
The overview of this paper
image-text 쌍에서 cross-modal representation 학습의 대규모 pre-training method는 vision-language task에서 유명해졌다. 하지만 기존의 방법들은 그저 image region feature와 text feature을 연결하기만 할 뿐, 다른 조치를 취하지 않았다. 그래서 이 논문에서는 이미지에서 감지된 object tag를 anchor point로 사용하는 새로운 학습 방법인 Oscar을 소개하였다. 이로 인해 정렬의 학습을 더욱 쉽게 해 주었다. 이 method는 object detector로부터 가장 중요한 object가 감지될 테고, paired text에서 이 object 종종 언급될 것이라는 생각으로부터 만들어졌다.
Table of Contents
1. Introduction
2. Background
3. Oscar Pre-training
4. Experimental Results & Analysis
4-1. Performance comparison with SoTA
4-2. Qualitative Studies
4-3. Abaltion Analysis
1. Introduction
최근의 vision-language pre-training(VLP)에 관한 연구들은 방대한 양의 image-text 쌍으로부터 generic representaion을 효과적으로 학습할 수 있고, task-specific 데이터셋에서 VLP model을 fine-tuning 하여 SoTA도 달성하였다. 이러한 VLP model들은 multi-layer Transformer에 기반을 두고 있다. 이러한 모델을 pre-train 하기 위해, 기존의 method들은 image region feature와 text feature의 연결을 입력으로 하고 image region과 text 간의 semantic 정렬을 학습하기 위해 self-attention 메커니즘을 사용하였다. 하지만 image region과 text 간의 분명한 정렬 정보의 부족은 정렬 모델링을 약한 supervised learning task로 만들었다. 게다가 visual region은 over-sample 돼서 잡음과 모호성이 섞여 있는데, 이는 task를 더욱 어렵게 만든다.
논문에서는 이미지에서 감지된 object tag를 anchor point로 활용해서 이미지와 텍스트 간의 semantic 정렬의 학습을 쉽게 함으로써 cross-modal representation의 학습을 상당히 향상시켰다. 이렇게 하여 새로운 VLP method인 OSCAR을 소개하였다. OSCAR에서 training example을 3개로 구성하였는데, 각각은 word sequence, object tag 세트, image region feature 세트이다. 다음의 그림 1은 OSCAR의 전반적인 세팅에 대해서 보여주고 있다.
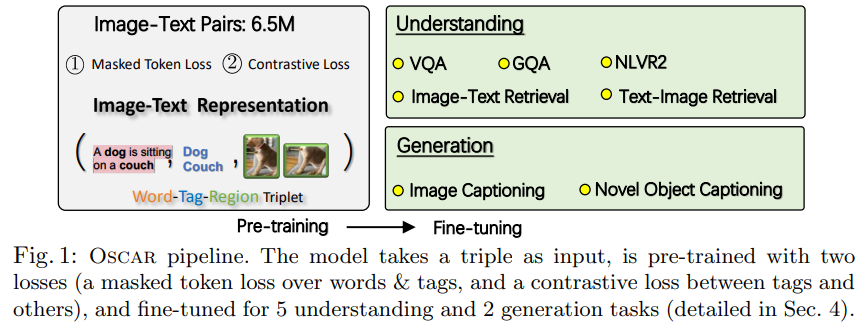
이 논문의 주된 contribution은 다음과 같이 요약된다:
- V+L(Vision+Language) 이해와 생성 task를 위한 generic image-text representation을 학습하기 위한 강력한 VLP method인 OSCAR을 소개하였다.
- OSCAR 모델은 multiple V+L 벤치마크에서 새로운 SoTA를 달성하였고, 기존의 방법들에 비해 상당한 마진으로 향상된 성능을 보여줬다.
- cross-modal representation 학습과 downstream task를 위해 object tag를 anchor point로 사용하는 것의 효과를 알아보기 위해 광범위한 실험과 분석을 제공하였다.
