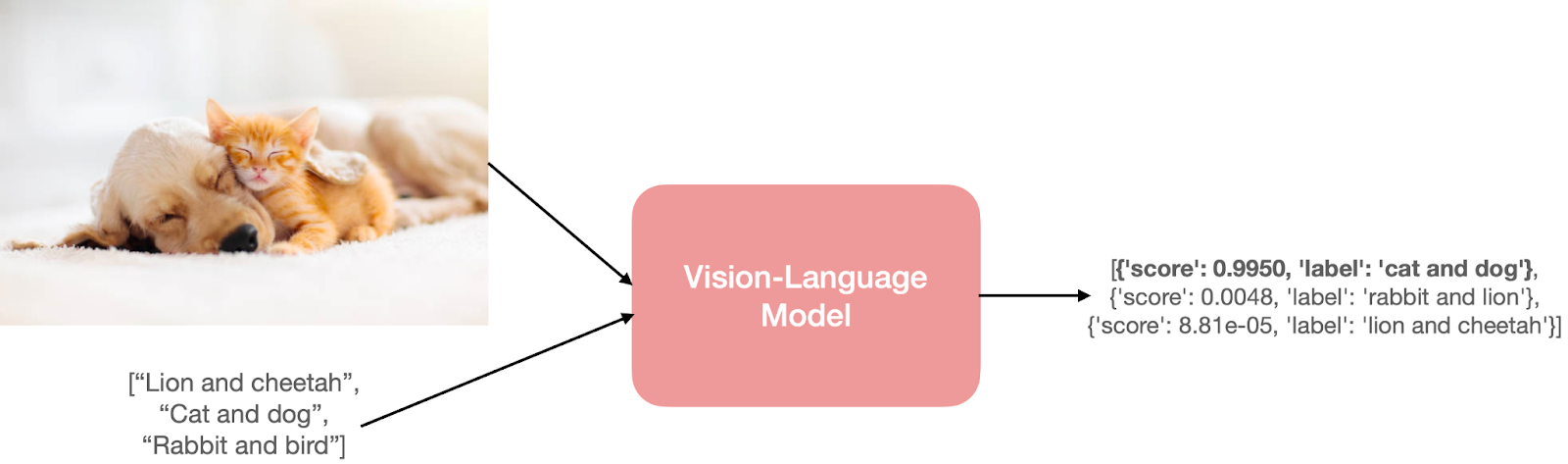
이렇게 예측을 하기 위해서, 모델은 입력 이미지와 텍스트 prompt를 모두 이해하고 있을 필요가 있다. 모델은 시각적 및 언어적 이해를 얻기 위해 encoder을 분리하거나 융합하는 등의 과정을 거친다. 하지만 이러한 입력과 출력들은 여러가지 형태를 가지고 있을 수 있다. 아래는 그에 대한 몇 가지 예시이다.
- 자연어로부터 이미지 retrieval
- Phrase grounding: 입력 이미지와 자연어 구문으로부터 object detection을 수행 $($예: 어린 아이가 방망이를 휘두르다.$)$
- VIsual QA: 자연어에서 입력 이미지와 질문으로부터 정답 찾기
- 주어진 이미지에 대해 자막 생성: 이 task 또한 텍스트 생성으로 받아들여지기도 하지만, 여기서는 자연어 prompt와 이미지로 시작된다.
- 이미지와 텍스트 특성을 모두 가지는 소셜 미디어 콘텐츠에서 혐오 발언 감지
Learning Strategies
vision-language model은 보통 3개의 중요한 요소로 이루어져 있다: image encoder, text encoder, 두 개의 encoder로부터 정보를 어떻게 융합할 지의 전략. 이러한 핵심 요소는 손실 함수가 모델 아키텍처와 학습 전략을 중심으로 설계되기 때문에 서로 밀접하게 결합되어 있다. vision-language model는 거의 새로운 연구 분야이지만, 이러한 모델들의 구조는 몇 년 사이에 엄청나게 많이 변화하였다. 이전의 연구들은 손수 제작한 이미지 설명과 pre-trained 워드 벡터 또는 빈도 기반의 TF-IDF를 사용하였지만, 최근의 연구들은 이미지와 텍스트 특징을 분리해서 또는 결합해서 학습하기 위해 이미지와 텍스트에 대해 transformer architecture를 적용하였다. 이러한 모델들은 다양한 downstream task를 가능하게 하는 전략적 pre-training 목표를 사용하여 pre-train 되었다.
