
The overview of this paper
이 논문에서는 통합된 Vision-Language Pre-training(VLP) model을 제안하였다. 모델은 다음의 두 가지를 통합하였다. 이로 인해 VLP는 encoder와 decoder를 서로 다른 각기의 모델로 구현한 method들과 다른 점을 가지게 되었다.
- visual-language 이해 또는 생성을 위해 fine-tune
- encoding & decoding을 위해 공유된 multi-layer transformer를 사용
통합 VLP model은 2개의 task에 대한 unsupervised learning 목표를 사용해서 거대한 양의 image-text 짝에서 pre-train 되었다: bi-directional & sequence-to-sequence(seq2seq) masked vision-language 예측. 두 task는 예측 조건이 어떤 컨텍스트에 있는지에 따라 다르다. 이는 공유 Transformer 네트워크에 대한 특정 self-attention mask를 활용하여 제어된다. VLP는 처음으로 서로 다른 vision-language 생성 및 이해 task인, image captioning과 visual question answering에서 SoTA를 달성하였다.
Table of Contents
1. Introduction
2. Vision-Language Pre-training
2-1. Vision-Language Transformer Network
2-2. Pre-training Objectives
3. Fine-tuning for Downstream Tasks
3-1. Image Captioning
3-2. Visual Question Answering
4. Experiments & Results
1. Introduction
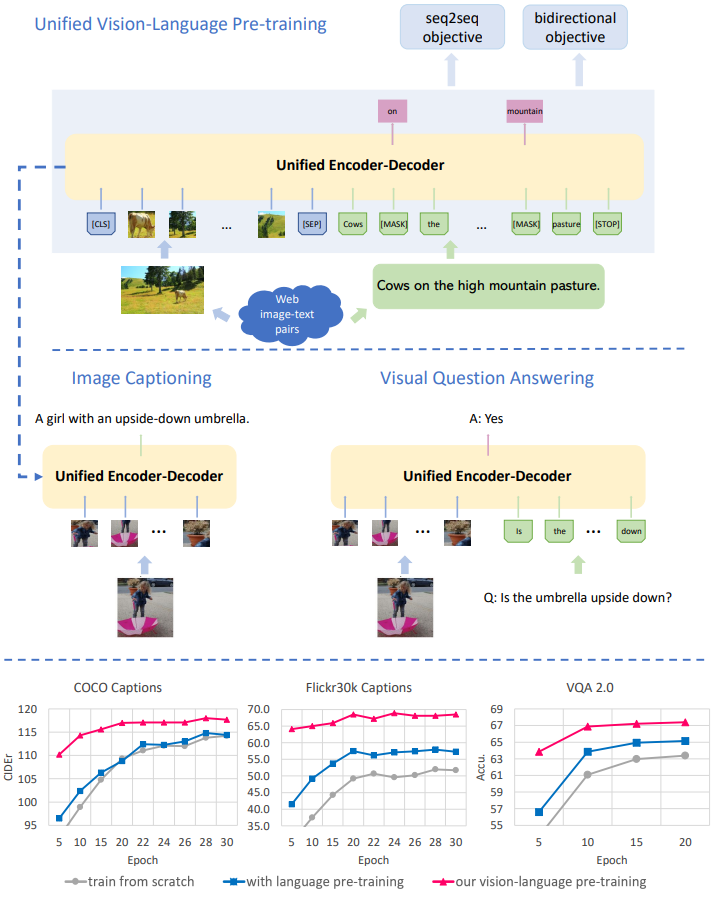
다음의 표 1은 최근의 연구들에서 BERT로부터 만들어진 vision-language pre-training 모델들에 대해 요약해서 보여주고 있다. 이 모델들은 2단계의 학습 스키마를 가지고 있는데, 이는 다음과 같다.
- 첫 번째 단계: pre-training. 거대한 양의 image-text 짝에서 intra-modality 또는 cross-modality 관계에 기반해서 masked word 혹은 image region을 예측함으로써 vision-language representation을 학습함.
- pre-trained model은 downstream task에 적응하기 위해 fine-tune 된다.
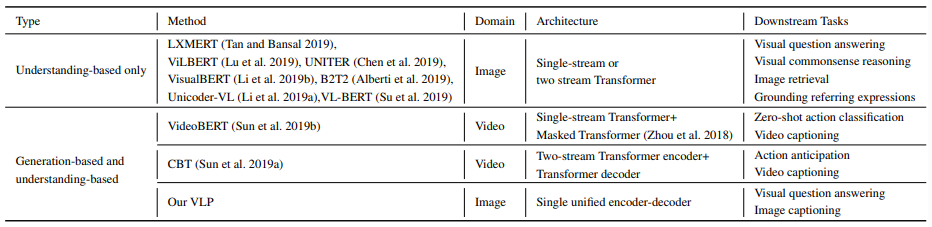
서로 다른 pre-trained model을 사용하여 각각의 downstream task에 대해서 상당한 성능 향상을 보여줬지만, 범용적으로 응용 가능한 하나의 통합된 모델을 pre-train 하는 것은 어려운 과제로 남아있다. 지금까지의 대부분의 pre-trained model들은 understanding task에서만 발전되었고, 이들은 표 1에 'understanding-based only'로 표시되어 있다. 또는 생성 task를 위해 따로따로 학습되어야 하는 다양한 modality-specific encoder와 decoder로 이루어져 있는 하이브리드 모델이다. 예를 들어, 표 1의 VideoBERT와 CBT는 pre-training을 encoder에서만 하고 decoder에서는 하지 않는다. 이는 encoder에 의해 학습되는 cross-modal representation과 생성을 위한 decoder에 의해 필요한 representation 사이에 불일치가 발생할 수 있는데, 이는 모델의 일반성을 해칠 수 있다. 이 논문에서는 이 불일치를 제거하고 encoding과 decoding 둘 모두에 관한 통합된 representation을 pre-training 하는 방법에 대해 찾아내었다. 이러한 통합된 representation은 더욱 효과적인 cross-task 지식 공유와 서로 다른 task에 대해 서로 다른 pre-training을 할 필요가 없기 때문에 개발 비용을 줄여준다.