2. Background
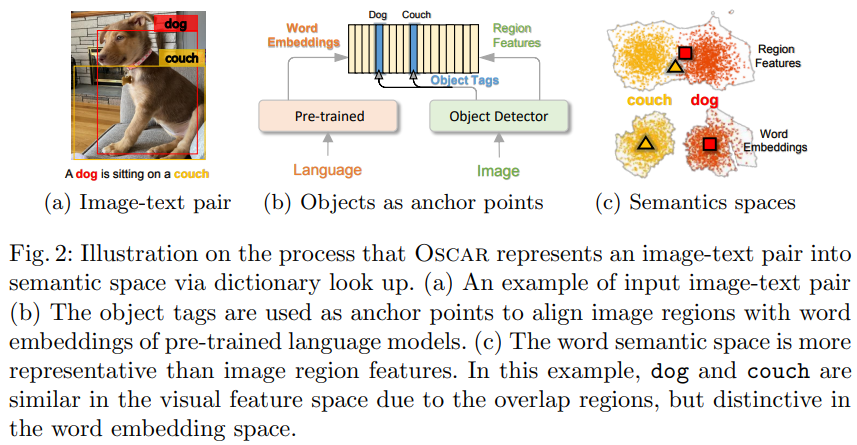
다양한 V+L task를 위한 학습 데이터는 그림 2의 a처럼 image-text 쌍으로 구성되어 있다. 데이터셋의 사이즈를 $N$으로 정의해서 $D = \left\{ (\mathbf{I}_{i}, \mathbf{w}_{i})\right\}_{i=1}^{N}$를 이미지 $\mathbf{I}$와 텍스트 시퀀스 $\mathbf{w}$을 사용하여 정의하였다. OSCAR의 pre-training의 목표는 self-supervised 매너에서 image-text 쌍의 cross-modal representation을 학습하는 것이다. 이것은 다양한 downstream task에 fine-tuning을 통해 적용될 수 있다.
VLP는 각 modality의 singular 임베딩에 기반해서 cross-modal contextualized representation을 학습하기 위해 보통 multi-layer self-attention Transformer을 사용한다. 따라서 VLP의 성공은 근본적으로 입력 singular embedding의 퀄리티에 의존한다. 현존하는 VLP method들은 이미지의 visual region feature $\textbf{v} = \left\{ v_1, ..., v_K\right\}$와 word embedding $\textbf{w} = \left\{ w_1, ..., w_T\right\}$의 쌍을 입력으로 하고, image-text 정렬을 학습하고 cross-modal contextual representation을 생성하기 위해 self-attention 메커니즘에 의존한다.
그럼에도 불구하고 기존의 VLP method들은 다음의 2가지 문제점을 겪고 있다. 이를 해결하기 위해 논문에서는 이 문제점들을 해결하기 위해 anchor point를 활용하는 새로운 VLP method를 제안하였다.
- 모호성. region feature가 잘 구분되지 않도록 추출되는 문제. 그림 2의 a를 보면 dog과 couch의 region feature가 불분명하게 추출되서 오버랩이 있다.
- grounding 부족. 이미지에서 region 혹은 obejct 간에, 그리고 텍스트에서 단어 또는 구문 간에 명확하게 라벨링된 정렬이 없기 때문에 VLP는 weakly-supervised 학습이다.
3. Oscar Pre-training
사람은 채널을 통해 세상을 인식한다. 이 과정에서 많은 잡음과 모호성을 포함하기는 해도 여러 채널을 공유해서 세상을 인식할 수 있다. 이러한 동기와 함께, 논문에서는 semantic 레벨에서 channel-invariant 요인을 캡처하는 representation을 학습하기 위한 새로운 VLP method인 Oscar을 제안하였다. Oscar는 입력 image-text 쌍이 표현되는 방식과 그림 3에 설명된 대로 pre-training 목표가 기존 VLP와 다르다.
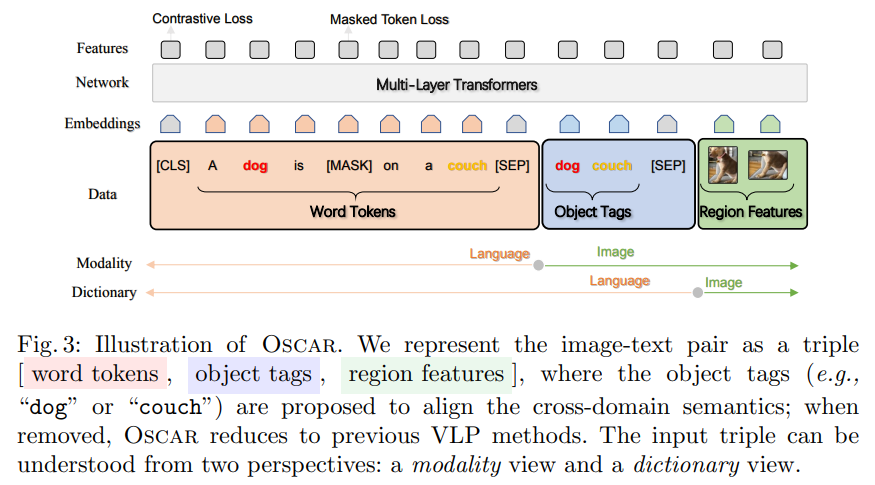
Input
Oscar는 각각의 입력 image-text 쌍을 Word-Tag-Image 쌍 ($\mathbf{w}, \mathbf{q}, \mathbf{v}$)으로 표현하였다. 여기서 $\mathbf{w}$는 텍스트의 워드 임베딩의 시퀀스이고, $\mathbf{q}$는 이미지로부터 탐지된 object tag의 워드 임베딩 시퀀스이고, $\mathbf{v}$는 이미지의 region vector 세트이다.