이번 섹션에서는 vision-language model을 위한 전형적인 pre-training 목표와 전략들에 대해서 알아볼 것이다. 이것들을 알아보기 전에 pre-training 목표들에 대해 간략하게 살펴보았다.
- Contrastive Learning: 대조적 방식으로 이미지와 텍스트를 공동 feature space에 정렬
- PrefixLM: 이미지를 LM에 접두사로 사용함으로써 이미지와 텍스트 임베딩을 공동으로 학습
- Multi-modal Fusing with Cross Attention: cross-attention 메커니즘을 사용해서 LM의 레이어에 시각적 정보를 융합
- MLM / ITM: masked-language modeling 및 image-text matching 목표를 사용하여 이미지의 일부를 텍스트와 정렬
- No Training: 반복적인 최적화를 통해 독립적인 vision & lanugage model을 사용
1. Constrastive Learning

Contrastive learning은 vision model에 일반적으로 사용되는 pre-training 목표이며 vision-language model에도 매우 효과적인 pre-training 목표인 것으로 입증되었다. 최근의 연구들은 contrastive loss를 사용하여 {image, caption}로 구성되어 있는 거대한 데이터셋을 사용해서 텍스트 인코더와 이미지 인코더를 공동으로 학습함으로써 시각적 및 언어적 특성을 연결지었다. contrastive learning은 입력 이미지와 텍스트를 동일한 feature space에 매핑하여 이미지-텍스트 쌍의 임베딩 사이의 거리가 일치하는 경우 최소화하거나 일치하지 않는 경우 최대화하는 것을 목표로 한다.
CLIP에 대해서 거리는 텍스트와 이미지 임베딩의 코사인 거리이다. ALIGN과 DeCLIP 같은 모델은 잡음이 있는 데이터셋을 설명하기 위해 이 모델들만의 거리 메트릭을 디자인하였다.
LiT 같은 경우에는 image encoder는 동결시키고 CLIP의 pre-training 목표를 사용해서 text encoder을 fine-tuning 하는 간단한 방법을 소개하였다. 저자들은 이 아이디어를 image encoder에서 이미지 임베딩을 더 잘 읽도록 text encoder를 가르치는 방법으로 해석하였다. 이 방식은 CLIP보다 더욱 효과적이고 효율적이라는 것을 보여줬다. FLAVA 같은 다른 연구들은 vision과 language embedding을 더욱 잘 정렬하기 위해 contrastive learning과 다른 pre-training 전략의 조합을 사용하였다.
2. PrefixLM

vision-language model을 학습시키는 또 다른 방법은 PrefixLM을 사용하는 것이다. SimVLM과 VirTex 같은 모델은 이 pre-train 목표를 사용하며 auto-regressive language model과 유사한 transformer encoder 및 transformer decoder로 구성된 통합 multimodal 아키텍처를 특징으로 한다.
이를 더욱 자세하게 알아보도록 하자. prefix 목표를 사용하는 LM은 prefix처럼 입력 텍스트가 주어지면 다음 토큰을 예측한다. 예를 들어 "남자가 코너에 서있다." 라는 sequence가 주어지면, "남자가 코너에" 라는 prefix로 사용할 수 있고 다음 토큰인 "서있다" 또는 다른 그럴듯한 토큰을 예측함으로써 학습할 수 있다.
Visual Transformer$($ViT$)$는 이 prefix의 개념을 이미지를 각각의 이미지 패치로 나누어서 이 패치들을 순차적으로 모델에 입력으로 줌으로써 이미지에 똑같이 적용하였다. 이 아이디어를 활용하여 SimVLM은 인코더가 연결된 이미지 패치 시퀀스와 prefix 텍스트 시퀀스를 prefix 입력으로 받아들이고 디코더가 텍스트 시퀀스의 연속을 예측하는 아키텍처를 특징으로 합니다. 위의 그림은 이 아이디어를 묘사하고 있다. SimVLM 모델은 처음에 prefix에 나타나있지 않은 이미지 패치들을 사용하지 않고 텍스트 데이터셋에서 pre-train 된 다음에 정렬된 image-text 데이터셋에서 학습된다.