이것을 위하여 vision-language 생성 및 이해 task 둘 모두에 대해 fine-tune될 수 있는 통합 encoder-decoder model인 Vision-Language Pre-training(VLP)를 제안하였다. VLP model은 encoding과 decoding을 위해 공유 multi-layer Transformer 네트워크를 사용하고, 거대한 양의 image-caption 짝에서 pre-train 되고, 2개의 unsupervised vision-language task에 대해 최적화된다: bi-directional & seq2seq masked language prediction. 두 task는 예측 조건이 어떤 컨텍스트에 있는지에 따라 다르다. 이는 공유 Transformer 네트워크에 대한 특정 self-attention mask를 활용하여 제어된다.
제안된 VLP model은 표 1의 다른 BERT 기반 모델들에 비해 2가지의 이점을 가진다.
- encoder & decoder를 통합해서 범용적 vision-language representation을 더욱 학습. 이로 인해 vision-language 생성과 이해 task에서 더욱 쉽게 fine-tune 됌.
- 통합된 pre-training 프로시저는 두 개의 vision-language 예측 task(bi-directional + seq2seq)를 위한 하나의 model architecture를 이끎. 이는 task-specific metric 엄청난 성능 손실 없이 여러 개의 pre-training model, 그리고 서로 다른 유형의 task를 위한 pre-training model을 완화할 필요가 있었다.
2. VIsion-Language Pre-training
논문에서는 입력 이미지를 $I$로 두고 관련된 타깃 문장 설명(words)을 $S$로 표현하였다. 그리고 object detector를 사용해서 이미지로부터 고정된 수 $N$의 object 영역을 추출하였는데, 이를 $\left\{ r_1, ..., r_{N} \right\}$으로 나타내고 해당하는 region feature를 $R = [R_1, ..., R_{N}] \in \mathbb{R}^{d \times N}$로, region object의 라벨을 $C = [C_1, ..., C_N] \in \mathbb{R}^{l \times N}$로, region의 geometric 정보를 $G = [G_1, ..., G_N] \in \mathbb{R}^{o \times N}$으로 나타내었다. 여기서 $d$는 임베딩 크기를 나타내고, $l$은 object detector의 object class의 수를 나타낸다. 여기서 $o = 5$는 region boundary 상자의 왼쪽 상단 및 오른쪽 하단 모서리 좌표에 대한 4개의 값과 상대 영역에 대한 1개의 값으로 구성된다. $S$의 단어들은 one-hot vector로 표현되고 임베딩 사이즈 $e$를 사용하여 word embedding으로 인코딩 된다: $y_t \in \mathbb{R}^{e}$ 여기서 $t \in \left\{ 1, 2, ..., T \right\}$와 $T$는 문장의 길이를 나타낸다.
2-1. Vision-Language Transformer Network
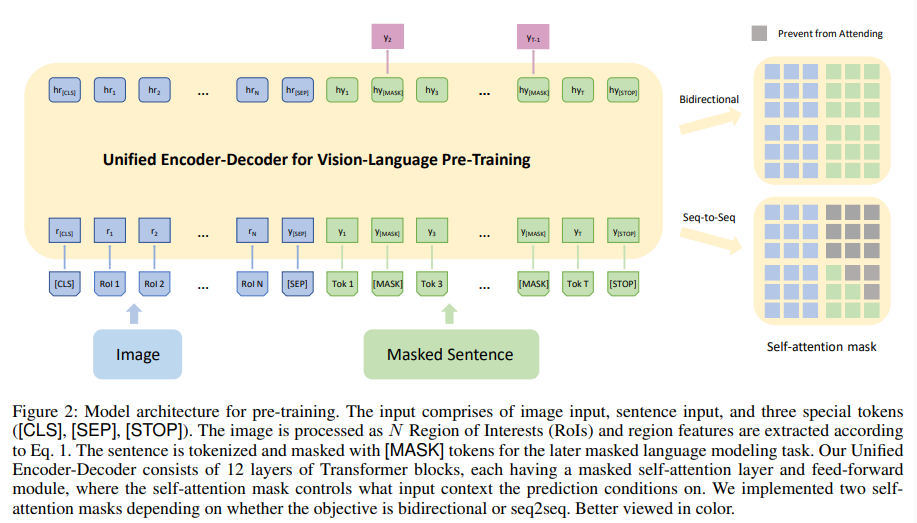
논문의 vision-language Transformer 네트워크는 Transformer encoder와 decoder를 하나의 모델로 통합하였는데, 이것이 그림 2의 왼쪽에 나타나 있다. 모델의 입력은 class-aware region embedding, word embedding, 3개의 스페셜 토큰으로 구성되어 있다. 여기서 region embedding은 다음과 같이 정의된다.
$r_i = W_{r}R_{i} + W_{p}[LayerNorm(W_{c}C_{i})|LayerNorm(W_{g}G_{i})]$
여기서 $[\cdot|\cdot]$은 feature 차원 간의 연결을 나타내고, LayerNorm은 LayerNormalization을 의미한다. 두 번째 항은 BERT의 positional embedding을 흉내 내지만, 추가적인 region class 정보를 추가하고, $W_r, W_p, W_c, W_g$는 임베딩 가중치를 의미한다. 여기서 class-aware region 임베딩을 나타내기 위해 $r_i \in \mathbb{R}^{d} (i \in \left\{ 1, 2, ..., N\right\})$ 표기법을 오버로드한다. 게다가 BERT처럼 segment embedding을 $r_i$에 추가하였다.
word embedding은 BERT와 유사하게 정의되어 $y_t$에 positional embedding과 segment embedding을 추가하고, 이 값은 다시 $y_t$에 오버로드된다. 그리고 3개의 스페셜 토큰 [CLS], [SEP], [STOP]을 정의하였다. [CLS]는 visual 입력의 시작을 나타내고, [SEP]는 visual 입력과 문장 입력 간의 경계를 나타내고, [STOP]는 문장의 끝을 나타낸다. [MASK] 토큰은 masked word를 나타낸다.