기존의 VLP method들과 달리 Oscar는 새로운 $\mathbf{q}$를 소개하고, image-text 정렬의 학습을 쉽게 하기 위해 anchor point로 활용하였다. 이는 학습 데이터에서 이미지의 중요한 object가 object tag와 동일한 단어 또는 다르지만 의미상 유사하거나 관련된 단어를 사용하여 이미지 쌍 텍스트에도 종종 표시된다는 관찰에 의해 시작되었다. 텍스트에서 $\mathbf{q}$와 $\mathbf{w}$ 간의 정렬은 Oscar에서 VLP를 위한 초기화로 사용되는 pre-trained BERT 모델을 사용하여 비교적 쉽게 식별되기 때문에 object tag가 감지되는 이미지 영역이 될 가능성이 높다. 텍스트에서 의미론적으로 관련된 단어로 쿼리 할 때 다른 region보다 더 높은 attention 가중치를 갖는다. 이러한 정렬 프로세스가 그림 2의 b에 설명되어 있다. 이러한 프로세스는 vision space에서 모호하게 표현되어 있는 image object를 ground 하기 위한 학습으로 해석될 수 있다. vision sapce에서 모호하게 표현된 image object는 그림 2의 a에 나타나 있고, language space에서 독특한 객체는 그림 2의 c에 나타나 있다.
특히, $\mathbf{v}$와 $\mathbf{q}$는 다음과 같이 생성된다. $K$ 개의 object region을 가지는 이미지가 주어지면, 각 region의 visual semantic을 $(v', z)$로 추출한다. 이때 $v'$은 region feature이고, $z$는 region position이다. 이렇게 얻어진 $v'$과 $z$를 합쳐서 position-sensitive region feature vector를 만들었고, 이 벡터에 linear projection을 가해서 word embedding과 똑같은 벡터 차원을 만든다.
Pre-training Objective
Oscar의 입력은 두 가지 관점에서 볼 수 있다.
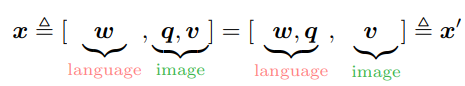
여기서 $\mathbf{x}$는 텍스트와 이미지 간의 representation을 구분하기 위한 modality 관점이다. $\mathbf{x}'$은 서로 다른 두 개의 semantiv space를 구분하기 위한 dictionary view이다. 두 개의 view는 새로운 pre-training 목표를 디자인할 수 있도록 해주었다.
Dictionary View: Masked Token Loss. object tag와 word token은 똑같은 linguistic semantic space를 공유하는 반면, image region feature는 visual semantic space에 있다. 논문에서는 별개의 토큰 시퀀스를 $\mathbf{h} \doteq [\mathbf{w}, \mathbf{q}]$으로 정의하고, pre-training을 위해 Masked Token Loss(MTL)을 적용하였다. $\mathbf{h}_{\setminus i}$와 모든 이미지 feature $v$를 사용해서 negative log-likelihood를 최소화함으로써 masked token의 원래 단어를 예측한다.
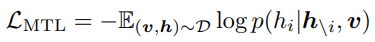
Modality View: Contrastive Loss. 세 개의 입력에 대해 $\mathbf{h}' \doteq [\mathbf{q}, \mathbf{v}]$는 이미지 modality로 그룹 하였고, $\mathbf{w}$는 language modality로 표현하였다. $\mathbf{q}$를 50% 확률로 데이터셋으로부터 랜덤 하게 샘플링된 tag sequence를 대체함으로써 '오염된' 이미지 representation을 샘플링하였다. 한 마디로 $(\mathbf{h}', \mathbf{w})$ 쌍이 original 이미지 representation을 포함하는지 polluted를 포함하는지 예측하는 것이다. contrastive loss는 다음과 같이 정의된다.
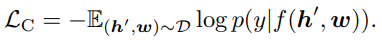
cross-modal pre-training 중에, 논문에서는 BERT의 워드 임베딩 공간을 조정하기 위해 object tag를 이미지의 대용물처럼 활용하였다. 여기서 텍스트는 쌍을 이룬 이미지와 유사하고, polluted와는 유사하지 않다. 이를 통해 얻은 Oscar의 pre-training 목표는 다음과 같다.