image-guided task를 위해 시각적 정보를 LM로 융합하기 위해 통합 multi-modal architecture를 활용한 모델은 인상적인 성능을 보여줬다. 하지만, 오직 prefixLM 전략만을 사용한 모델은 image captioning 또는 Visual QA 같은 downstream task에 국한되는 응용을 보여줬다. 예를 들어 사람 그룹에 대한 이미지가 주어지면 우리는 이미지의 설명을 작성하기 위해 이미지에 대해 질문하거나 시각적 추리를 필요로 하는 질문을 던질 수 있다. 반면에 multi-modal representation을 학습하거나 하이브리드 접근 방식을 채택하는 모델은 object detection 및 image segmentation과 같은 다양한 기타 downstream task에 맞게 조정할 수 있다.
Frozen PrefixLM
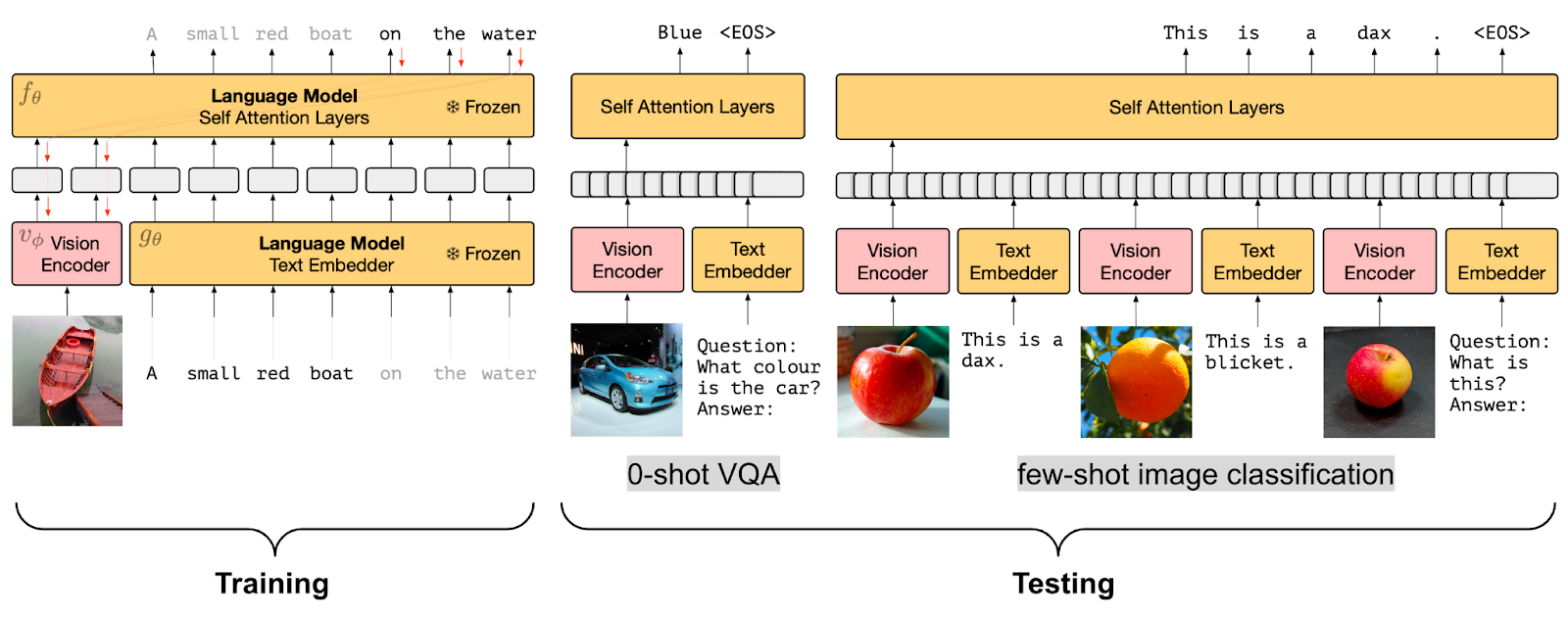
시각적 정보를 LM에 융합하는 것은 매우 효과적인 반면, pre-trained LM을 fine-tuning 필요 없이 사용하는 것은 더욱 효율적이다. 그래서 vision-language model에서 다른 pre-training 목표들은 frozen language model을 사용해서 정렬된 image embedding을 학습한다.