2-2. Pre-training Objectives
BERT MLM 목표는 입력 문장에서 랜덤 하게 토큰들은 마스킹해서 학습을 통해 그 마스킹된 토큰의 원래 단어를 예측하도록 학습시키는 방법이다. 이를 위해 모델은 문맥을 파악하는 LM을 생성할 수 있어야 한다. 논문에서는 똑같은 스키마를 따라서 두 개의 구체적인 목표를 고려하였다: bi-directional & seq2seq
그림 2의 오른쪽에서 보이는 것처럼 두 목표의 가장 큰 차이점은 self-attention mask에 있다. bi-directional objective를 위해 사용되는 mask는 양방향성으로 visual & language modality 간에 메시지 흐름이 가능케 한다. 반면에 seq2seq는 미래의 단어는 참조 불가해서 auto-regressive를 만족한다. 이를 공식적으로 표현하면 첫 번째 Transformer block의 입력은 $H^{0} = [r_{[CLS]}, r_1, ..., r_N, y_{[SEP]}, y_1, ..., y_T, y_{[STOP]}] \in \mathbb{R}^{d \times U}$로 정의된다. 여기서 $U = N+T+3$이고, 서로 다른 Transformer의 레벨에서 encoding은 $H^{l} = Transformer(H^{l-1}), l \in [1, L]$로 정의된다. 논문에서는 추가적으로 self-attention mask를 $M \in \mathbb{R}^{U \times U}$로 정의하였고, 여기서
$M_{jk} = \left\{\begin{matrix}
0, allow to attend \\ -\infty, prevent from attending
\end{matrix}\right.$
간단함을 위해 논문에서는 self-attention 모듈에서 하나의 attention head를 가정하였다. 그다음에 $H^{l-1}$에서 self-attention 출력은 다음과 같이 정의된다:
$A^{l} = softmax(\frac {Q^{\top}K}{\sqrt{d}} + M)V^{\top}, $
$V = W_{V}^{l}H^{l-1}, Q = W_{Q}^{l}H^{l-1}, K = W_{K}^{l}H^{l-1}$
여기서 $W_{V}^{l}, W_{Q}^{l}, W_{K}^{l}$은 임베딩 가중치이다. 중간 변수 $V, Q, K$는 self-attention처럼 각각 value, query, key를 나타낸다. $A^{l}$은 출력 $H^{l}$을 형성하기 위해 residual connection을 사용한 feed-forward layer을 사용함으로써 추가적으로 encoding 되었다. pre-training 중에 논문에서는 두 objective 간에 per-batch를 번갈아 나오게 하고 seq2seq와 bi-directional의 비율을 하이퍼 파라미터 $\lambda$와 $1 - \lambda$를 사용해서 정의하였다.
논문에서는 실험을 통해 region class 확률($C_i$)을 region feature($r_i$)에 통합하는 것이 성능 향상을 이끈다는 것을 보여줬다. 그래서 visual representation을 개선하기 위해 masked region 예측 task가 사용되는 기존의 작업과 다르게, masked language 재건축을 활용함으로써 간접적으로 visual representation을 개선시켰다. 논문에서는 또한 작업이 seq2seq 또는 bi-directional보다 약할 뿐만 아니라 계산 비용이 많이 들기 때문에 BERT에서 또는 이미지와 텍스트 사이의 일치를 예측하는 맥락에서 Next Sentence Prediction task를 사용하지 않기로 선택하였다.
Sequence-to-Sequence inference. seq2seq 학습이 수행되는 것과 유사한 방식으로 논문에서는 직접적으로 VLP에 seq2seq 추론을 적용할 수 있었다.
3. Fine-tuning for Downstream Tasks
3-1. Image Captioning
논문에서는 seq2seq objective를 사용하여 pre-trained VLP 모델을 타깃 데이터셋에서 fine-tune 하였다. 추론 중에 논문에서는 우선 image region을 스페셜 토큰 [CLS]와 [SEP]로 encoding 하고 [MASK] 토큰을 주고 word 확률 출력을 샘플링함으로써 생성을 시작하였다. 그다음에 이전 입력 문장의 [MASK] 토큰은 다음 예측을 시작하기 위해 입력 시퀀스에 추가된다. [STOP] 토큰이 선택되면 생성을 멈춰지게 된다.
3-2. Visual Question Answering
논문에서는 VQA를 multi-label 분류 문제로 정의하였다. 이 작업에서는 맨 위의 $k$ 개의 가장 흔한 대답을 대답 vocabulary로 선택하고 클래스 라벨로 사용하는 open domain VQA에 집중하였다. 이전의 연구를 따라서 $k$를 3129로 설정하였다.
fine-tuning 중에 [CLS]와 [SEP]의 마지막 숨겨진 상태의 요서별 곱 위에 다층 퍼셉트론(Linear + ReLU + Linear + Sigmoid)이 학습된다. 논문에서는 모델 출력 점수를 cross-entropy loss를 사용해서 soft answer label에 관하여 최적화하였다. 이전에는 pre-training 중에 타깃 데이터셋을 사용해서 task-specific objective를 사용하였으나, VLP의 pre-training은 그럴 필요가 없기 때문에 더욱 general 해진다.
4. Experiments & Results
Data preparation & Implementation details. 이 부분에 관해서는 본 포스트에서 따로 다루지 않을 테니 이 부분에 대해 궁금하다면 논문을 참고하길 바란다.
Model variants & metrics. VLP의 pre-training의 효과를 설명하기 위해, 논문에서는 처음에 pre-training을 사용하지 않는 baseline을 포함하였다. 그다음에 모델에 극한의 세팅인 $\lambda = 1$ (seq2seq pre-training only)와 $\lambda = 0$ (bi-directional only)를 포함하여 어떻게 각각의 objective가 서로 다른 downstream task에 대해 작동하는지 알아보았다. full model은 이 두 objective 간에 공동으로 학습된다. fine-tuning은 pre-training의 구성에 연연하지 않고 똑같이 수행되었다. 논문에서는 image captioning을 위한 일반적인 language metrics를 사용하였다. 여기에는 VQA의 정확도를 측정하는 Bleu@4, METEOR, CIDEr, SPICE가 포함되어 있다.