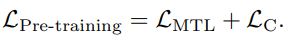
Discussion. 다른 손실 함수가 pre-training 목표로 사용될 수도 있었으나 다음의 이유로 인해 위의 두 개의 loss를 사용하였다.
- 각각의 loss는 각각의 관점으로부터 representative learning signal을 제공해줌. 이는 dictionary & modality view의 효과에 대해 연구하기 위함.
- 전반적인 loss는 VLP method에 존재하는 것보다 간단함. 이는 논문의 실험에서 상당한 성능을 산출한다.
이렇게 해서 논문에서는 pre-trained model을 총 7개의 downstream V+L task에 적용하였다. 여기에는 5개의 understanding task와 2개의 generation task로 구성되어 있다.
4. Experimental Results & Analysis
4-1. Performance Comparison with SoTA
파라미터 효율성을 설명하기 위해 논문에서는 Oscar를 3개의 유형의 SoTA와 비교하였다.
- SoTA_S: Transformer 이전의 small models
- SoTA_B: BERT base와 크기가 유사한 VLP models
- SoTA_L: BERT large와 크기가 유사한 VLP models
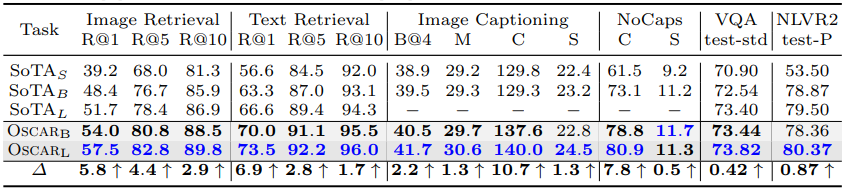
표 1은 모든 task에 대한 전반적인 결과를 요약하고 있다. 이 논문의 모든 표에서, 파란색은 task에 대한 최고의 결과를 나타내고, 회색배경은 Oscar에 의해 나온 결과를 의미한다. 결과를 보면 Oscar는 대부분의 task에서 이전의 large model보다 큰 마진을 가지고 향상된 성능을 보여주는 것을 알 수 있다. 이는 Oscar가 파라미터 효율적이라는 것을 말한다. Oscar는 object tag를 anchor point로 사용함으로써 이미지와 텍스트 간의 semantic 정렬의 학습을 쉽게 만들어 준다.
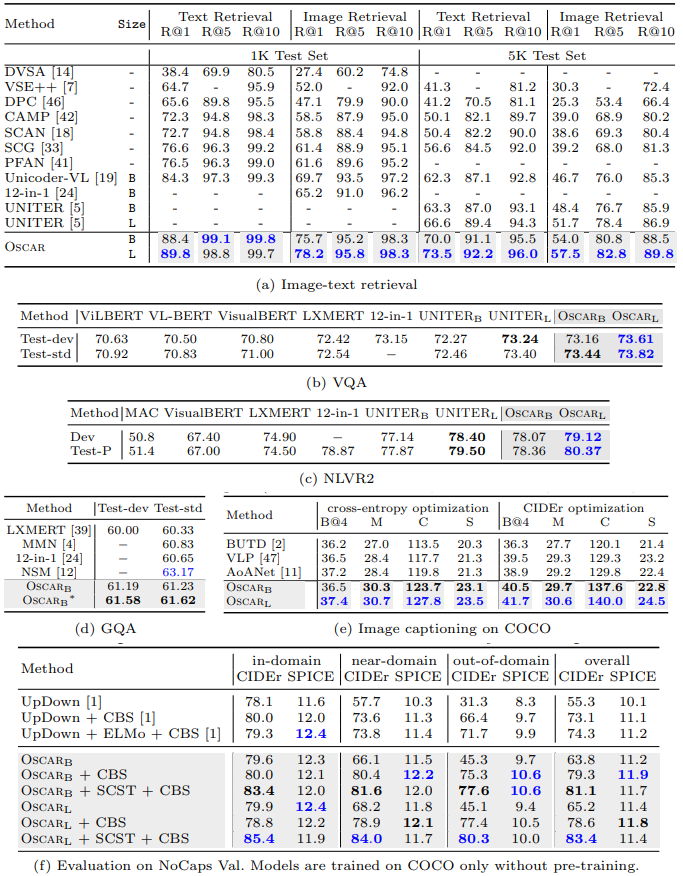
표 2에서는 각각의 task에 대해 디테일한 비교를 기록하였다.
- VLP method가 이전 small model보다 우세한 성능을 보여줬다. Oscar는 7개의 task에서 모두 능가하는 성능을 달성하고 6개의 task에서 SoTA를 달성하였다.
- 모델이 single task fine-tuning을 기반으로 한다는 점을 감안할 때 결과는 제안된 pre-training의 효과를 보여준다.