Frozen, MAPL, ClipCap 같은 모델들은 이 Frozen prefixLM을 pre-training 목표로 사용한다. 위에서 설명한 PrefixLM 목표와 유사한 방식으로 ptr-train된 Frozen LM의 접두사로 사용할 수 있는 이미지 임베딩을 생성하기 위해 학습 중에 이미지 인코더의 매개변수만 업데이트한다. Frozen과 ClipCap은 둘 다 이미지 임베딩과 prefix text가 주어지면, 캡션에서 다음 토큰을 생성하는 목표를 사용해서 정렬된 image-text 데이터셋에서 학습된다.
마지막으로, Flamingo는 pre-trained vision encoder와 language model을 frozen 상태로 보존하고 광범위한 vision & language task에서 few-shot learning으로 새로운 SoTA를 달성하였다. Flamingo는 pre-trained frozen vision model 위에 Perceiver Resampler 모듈을 추가하고 기존의 pre-trained LM 레이어와 Frozen LM 레이어 사이에 새로운 cross-attention 레이어를 삽입하여 시각적 데이터에 대한 LM을 조정함으로써 이를 달성하였다.
Frozen PreficLM pre-training 목표의 실용적인 장점은 제한된 정렬 image-text 데이터에서 학습을 가능하게 한다는 것이다. 이는 정렬된 multi-model 데이터셋을 구하기 어려운 분야에 적용할 때 어려움을 덜어준다.
3. Multi-modal Fusing with Cross Attention
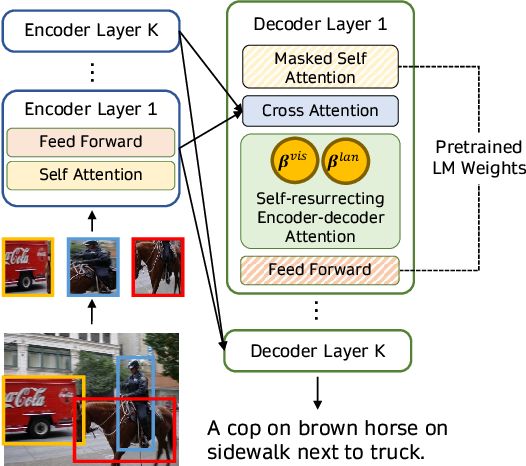
pre-trained LM을 multi-modal task에 활용하기 위한 또다른 방법은 이미지를 LM에 추가적 prefix로 사용하는 대신에 cross-attention 메커니즘을 사용하여 LM의 decoder의 레이어에 시각적 정보를 바로 융합하는 것이다. VisualGPT, VC-GPT, Flamingo 같은 모델들은 이 pre-training 전략을 사용하고 image captioning과 visual QA task에서 학습된다. 이러한 모델들의 주된 목표는 텍스트 생성 능력과 시각적 정보의 조합을 효율적으로 밸런스를 맞추는 것이다. 이는 거대한 multi-modal 데이터셋이 없을 때 더욱 중요하다.
VisualGPT 같은 모델들은 이미지를 임베딩하고 그럴듯한 캡션을 생성하기 위해 이 visual embedding을 pre-trained language decoder 모듈의 cross-attention layer에 주기 위해 visual encoder을 사용하였다. FIBER 같은 최근의 연구들에서는 더욱 효율적인 multi-modal 융합과 다양한 downstream task를 가능케 하기 위해 gate 메커니즘을 사용한 cross-attention 레이어를 vision과 language backbone에 삽입하였다.
4. Masked-Language Modling / Image-Text Matching
또다른 vision-language model은 이미지의 세부적인 부분을 텍스트를 사용해서 정렬하고 다양한 downstream task를 가능케 하기 위해서 MLM과 ITM의 조합을 사용하였다. 이러한 셋업을 사용하는 모델들에는 VisualBERT, FLAVA, ViLBERT, LXMERT, BridgeTower 등이 있다.

MLM과 ITM이 어떤 의미를 가는지 자세히 알아보도록 하자. 부분적으로 마스킹된 캡션이 주어지면, MLM은 해당되는 이미지에 기반해서 masked word를 예측한다. MLM은 바운딩 박스를 사용한 풍부한 양의 주석이 달린 multi-modal 데이터셋과 입력 텍스트의 부분에 대한 객체 지역 제안을 생성하기 위한 object detection 모델을 사용해야 한다.