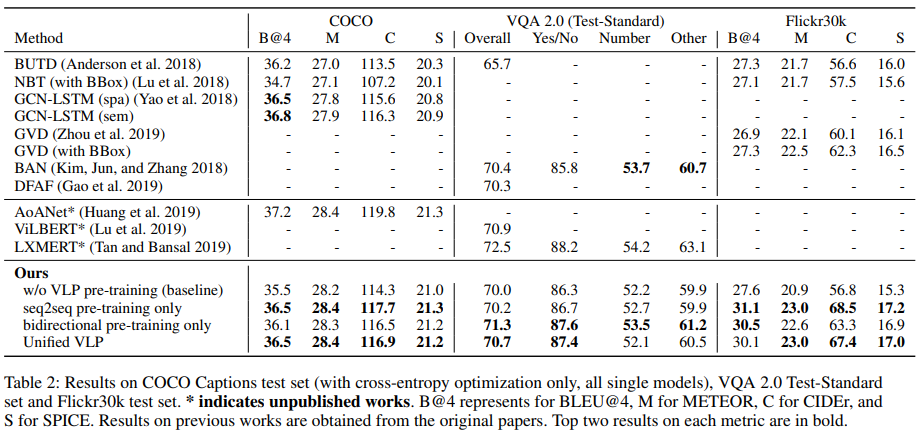
Comparisons agains SoTAs. test set에서 VLP와 SoTA method를 비교한 결과가 표 2에 나타나 있다. 논문에서는 published SoTA의 작업(표 2의 위쪽 부분), unpublished work의 작업(표 2의 중간 부분), VLP(표 2의 아래쪽 부분)을 포함하였다. 모든 image captioning method는 공정한 비교를 위해서만 cross-entropy 최적화를 사용하는 단일 모델이다. 논문의 full model(Unified VLP)은 COCO의 4개 지표 중 3개, VQA 2.0의 전체 정확도 및 Flickr30k의 4개 지표 모두에서 SoTA를 능가한다. 성능 향상은 CIDEr 지표에서 5.1%, BLEU@4에서 2.8%의 이득을 얻었고, Flickr30k에서 특히 좋았다.
Boost from pre-training. 논문의 full model은 baseline model이 대부분의 metric에 대해서 상당한 마진을 남길 수 있게 해 줬고, 그래서 VLP의 pre-training 방법에 감사를 표한다. Flickr30k의 CIDEr 메트릭에서 10% 이상의 성능 향상, COCO 및 B@4의 CIDEr에서 2% 이상의 성능 향상, Flickr30k의 METEOR에서 몇 가지 눈에 띄는 개선 사항이 있었다. 작은 데이터셋은 대부분의 vision-language pre-training이 overfitting 문제를 완화시키는데 이점을 주었다. 두 개의 극한의 세팅의 모델들은 각자가 '선호'하는 task에 대해서 더욱 잘 작동하는 모습을 보여줬다. 예를 들어 seq2seq pre-training alone은 downstream captioning task에서 상당한 성능 향상을 보여줬고, bi-directional pre-training alone은 understanding task에서 서 이점을 보여줬다. 하지만 반대에 대해서는 그렇지 않았다. 이들 각각은 VQA 2.0에서 정확도 면에서 새로운 SoTA를 달성하였다. 공동 학습은 다소 다른 두 가지 목표에서 학습한 representation을 유기적으로 결합하고 모든 downstream task에서 약간 손상되었지만 적절한 정확도를 제공한다. 이는 engineering 관점에서, 생성 task 또는 이해 task에 대해서 별개의 pre-training model를 가진다면, 최적의 모델 성능을 얻을 수 있다는 것을 말한다. model architecture와 파라미터 공유를 중요하게 생각한다면 공동 학습은 좋은 절충안이다.
Impact of pre-training types. base model Transformer가 어떻게 초기화되느냐에 따라서 논문에서는 4개의 pre-training 정도를 약한 것에서부터 강한 것까지 정의하였다. 이에 대해서 downstream task에 대해 fine-tuning 한 결과는 다음의 그림 1과 표 3에 나타나 있다. 그림 1에서 보이는 것처럼 vision-language pre-training은 downstream task의 학습 프로세스를 상당히 가속화하고 더 나은 정확도에 공헌한다. [CLS] 및 [SEP]와 관련된 hidden state가 pre-train 중에 학습되지 않음에도 불구하고 VQA의 학습 프로세스가 크게 단축되는 것은 가치가 없다. 이는 vision-language representation이 본 적 없는 도메인과 작업에 대해서 잘 일반화하고, 새로운 task에 대해서도 합리적이게 잘 작동한다는 것을 가리킨다.
- pre-training이 전혀 없는 base model
- bi-directional language pre-training. BERT로부터 초기화된 모델
- seq2seq & bi-directional language pre-training. UniLM으로부터 초기화된 모델
- full Vision-Language Pre-training.
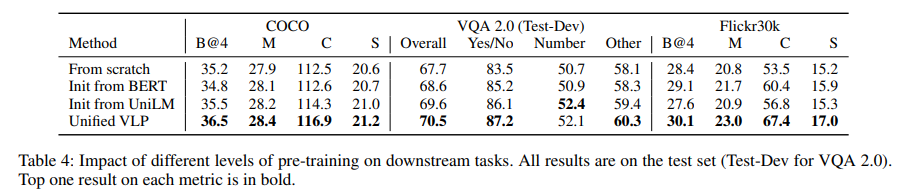
논문에서는 또한 caption 생성의 측면에서 위 3개의 vision-language pre-training이 어떻게 영향을 미치는지 분석하였다. 그 결과 순수 language pre-training으로부터 가중치를 전달받아서 base model을 초기화하는 것이 vision-language pre-training에 이점을 가진다는 것을 보여줬다.