- Oscar는 이해 및 생성 task에서 모두 가장 좋은 성능을 보여줬다. SCST를 활용해 fine-tuning 한 결과 더 나은 성능을 보여줬다.
- NoCaps에서, BERT로 초기화하고 COCO captioning 데이터셋과 Constrained Beam Search(CBS)를 사용해서 이전의 SoTA를 능가하는 성능을 보여줬다.
4-2. Qualitative Studies
논문에서는 COCO test set의 image-text 쌍의 학습된 feature 공간을 2D map에 시각화하였다. object tag를 사용해서 pre-train 한 모델과, 사용하지 않고 pre-train 한 모델을 비교하였다. 그림 4의 결과는 흥미로운 발견을 찾아내었다. 그리고 이 발견은 object tag의 중요성을 입증하였다.
- Intra-class: object tag의 도움으로 똑같은 object의 두 modality 간의 거리는 상당히 줄었다.
- Inter-class: 관련된 semantic의 object class는 tag를 추가한 후에 점점 가까워졌다.

논문에서는 서로 다른 모델의 생성된 캡션을 그림 5에서 비교하였다. baseline method는 object tag를 사용하지 않은 VLP이다. 결과를 보면 Oscar가 baseline에 비해 이미지의 더욱 디테일한 설명을 생성하는 걸 알 수 있는데, 이는 정확하고 다양한 object tag를 사용했기 때문이다. 이들은 워드 임베딩 공간에서 anchor point이고, 텍스트 생성 프로세스를 가이드한다.

4-3. Ablation Analysis
논문에서는 네 가지 대표적인 downstream task에 대한 상대적 중요성을 더 잘 이해하기 위해 pre-training 및 fine-tuning 모두에서 Oscar의 여러 설계 선택에 대해 ablation study를 수행하였다.
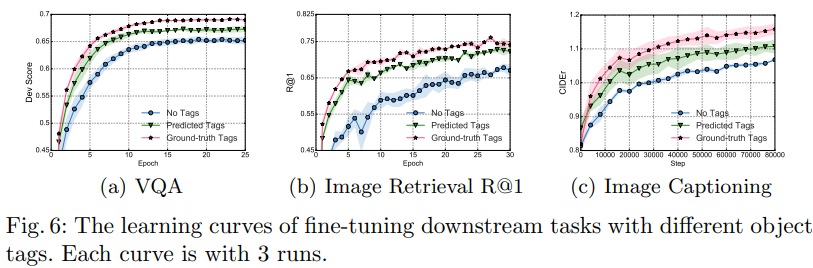
The Effect of Object Tags object tag의 효과를 파악하기 위해 총 3개의 세팅에서 ablation study를 진행하였다: Baseline(No tag), Predicted Tags, Ground-truth Tags. 그 결과 object tag를 사용하여 fine-tuning 한 learning curve가 VLP method에 비해 더욱 빠르고 더 나은 결과로 수렴하는 것을 알 수 있었다.
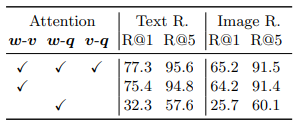
Attention Interaction text & object tag & object region 간의 상호 작용을 파악하기 위해 ablation study를 진행하였다. 그 결과 다음과 같은 결과를 얻을 수 있었다.
- object tag를 추가하는 것이 이익
- region feature가 object tag보다 더욱 정보적임
- tag를 feature로 사용하는 것은 그저 그랬음. anchor point로 사용해야 함.
출처
https://arxiv.org/abs/2004.06165
Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks
Large-scale pre-training methods of learning cross-modal representations on image-text pairs are becoming popular for vision-language tasks. While existing methods simply concatenate image region features and text features as input to the model to be pre-t
arxiv.org
'Paper Reading 📜 > multimodal models' 카테고리의 다른 글
The overview of this paper
image-text 쌍에서 cross-modal representation 학습의 대규모 pre-training method는 vision-language task에서 유명해졌다. 하지만 기존의 방법들은 그저 image region feature와 text feature을 연결하기만 할 뿐, 다른 조치를 취하지 않았다. 그래서 이 논문에서는 이미지에서 감지된 object tag를 anchor point로 사용하는 새로운 학습 방법인 Oscar을 소개하였다. 이로 인해 정렬의 학습을 더욱 쉽게 해 주었다. 이 method는 object detector로부터 가장 중요한 object가 감지될 테고, paired text에서 이 object 종종 언급될 것이라는 생각으로부터 만들어졌다.