ITM은 이미지와 캡션 짝이 주어지면 캡션이 이미지와 알맞는지 아닌지를 예측하는 task이다. negative sample들이 보통 데이터셋으로부터 랜덤하게 샘플링된다. MLM과 ITM은 multi-modal 모델의 pre-training 도중에 종종 합쳐진다. 예를 들어, VisualBERT는 객체를 검출하기 위해 pre-trained object detection 모델을 사용하는 BERT와 유사한 구조를 제안한다. 이 모델은 pre-training 동안 MLM 및 ITM의 조합을 사용하여 입력 텍스트의 요소와 관련 입력 이미지의 영역을 self-attention과 암시적으로 정렬한다.
FLAVA와 같은 다른 연구들은 이미지와 텍스트 representation을 융합하고 정렬해서 multi-modal 추리를 하기 위해 image encoder, text encoder, multi-modal encoder로 구성되었다. 이 모든 것들은 Transformer에 기반을 두고 있다. 이를 달성하기 위해, FLAVA는 MLM, ITM, Masked-Image Modeling$($MIM$)$, contrastive learning 같은 다양한 종류의 pre-training 목표를 사용하였다.
5. No Training
마지막으로 다양한 최적화 전력들은 pre-trained image & text 모델을 사용해서 이미지와 텍스트 representation을 연결 짓는 것에 목표를 두거나 추가적인 학습 없이 새로운 downstream task에 대해 pre-trained multi-modal 모델을 적용시키려 하고 있다.
예를 들어 MaGiC은 입력 이미지에 대한 캡션을 생성하기 위해 pre-trained autoregressive LM을 통하여 반복적 최적화를 하는 것을 제안하였다. 이를 하기 위해 MaGiC은 생성된 토큰과 입력 이미지의 CLIP embedding을 사용해서 CLIP 기반의 'Magic score'를 계산하였다.
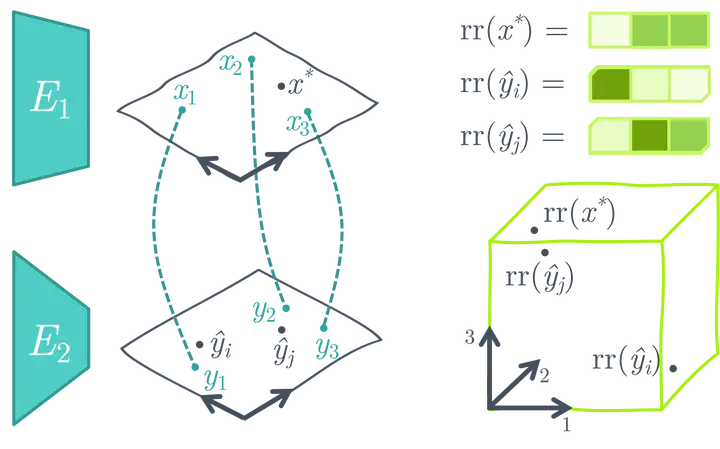
ASIF는 추가적인 학습 없이 pre-trained uni-modal 이미지와 텍스트 모델을 더 적은 양의 multi-modal 데이터셋을 사용해서 이미지 캡셔닝을 하기 위한 multi-modal로 변환하는 간단한 방법을 제안하였다. ASIF가 갖고 있는 중요한 점은 비슷한 이미지의 캡션은 각각의 다른 것들과 비슷하다는 것이다. 그래서 우리는 ground-truth multi-modal 짝의 작은 데이터셋을 사용해서 상대적 representation 공간을 만듦으로써 유사도 기반의 검색을 수행할 수 있다.
p.s.
한 번 정리해보기는 하였으나 아직 이해가 부족한 것 같아서 추후에 이 multi-modal model에 관련된 내용들을 더 작성해보려고 한다. 부족한 내용이지만 끝까지 봐주셔서 감사합니다 😊😊
출처
A Dive into Vision-Language Models
A Dive into Vision-Language Models Human learning is inherently multi-modal as jointly leveraging multiple senses helps us understand and analyze new information better. Unsurprisingly, recent advances in multi-modal learning take inspiration from the effe
huggingface.co