Region object labels as pretext. 기존의 연구들에서는 region object label($C_i$)을 image region feature을 풍족하게 하기 위한 중요한 보조로 생각하였고, 논문에서도 이와 비슷한 디자인을 사용하였다. 논문에서는 대신에 이 라벨을 masked region 분류 구실로 사용하였다. 여기서 두 개의 디자인 선택에 대해 비교를 진행하였다. "region label 확률이 입력값"이 full model Unified VLP와 동등하고, "region label as pretext"이 다른 응용으로 사용되었다. 결과에서 보이듯이 class label을 pretext로 예측하는 것은 captioning 성능 측면에서 pre-training에 대해 안 좋은 영향을 끼친다. 논문에서는 이것이 object detector의 클래스 라벨이 학습된 feature representation을 손상시키는 노이즈가 있을 수 있기 때문이라고 가정하였다. 이와는 반대로 논문의 모델은 더욱 신뢰적인 MLM을 통해 visual representation을 개선하였고, 클래스 라벨에 존재하는 오류를 올바르게 하였다.
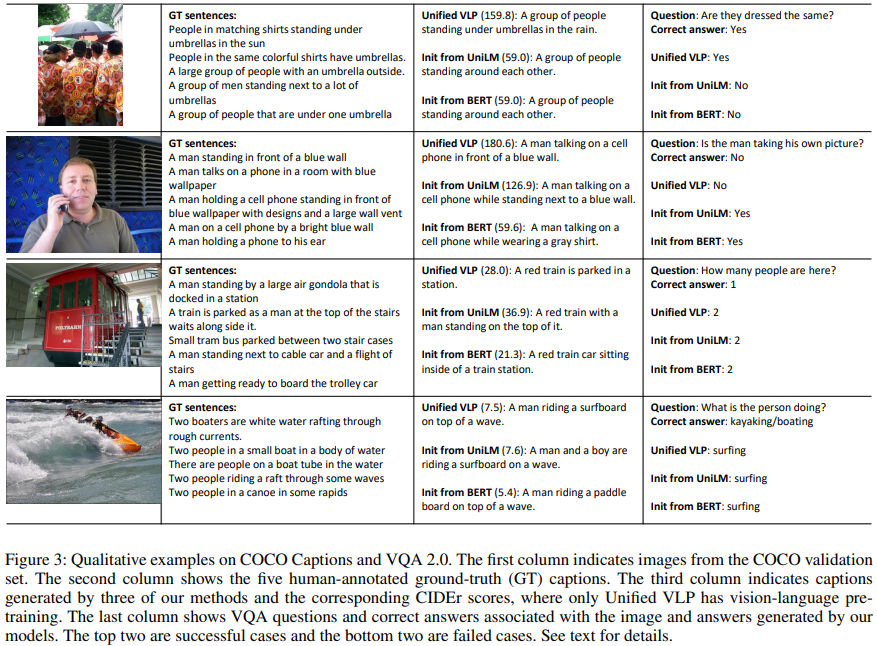
Qualitative results & analyses. 그림 3에서 COCO Captions와 VQA 2.0에 대한 qualitative 예시를 보여주고 있다. 첫 두 개의 예시에 대해서 vision-language pre-training을 사용한 full model은 이미지에서 더 많은 디테일을 캡처한다. 그리고 질문에 대해서도 올바른 대답을 내놓는다. 세 번째 예시에서는 모든 method가 시각적 유사성 때문에 곤돌라를 기차로 잘못 파악하였다. question answering으로 왔을 때, 논문의 method는 올바른 대답을 내놓지만 GT answer는 부정확한 대답을 내놓는다. 네 번째 예시에 대해서는 모든 모델이 실제로는 보트 또는 카약을 타는 활동이지만, 서핑으로 잘못 분류하였다. 이것은 caption model과 VQA model 모두에서 일관적이었는데, 이는 feature representation이 실제로 작업 간에 공유됨을 의미한다.
출처
https://arxiv.org/abs/1909.11059
Unified Vision-Language Pre-Training for Image Captioning and VQA
This paper presents a unified Vision-Language Pre-training (VLP) model. The model is unified in that (1) it can be fine-tuned for either vision-language generation (e.g., image captioning) or understanding (e.g., visual question answering) tasks, and (2) i
arxiv.org
'Paper Reading 📜 > multimodal models' 카테고리의 다른 글
The overview of this paper
이 논문에서는 통합된 Vision-Language Pre-training(VLP) model을 제안하였다. 모델은 다음의 두 가지를 통합하였다. 이로 인해 VLP는 encoder와 decoder를 서로 다른 각기의 모델로 구현한 method들과 다른 점을 가지게 되었다.
- visual-language 이해 또는 생성을 위해 fine-tune
- encoding & decoding을 위해 공유된 multi-layer transformer를 사용
통합 VLP model은 2개의 task에 대한 unsupervised learning 목표를 사용해서 거대한 양의 image-text 짝에서 pre-train 되었다: bi-directional & sequence-to-sequence(seq2seq) masked vision-language 예측. 두 task는 예측 조건이 어떤 컨텍스트에 있는지에 따라 다르다. 이는 공유 Transformer 네트워크에 대한 특정 self-attention mask를 활용하여 제어된다. VLP는 처음으로 서로 다른 vision-language 생성 및 이해 task인, image captioning과 visual question answering에서 SoTA를 달성하였다.
Table of Contents
1. Introduction
2. Vision-Language Pre-training
2-1. Vision-Language Transformer Network
2-2. Pre-training Objectives
3. Fine-tuning for Downstream Tasks
3-1. Image Captioning
3-2. Visual Question Answering
4. Experiments & Results
1. Introduction
다음의 표 1은 최근의 연구들에서 BERT로부터 만들어진 vision-language pre-training 모델들에 대해 요약해서 보여주고 있다. 이 모델들은 2단계의 학습 스키마를 가지고 있는데, 이는 다음과 같다.
- 첫 번째 단계: pre-training. 거대한 양의 image-text 짝에서 intra-modality 또는 cross-modality 관계에 기반해서 masked word 혹은 image region을 예측함으로써 vision-language representation을 학습함.
- pre-trained model은 downstream task에 적응하기 위해 fine-tune 된다.