Table of Contents
1. Introduction
2. Background
3. Oscar Pre-training
4. Experimental Results & Analysis
4-1. Performance comparison with SoTA
4-2. Qualitative Studies
4-3. Abaltion Analysis
1. Introduction
최근의 vision-language pre-training(VLP)에 관한 연구들은 방대한 양의 image-text 쌍으로부터 generic representaion을 효과적으로 학습할 수 있고, task-specific 데이터셋에서 VLP model을 fine-tuning 하여 SoTA도 달성하였다. 이러한 VLP model들은 multi-layer Transformer에 기반을 두고 있다. 이러한 모델을 pre-train 하기 위해, 기존의 method들은 image region feature와 text feature의 연결을 입력으로 하고 image region과 text 간의 semantic 정렬을 학습하기 위해 self-attention 메커니즘을 사용하였다. 하지만 image region과 text 간의 분명한 정렬 정보의 부족은 정렬 모델링을 약한 supervised learning task로 만들었다. 게다가 visual region은 over-sample 돼서 잡음과 모호성이 섞여 있는데, 이는 task를 더욱 어렵게 만든다.
논문에서는 이미지에서 감지된 object tag를 anchor point로 활용해서 이미지와 텍스트 간의 semantic 정렬의 학습을 쉽게 함으로써 cross-modal representation의 학습을 상당히 향상시켰다. 이렇게 하여 새로운 VLP method인 OSCAR을 소개하였다. OSCAR에서 training example을 3개로 구성하였는데, 각각은 word sequence, object tag 세트, image region feature 세트이다. 다음의 그림 1은 OSCAR의 전반적인 세팅에 대해서 보여주고 있다.
이 논문의 주된 contribution은 다음과 같이 요약된다:
- V+L(Vision+Language) 이해와 생성 task를 위한 generic image-text representation을 학습하기 위한 강력한 VLP method인 OSCAR을 소개하였다.
- OSCAR 모델은 multiple V+L 벤치마크에서 새로운 SoTA를 달성하였고, 기존의 방법들에 비해 상당한 마진으로 향상된 성능을 보여줬다.
- cross-modal representation 학습과 downstream task를 위해 object tag를 anchor point로 사용하는 것의 효과를 알아보기 위해 광범위한 실험과 분석을 제공하였다.
2. Background
다양한 V+L task를 위한 학습 데이터는 그림 2의 a처럼 image-text 쌍으로 구성되어 있다. 데이터셋의 사이즈를 $N$으로 정의해서 $D = \left\{ (\mathbf{I}_{i}, \mathbf{w}_{i})\right\}_{i=1}^{N}$를 이미지 $\mathbf{I}$와 텍스트 시퀀스 $\mathbf{w}$을 사용하여 정의하였다. OSCAR의 pre-training의 목표는 self-supervised 매너에서 image-text 쌍의 cross-modal representation을 학습하는 것이다. 이것은 다양한 downstream task에 fine-tuning을 통해 적용될 수 있다.
VLP는 각 modality의 singular 임베딩에 기반해서 cross-modal contextualized representation을 학습하기 위해 보통 multi-layer self-attention Transformer을 사용한다. 따라서 VLP의 성공은 근본적으로 입력 singular embedding의 퀄리티에 의존한다. 현존하는 VLP method들은 이미지의 visual region feature $\textbf{v} = \left\{ v_1, ..., v_K\right\}$와 word embedding $\textbf{w} = \left\{ w_1, ..., w_T\right\}$의 쌍을 입력으로 하고, image-text 정렬을 학습하고 cross-modal contextual representation을 생성하기 위해 self-attention 메커니즘에 의존한다.
그럼에도 불구하고 기존의 VLP method들은 다음의 2가지 문제점을 겪고 있다. 이를 해결하기 위해 논문에서는 이 문제점들을 해결하기 위해 anchor point를 활용하는 새로운 VLP method를 제안하였다.
- 모호성. region feature가 잘 구분되지 않도록 추출되는 문제. 그림 2의 a를 보면 dog과 couch의 region feature가 불분명하게 추출되서 오버랩이 있다.
- grounding 부족. 이미지에서 region 혹은 obejct 간에, 그리고 텍스트에서 단어 또는 구문 간에 명확하게 라벨링된 정렬이 없기 때문에 VLP는 weakly-supervised 학습이다.
3. Oscar Pre-training
사람은 채널을 통해 세상을 인식한다. 이 과정에서 많은 잡음과 모호성을 포함하기는 해도 여러 채널을 공유해서 세상을 인식할 수 있다. 이러한 동기와 함께, 논문에서는 semantic 레벨에서 channel-invariant 요인을 캡처하는 representation을 학습하기 위한 새로운 VLP method인 Oscar을 제안하였다. Oscar는 입력 image-text 쌍이 표현되는 방식과 그림 3에 설명된 대로 pre-training 목표가 기존 VLP와 다르다.