서로 다른 pre-trained model을 사용하여 각각의 downstream task에 대해서 상당한 성능 향상을 보여줬지만, 범용적으로 응용 가능한 하나의 통합된 모델을 pre-train 하는 것은 어려운 과제로 남아있다. 지금까지의 대부분의 pre-trained model들은 understanding task에서만 발전되었고, 이들은 표 1에 'understanding-based only'로 표시되어 있다. 또는 생성 task를 위해 따로따로 학습되어야 하는 다양한 modality-specific encoder와 decoder로 이루어져 있는 하이브리드 모델이다. 예를 들어, 표 1의 VideoBERT와 CBT는 pre-training을 encoder에서만 하고 decoder에서는 하지 않는다. 이는 encoder에 의해 학습되는 cross-modal representation과 생성을 위한 decoder에 의해 필요한 representation 사이에 불일치가 발생할 수 있는데, 이는 모델의 일반성을 해칠 수 있다. 이 논문에서는 이 불일치를 제거하고 encoding과 decoding 둘 모두에 관한 통합된 representation을 pre-training 하는 방법에 대해 찾아내었다. 이러한 통합된 representation은 더욱 효과적인 cross-task 지식 공유와 서로 다른 task에 대해 서로 다른 pre-training을 할 필요가 없기 때문에 개발 비용을 줄여준다.
이것을 위하여 vision-language 생성 및 이해 task 둘 모두에 대해 fine-tune될 수 있는 통합 encoder-decoder model인 Vision-Language Pre-training(VLP)를 제안하였다. VLP model은 encoding과 decoding을 위해 공유 multi-layer Transformer 네트워크를 사용하고, 거대한 양의 image-caption 짝에서 pre-train 되고, 2개의 unsupervised vision-language task에 대해 최적화된다: bi-directional & seq2seq masked language prediction. 두 task는 예측 조건이 어떤 컨텍스트에 있는지에 따라 다르다. 이는 공유 Transformer 네트워크에 대한 특정 self-attention mask를 활용하여 제어된다.
제안된 VLP model은 표 1의 다른 BERT 기반 모델들에 비해 2가지의 이점을 가진다.
- encoder & decoder를 통합해서 범용적 vision-language representation을 더욱 학습. 이로 인해 vision-language 생성과 이해 task에서 더욱 쉽게 fine-tune 됌.
- 통합된 pre-training 프로시저는 두 개의 vision-language 예측 task(bi-directional + seq2seq)를 위한 하나의 model architecture를 이끎. 이는 task-specific metric 엄청난 성능 손실 없이 여러 개의 pre-training model, 그리고 서로 다른 유형의 task를 위한 pre-training model을 완화할 필요가 있었다.
2. VIsion-Language Pre-training
논문에서는 입력 이미지를 $I$로 두고 관련된 타깃 문장 설명(words)을 $S$로 표현하였다. 그리고 object detector를 사용해서 이미지로부터 고정된 수 $N$의 object 영역을 추출하였는데, 이를 $\left\{ r_1, ..., r_{N} \right\}$으로 나타내고 해당하는 region feature를 $R = [R_1, ..., R_{N}] \in \mathbb{R}^{d \times N}$로, region object의 라벨을 $C = [C_1, ..., C_N] \in \mathbb{R}^{l \times N}$로, region의 geometric 정보를 $G = [G_1, ..., G_N] \in \mathbb{R}^{o \times N}$으로 나타내었다. 여기서 $d$는 임베딩 크기를 나타내고, $l$은 object detector의 object class의 수를 나타낸다. 여기서 $o = 5$는 region boundary 상자의 왼쪽 상단 및 오른쪽 하단 모서리 좌표에 대한 4개의 값과 상대 영역에 대한 1개의 값으로 구성된다. $S$의 단어들은 one-hot vector로 표현되고 임베딩 사이즈 $e$를 사용하여 word embedding으로 인코딩 된다: $y_t \in \mathbb{R}^{e}$ 여기서 $t \in \left\{ 1, 2, ..., T \right\}$와 $T$는 문장의 길이를 나타낸다.
2-1. Vision-Language Transformer Network
논문의 vision-language Transformer 네트워크는 Transformer encoder와 decoder를 하나의 모델로 통합하였는데, 이것이 그림 2의 왼쪽에 나타나 있다. 모델의 입력은 class-aware region embedding, word embedding, 3개의 스페셜 토큰으로 구성되어 있다. 여기서 region embedding은 다음과 같이 정의된다.
$r_i = W_{r}R_{i} + W_{p}[LayerNorm(W_{c}C_{i})|LayerNorm(W_{g}G_{i})]$
여기서 $[\cdot|\cdot]$은 feature 차원 간의 연결을 나타내고, LayerNorm은 LayerNormalization을 의미한다. 두 번째 항은 BERT의 positional embedding을 흉내 내지만, 추가적인 region class 정보를 추가하고, $W_r, W_p, W_c, W_g$는 임베딩 가중치를 의미한다. 여기서 class-aware region 임베딩을 나타내기 위해 $r_i \in \mathbb{R}^{d} (i \in \left\{ 1, 2, ..., N\right\})$ 표기법을 오버로드한다. 게다가 BERT처럼 segment embedding을 $r_i$에 추가하였다.
word embedding은 BERT와 유사하게 정의되어 $y_t$에 positional embedding과 segment embedding을 추가하고, 이 값은 다시 $y_t$에 오버로드된다. 그리고 3개의 스페셜 토큰 [CLS], [SEP], [STOP]을 정의하였다. [CLS]는 visual 입력의 시작을 나타내고, [SEP]는 visual 입력과 문장 입력 간의 경계를 나타내고, [STOP]는 문장의 끝을 나타낸다. [MASK] 토큰은 masked word를 나타낸다.