Input
Oscar는 각각의 입력 image-text 쌍을 Word-Tag-Image 쌍 ($\mathbf{w}, \mathbf{q}, \mathbf{v}$)으로 표현하였다. 여기서 $\mathbf{w}$는 텍스트의 워드 임베딩의 시퀀스이고, $\mathbf{q}$는 이미지로부터 탐지된 object tag의 워드 임베딩 시퀀스이고, $\mathbf{v}$는 이미지의 region vector 세트이다.
기존의 VLP method들과 달리 Oscar는 새로운 $\mathbf{q}$를 소개하고, image-text 정렬의 학습을 쉽게 하기 위해 anchor point로 활용하였다. 이는 학습 데이터에서 이미지의 중요한 object가 object tag와 동일한 단어 또는 다르지만 의미상 유사하거나 관련된 단어를 사용하여 이미지 쌍 텍스트에도 종종 표시된다는 관찰에 의해 시작되었다. 텍스트에서 $\mathbf{q}$와 $\mathbf{w}$ 간의 정렬은 Oscar에서 VLP를 위한 초기화로 사용되는 pre-trained BERT 모델을 사용하여 비교적 쉽게 식별되기 때문에 object tag가 감지되는 이미지 영역이 될 가능성이 높다. 텍스트에서 의미론적으로 관련된 단어로 쿼리 할 때 다른 region보다 더 높은 attention 가중치를 갖는다. 이러한 정렬 프로세스가 그림 2의 b에 설명되어 있다. 이러한 프로세스는 vision space에서 모호하게 표현되어 있는 image object를 ground 하기 위한 학습으로 해석될 수 있다. vision sapce에서 모호하게 표현된 image object는 그림 2의 a에 나타나 있고, language space에서 독특한 객체는 그림 2의 c에 나타나 있다.
특히, $\mathbf{v}$와 $\mathbf{q}$는 다음과 같이 생성된다. $K$ 개의 object region을 가지는 이미지가 주어지면, 각 region의 visual semantic을 $(v', z)$로 추출한다. 이때 $v'$은 region feature이고, $z$는 region position이다. 이렇게 얻어진 $v'$과 $z$를 합쳐서 position-sensitive region feature vector를 만들었고, 이 벡터에 linear projection을 가해서 word embedding과 똑같은 벡터 차원을 만든다.
Pre-training Objective
Oscar의 입력은 두 가지 관점에서 볼 수 있다.
여기서 $\mathbf{x}$는 텍스트와 이미지 간의 representation을 구분하기 위한 modality 관점이다. $\mathbf{x}'$은 서로 다른 두 개의 semantiv space를 구분하기 위한 dictionary view이다. 두 개의 view는 새로운 pre-training 목표를 디자인할 수 있도록 해주었다.
Dictionary View: Masked Token Loss. object tag와 word token은 똑같은 linguistic semantic space를 공유하는 반면, image region feature는 visual semantic space에 있다. 논문에서는 별개의 토큰 시퀀스를 $\mathbf{h} \doteq [\mathbf{w}, \mathbf{q}]$으로 정의하고, pre-training을 위해 Masked Token Loss(MTL)을 적용하였다. $\mathbf{h}_{\setminus i}$와 모든 이미지 feature $v$를 사용해서 negative log-likelihood를 최소화함으로써 masked token의 원래 단어를 예측한다.
Modality View: Contrastive Loss. 세 개의 입력에 대해 $\mathbf{h}' \doteq [\mathbf{q}, \mathbf{v}]$는 이미지 modality로 그룹 하였고, $\mathbf{w}$는 language modality로 표현하였다. $\mathbf{q}$를 50% 확률로 데이터셋으로부터 랜덤 하게 샘플링된 tag sequence를 대체함으로써 '오염된' 이미지 representation을 샘플링하였다. 한 마디로 $(\mathbf{h}', \mathbf{w})$ 쌍이 original 이미지 representation을 포함하는지 polluted를 포함하는지 예측하는 것이다. contrastive loss는 다음과 같이 정의된다.
cross-modal pre-training 중에, 논문에서는 BERT의 워드 임베딩 공간을 조정하기 위해 object tag를 이미지의 대용물처럼 활용하였다. 여기서 텍스트는 쌍을 이룬 이미지와 유사하고, polluted와는 유사하지 않다. 이를 통해 얻은 Oscar의 pre-training 목표는 다음과 같다.
Discussion. 다른 손실 함수가 pre-training 목표로 사용될 수도 있었으나 다음의 이유로 인해 위의 두 개의 loss를 사용하였다.
- 각각의 loss는 각각의 관점으로부터 representative learning signal을 제공해줌. 이는 dictionary & modality view의 효과에 대해 연구하기 위함.
- 전반적인 loss는 VLP method에 존재하는 것보다 간단함. 이는 논문의 실험에서 상당한 성능을 산출한다.
이렇게 해서 논문에서는 pre-trained model을 총 7개의 downstream V+L task에 적용하였다. 여기에는 5개의 understanding task와 2개의 generation task로 구성되어 있다.
4. Experimental Results & Analysis
4-1. Performance Comparison with SoTA
파라미터 효율성을 설명하기 위해 논문에서는 Oscar를 3개의 유형의 SoTA와 비교하였다.
- SoTA_S: Transformer 이전의 small models
- SoTA_B: BERT base와 크기가 유사한 VLP models
- SoTA_L: BERT large와 크기가 유사한 VLP models
표 1은 모든 task에 대한 전반적인 결과를 요약하고 있다. 이 논문의 모든 표에서, 파란색은 task에 대한 최고의 결과를 나타내고, 회색배경은 Oscar에 의해 나온 결과를 의미한다. 결과를 보면 Oscar는 대부분의 task에서 이전의 large model보다 큰 마진을 가지고 향상된 성능을 보여주는 것을 알 수 있다. 이는 Oscar가 파라미터 효율적이라는 것을 말한다. Oscar는 object tag를 anchor point로 사용함으로써 이미지와 텍스트 간의 semantic 정렬의 학습을 쉽게 만들어 준다.
표 2에서는 각각의 task에 대해 디테일한 비교를 기록하였다.
- VLP method가 이전 small model보다 우세한 성능을 보여줬다. Oscar는 7개의 task에서 모두 능가하는 성능을 달성하고 6개의 task에서 SoTA를 달성하였다.
- 모델이 single task fine-tuning을 기반으로 한다는 점을 감안할 때 결과는 제안된 pre-training의 효과를 보여준다.
- Oscar는 이해 및 생성 task에서 모두 가장 좋은 성능을 보여줬다. SCST를 활용해 fine-tuning 한 결과 더 나은 성능을 보여줬다.
- NoCaps에서, BERT로 초기화하고 COCO captioning 데이터셋과 Constrained Beam Search(CBS)를 사용해서 이전의 SoTA를 능가하는 성능을 보여줬다.
4-2. Qualitative Studies
논문에서는 COCO test set의 image-text 쌍의 학습된 feature 공간을 2D map에 시각화하였다. object tag를 사용해서 pre-train 한 모델과, 사용하지 않고 pre-train 한 모델을 비교하였다. 그림 4의 결과는 흥미로운 발견을 찾아내었다. 그리고 이 발견은 object tag의 중요성을 입증하였다.
- Intra-class: object tag의 도움으로 똑같은 object의 두 modality 간의 거리는 상당히 줄었다.
- Inter-class: 관련된 semantic의 object class는 tag를 추가한 후에 점점 가까워졌다.
논문에서는 서로 다른 모델의 생성된 캡션을 그림 5에서 비교하였다. baseline method는 object tag를 사용하지 않은 VLP이다. 결과를 보면 Oscar가 baseline에 비해 이미지의 더욱 디테일한 설명을 생성하는 걸 알 수 있는데, 이는 정확하고 다양한 object tag를 사용했기 때문이다. 이들은 워드 임베딩 공간에서 anchor point이고, 텍스트 생성 프로세스를 가이드한다.
4-3. Ablation Analysis
논문에서는 네 가지 대표적인 downstream task에 대한 상대적 중요성을 더 잘 이해하기 위해 pre-training 및 fine-tuning 모두에서 Oscar의 여러 설계 선택에 대해 ablation study를 수행하였다.
The Effect of Object Tags object tag의 효과를 파악하기 위해 총 3개의 세팅에서 ablation study를 진행하였다: Baseline(No tag), Predicted Tags, Ground-truth Tags. 그 결과 object tag를 사용하여 fine-tuning 한 learning curve가 VLP method에 비해 더욱 빠르고 더 나은 결과로 수렴하는 것을 알 수 있었다.
Attention Interaction text & object tag & object region 간의 상호 작용을 파악하기 위해 ablation study를 진행하였다. 그 결과 다음과 같은 결과를 얻을 수 있었다.
- object tag를 추가하는 것이 이익
- region feature가 object tag보다 더욱 정보적임
- tag를 feature로 사용하는 것은 그저 그랬음. anchor point로 사용해야 함.
출처
https://arxiv.org/abs/2004.06165
Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks
Large-scale pre-training methods of learning cross-modal representations on image-text pairs are becoming popular for vision-language tasks. While existing methods simply concatenate image region features and text features as input to the model to be pre-t
arxiv.org