2-2. Pre-training Objectives
BERT MLM 목표는 입력 문장에서 랜덤 하게 토큰들은 마스킹해서 학습을 통해 그 마스킹된 토큰의 원래 단어를 예측하도록 학습시키는 방법이다. 이를 위해 모델은 문맥을 파악하는 LM을 생성할 수 있어야 한다. 논문에서는 똑같은 스키마를 따라서 두 개의 구체적인 목표를 고려하였다: bi-directional & seq2seq
그림 2의 오른쪽에서 보이는 것처럼 두 목표의 가장 큰 차이점은 self-attention mask에 있다. bi-directional objective를 위해 사용되는 mask는 양방향성으로 visual & language modality 간에 메시지 흐름이 가능케 한다. 반면에 seq2seq는 미래의 단어는 참조 불가해서 auto-regressive를 만족한다. 이를 공식적으로 표현하면 첫 번째 Transformer block의 입력은 $H^{0} = [r_{[CLS]}, r_1, ..., r_N, y_{[SEP]}, y_1, ..., y_T, y_{[STOP]}] \in \mathbb{R}^{d \times U}$로 정의된다. 여기서 $U = N+T+3$이고, 서로 다른 Transformer의 레벨에서 encoding은 $H^{l} = Transformer(H^{l-1}), l \in [1, L]$로 정의된다. 논문에서는 추가적으로 self-attention mask를 $M \in \mathbb{R}^{U \times U}$로 정의하였고, 여기서
$M_{jk} = \left\{\begin{matrix}
0, allow to attend \\ -\infty, prevent from attending
\end{matrix}\right.$
간단함을 위해 논문에서는 self-attention 모듈에서 하나의 attention head를 가정하였다. 그다음에 $H^{l-1}$에서 self-attention 출력은 다음과 같이 정의된다:
$A^{l} = softmax(\frac {Q^{\top}K}{\sqrt{d}} + M)V^{\top}, $
$V = W_{V}^{l}H^{l-1}, Q = W_{Q}^{l}H^{l-1}, K = W_{K}^{l}H^{l-1}$
여기서 $W_{V}^{l}, W_{Q}^{l}, W_{K}^{l}$은 임베딩 가중치이다. 중간 변수 $V, Q, K$는 self-attention처럼 각각 value, query, key를 나타낸다. $A^{l}$은 출력 $H^{l}$을 형성하기 위해 residual connection을 사용한 feed-forward layer을 사용함으로써 추가적으로 encoding 되었다. pre-training 중에 논문에서는 두 objective 간에 per-batch를 번갈아 나오게 하고 seq2seq와 bi-directional의 비율을 하이퍼 파라미터 $\lambda$와 $1 - \lambda$를 사용해서 정의하였다.
논문에서는 실험을 통해 region class 확률($C_i$)을 region feature($r_i$)에 통합하는 것이 성능 향상을 이끈다는 것을 보여줬다. 그래서 visual representation을 개선하기 위해 masked region 예측 task가 사용되는 기존의 작업과 다르게, masked language 재건축을 활용함으로써 간접적으로 visual representation을 개선시켰다. 논문에서는 또한 작업이 seq2seq 또는 bi-directional보다 약할 뿐만 아니라 계산 비용이 많이 들기 때문에 BERT에서 또는 이미지와 텍스트 사이의 일치를 예측하는 맥락에서 Next Sentence Prediction task를 사용하지 않기로 선택하였다.
Sequence-to-Sequence inference. seq2seq 학습이 수행되는 것과 유사한 방식으로 논문에서는 직접적으로 VLP에 seq2seq 추론을 적용할 수 있었다.
3. Fine-tuning for Downstream Tasks
3-1. Image Captioning
논문에서는 seq2seq objective를 사용하여 pre-trained VLP 모델을 타깃 데이터셋에서 fine-tune 하였다. 추론 중에 논문에서는 우선 image region을 스페셜 토큰 [CLS]와 [SEP]로 encoding 하고 [MASK] 토큰을 주고 word 확률 출력을 샘플링함으로써 생성을 시작하였다. 그다음에 이전 입력 문장의 [MASK] 토큰은 다음 예측을 시작하기 위해 입력 시퀀스에 추가된다. [STOP] 토큰이 선택되면 생성을 멈춰지게 된다.
3-2. Visual Question Answering
논문에서는 VQA를 multi-label 분류 문제로 정의하였다. 이 작업에서는 맨 위의 $k$ 개의 가장 흔한 대답을 대답 vocabulary로 선택하고 클래스 라벨로 사용하는 open domain VQA에 집중하였다. 이전의 연구를 따라서 $k$를 3129로 설정하였다.
fine-tuning 중에 [CLS]와 [SEP]의 마지막 숨겨진 상태의 요서별 곱 위에 다층 퍼셉트론(Linear + ReLU + Linear + Sigmoid)이 학습된다. 논문에서는 모델 출력 점수를 cross-entropy loss를 사용해서 soft answer label에 관하여 최적화하였다. 이전에는 pre-training 중에 타깃 데이터셋을 사용해서 task-specific objective를 사용하였으나, VLP의 pre-training은 그럴 필요가 없기 때문에 더욱 general 해진다.
4. Experiments & Results
Data preparation & Implementation details. 이 부분에 관해서는 본 포스트에서 따로 다루지 않을 테니 이 부분에 대해 궁금하다면 논문을 참고하길 바란다.
Model variants & metrics. VLP의 pre-training의 효과를 설명하기 위해, 논문에서는 처음에 pre-training을 사용하지 않는 baseline을 포함하였다. 그다음에 모델에 극한의 세팅인 $\lambda = 1$ (seq2seq pre-training only)와 $\lambda = 0$ (bi-directional only)를 포함하여 어떻게 각각의 objective가 서로 다른 downstream task에 대해 작동하는지 알아보았다. full model은 이 두 objective 간에 공동으로 학습된다. fine-tuning은 pre-training의 구성에 연연하지 않고 똑같이 수행되었다. 논문에서는 image captioning을 위한 일반적인 language metrics를 사용하였다. 여기에는 VQA의 정확도를 측정하는 Bleu@4, METEOR, CIDEr, SPICE가 포함되어 있다.
Comparisons agains SoTAs. test set에서 VLP와 SoTA method를 비교한 결과가 표 2에 나타나 있다. 논문에서는 published SoTA의 작업(표 2의 위쪽 부분), unpublished work의 작업(표 2의 중간 부분), VLP(표 2의 아래쪽 부분)을 포함하였다. 모든 image captioning method는 공정한 비교를 위해서만 cross-entropy 최적화를 사용하는 단일 모델이다. 논문의 full model(Unified VLP)은 COCO의 4개 지표 중 3개, VQA 2.0의 전체 정확도 및 Flickr30k의 4개 지표 모두에서 SoTA를 능가한다. 성능 향상은 CIDEr 지표에서 5.1%, BLEU@4에서 2.8%의 이득을 얻었고, Flickr30k에서 특히 좋았다.
Boost from pre-training. 논문의 full model은 baseline model이 대부분의 metric에 대해서 상당한 마진을 남길 수 있게 해 줬고, 그래서 VLP의 pre-training 방법에 감사를 표한다. Flickr30k의 CIDEr 메트릭에서 10% 이상의 성능 향상, COCO 및 B@4의 CIDEr에서 2% 이상의 성능 향상, Flickr30k의 METEOR에서 몇 가지 눈에 띄는 개선 사항이 있었다. 작은 데이터셋은 대부분의 vision-language pre-training이 overfitting 문제를 완화시키는데 이점을 주었다. 두 개의 극한의 세팅의 모델들은 각자가 '선호'하는 task에 대해서 더욱 잘 작동하는 모습을 보여줬다. 예를 들어 seq2seq pre-training alone은 downstream captioning task에서 상당한 성능 향상을 보여줬고, bi-directional pre-training alone은 understanding task에서 서 이점을 보여줬다. 하지만 반대에 대해서는 그렇지 않았다. 이들 각각은 VQA 2.0에서 정확도 면에서 새로운 SoTA를 달성하였다. 공동 학습은 다소 다른 두 가지 목표에서 학습한 representation을 유기적으로 결합하고 모든 downstream task에서 약간 손상되었지만 적절한 정확도를 제공한다. 이는 engineering 관점에서, 생성 task 또는 이해 task에 대해서 별개의 pre-training model를 가진다면, 최적의 모델 성능을 얻을 수 있다는 것을 말한다. model architecture와 파라미터 공유를 중요하게 생각한다면 공동 학습은 좋은 절충안이다.
Impact of pre-training types. base model Transformer가 어떻게 초기화되느냐에 따라서 논문에서는 4개의 pre-training 정도를 약한 것에서부터 강한 것까지 정의하였다. 이에 대해서 downstream task에 대해 fine-tuning 한 결과는 다음의 그림 1과 표 3에 나타나 있다. 그림 1에서 보이는 것처럼 vision-language pre-training은 downstream task의 학습 프로세스를 상당히 가속화하고 더 나은 정확도에 공헌한다. [CLS] 및 [SEP]와 관련된 hidden state가 pre-train 중에 학습되지 않음에도 불구하고 VQA의 학습 프로세스가 크게 단축되는 것은 가치가 없다. 이는 vision-language representation이 본 적 없는 도메인과 작업에 대해서 잘 일반화하고, 새로운 task에 대해서도 합리적이게 잘 작동한다는 것을 가리킨다.
- pre-training이 전혀 없는 base model
- bi-directional language pre-training. BERT로부터 초기화된 모델
- seq2seq & bi-directional language pre-training. UniLM으로부터 초기화된 모델
- full Vision-Language Pre-training.
논문에서는 또한 caption 생성의 측면에서 위 3개의 vision-language pre-training이 어떻게 영향을 미치는지 분석하였다. 그 결과 순수 language pre-training으로부터 가중치를 전달받아서 base model을 초기화하는 것이 vision-language pre-training에 이점을 가진다는 것을 보여줬다.
Region object labels as pretext. 기존의 연구들에서는 region object label($C_i$)을 image region feature을 풍족하게 하기 위한 중요한 보조로 생각하였고, 논문에서도 이와 비슷한 디자인을 사용하였다. 논문에서는 대신에 이 라벨을 masked region 분류 구실로 사용하였다. 여기서 두 개의 디자인 선택에 대해 비교를 진행하였다. "region label 확률이 입력값"이 full model Unified VLP와 동등하고, "region label as pretext"이 다른 응용으로 사용되었다. 결과에서 보이듯이 class label을 pretext로 예측하는 것은 captioning 성능 측면에서 pre-training에 대해 안 좋은 영향을 끼친다. 논문에서는 이것이 object detector의 클래스 라벨이 학습된 feature representation을 손상시키는 노이즈가 있을 수 있기 때문이라고 가정하였다. 이와는 반대로 논문의 모델은 더욱 신뢰적인 MLM을 통해 visual representation을 개선하였고, 클래스 라벨에 존재하는 오류를 올바르게 하였다.
Qualitative results & analyses. 그림 3에서 COCO Captions와 VQA 2.0에 대한 qualitative 예시를 보여주고 있다. 첫 두 개의 예시에 대해서 vision-language pre-training을 사용한 full model은 이미지에서 더 많은 디테일을 캡처한다. 그리고 질문에 대해서도 올바른 대답을 내놓는다. 세 번째 예시에서는 모든 method가 시각적 유사성 때문에 곤돌라를 기차로 잘못 파악하였다. question answering으로 왔을 때, 논문의 method는 올바른 대답을 내놓지만 GT answer는 부정확한 대답을 내놓는다. 네 번째 예시에 대해서는 모든 모델이 실제로는 보트 또는 카약을 타는 활동이지만, 서핑으로 잘못 분류하였다. 이것은 caption model과 VQA model 모두에서 일관적이었는데, 이는 feature representation이 실제로 작업 간에 공유됨을 의미한다.
출처
https://arxiv.org/abs/1909.11059
Unified Vision-Language Pre-Training for Image Captioning and VQA
This paper presents a unified Vision-Language Pre-training (VLP) model. The model is unified in that (1) it can be fine-tuned for either vision-language generation (e.g., image captioning) or understanding (e.g., visual question answering) tasks, and (2) i
arxiv.org