
The overview of this paper
visual & vision-language representation은 전문적인 학습 데이터셋에 심하게 의존하고 있다. vision 응용을 위해서, representation은 ImageNet 또는 OpenImages와 같은 분명한 클래스 라벨이 있는 데이터셋을 사용하여 학습되었다. 그래서 기존에 사용하던 데이터셋의 데이터 수집 방법은 많은 비용이 들기 때문에, 데이터셋의 크기가 제한되고, 학습 모델의 scaling을 방해한다. 이 논문에서는 약 10억 개의 잡음이 섞여 있는 image alt-text 데이터셋을 Conceptual Captions 데이터셋에서 사용되는 비용이 비싼 filtering 또는 후처리 작업을 사용하지 않고 데이터셋을 구성하였다. 그리고 간단한 dual-encoder architecture는 contrastive loss를 활용해서 visual & language representation을 정렬하였다. 논문에서는 잡음으로부터도 대규모의 corpus를 만들 수 있고 간단한 학습 스키마로도 SoTA를 달성할 수 있음을 보여줬다.
Table of Contents
1. Introduction
2. A Large-scale Noisy Image-Text Dataset
3. Pre-training & Task Transfer
3-1. Pre-training on Noisy Image-Text Pairs
3-2. Transferring to Image-Text Matching & Retrieval
3-3. Transferring to Visual Classification
4. Experiments & Results
4-1. Image-Text Matching & Retrieval
4-2. Zero-shot Visual Classification
4-3. Visual Classification w/ Image Encoder Only
5. Ablation Study
5-1. Model Architectures
5-2. Pre-training Datasets
6. Conclusion
1. Introduction
기존의 연구들에서는 visual과 vision-language representation 학습을 별개의 서로 다른 학습 데이터를 사용하여 학습하였다. 특히 vision domain에서는 대규모 supervised 데이터에서의 pre-training은 성능 향상에 도움을 주었다. 하지만, 이러한 pre-training 데이터셋은 구성하는데 어려움이 있다.
pre-training도 vision-language modeling에서 당연하게 사용되기 시작됐다. 하지만 vision-language 데이터는 vision & NLP 도메인보다 적은 양의 데이터를 가진다. 따라서 vision-language pre-training은 vision과 NLP pre-training 보다 훨씬 더 적은 데이터를 가지게 된다.
이 논문에서는 이러한 문제를 해결하기 위해 대량의 noisy alt-text 쌍을 사용해서 visual & visual-language representation을 학습하였다. 거대한 noisy dataset을 가지기 위해 Conceptual Captions의 데이터 수집 방법을 따랐지만, 데이터셋을 정리하기 위해 복잡한 필터링과 후처리 작업을 적용하는 대신에 간단한 빈도 기반 필터링을 사용하였다. 결과로 나온 데이터셋은 잡음이 섞여 있지만, Conceptual Captions 데이터셋보다 훨씬 큰 데이터셋을 얻을 수 있었다. 논문에서는 대규모 데이터셋에서 visual & visual-language representation을 pre-train 한 결과 다양한 task에 대해서 매우 강력한 성능을 얻을 수 있었다고 말했다.
논문의 모델을 학습시키기 위해, dual-encoder 구조를 사용해서 공유된 잠재 임베딩 공간에서 visual & language representation을 정렬하는 objective를 활용하였다. 논문에서는 이 모델을 ALIGN: A Large-scale ImaGe and Noisy-text embedding 이라고 명명하였다. 이미지 인코더 & 텍스트 인코더는 일치하는 image-text 쌍의 임베딩을 함께 푸시하고 일치하지 않는 image-text 쌍의 임베딩을 분리하는 contrastive loss를 통해 학습된다. 이 손실 함수는 self-supervised & supervised representation 학습에서 가장 효과적인 손실 함수 중 하나이다. 이미지의 fine-grained 라벨을 쌍을 이루는 텍스트라고 생각하면, image-to-text contrastive loss는 라벨 기반 분류 objective와 유사하다. 차이점은 텍스트 인코더가 '라벨' 가중치를 생성한다는 것이다. 그림 1의 왼쪽 위는 ALIGN에서 사용되는 method에 대해서 요약하고 있다.
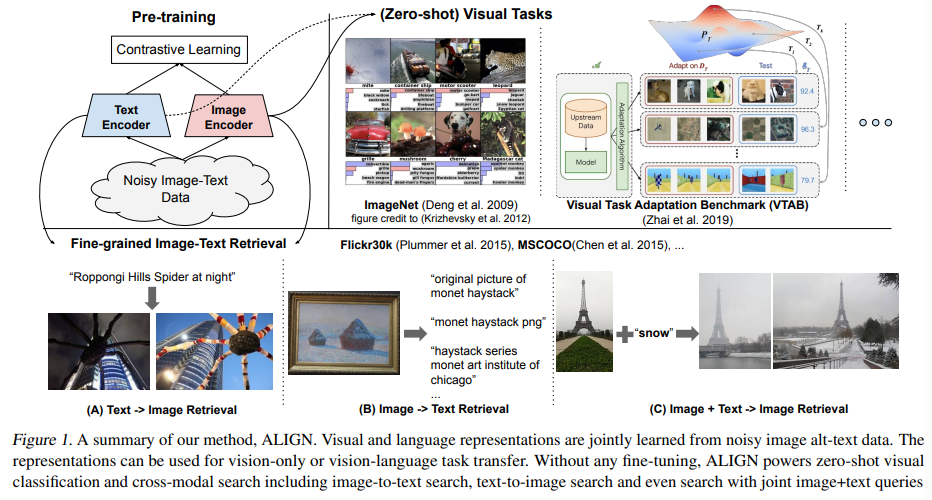
2. A Large-scale Noisy Image-Text Dataset
논문의 목적은 visual & vision-language representation 학습의 규모를 늘리는 것이다. 이 목적을 위해 논문에서는 기존의 데이터셋보다 훨씬 큰 데이터셋에 의지하였다. 이를 위해 Conceptual Captions 데이터셋의 형성 방식을 따라서 raw English alt-text 데이터를 얻었다. Conceptual Captions 데이터셋은 무거운 필터링과 후처리를 통해 정리되지만, 여기에서는 scaling의 목표를 위해 quality와 scale을 맞교환하였다. 그 대신에 최소화된 빈도 기반의 필터링만을 적용하였다. 그 결과로 나온 데이터셋은 매우 크지만 잡음이 섞여 있다. 그림 2는 데이터셋으로부터 몇 개의 샘플 image-text 쌍을 보여주고 있다.

Image-based filtering. 이미지를 기반으로 해서는 다음의 이미지들만을 남겨두었다.
- 짧은 차원의 크기가 200 pixel 이상인 이미지만 유지
- 종횡비(aspect ratio)가 3 이상인 이미지만 유지
- test image에서 복제된 데이터는 제거
Text-based filtering. 텍스트를 기반으로 해서는 다음의 텍스트들만을 남겨두었다.
- 10개 이상의 이미지에서 공유된 alt-text는 제외
- 희귀한 토큰 or 너무 짧거나 긴 alt-text는 제외
3. Pre-training & Task Transfer
3-1. Pre-training on Noisy Image-Text Pairs
논문에서는 ALIGN을 dual-encoder 구조를 사용하여 pre-train 하였다. 논문에서는 조합 함수를 위에 사용한 이미지 인코더 & 텍스트 인코더의 쌍으로 구성되어 있다. 이미지 인코더로는 global pooling을 사용한 EfficientNet을 사용하였고, 텍스트 인코더로는 [CLS] 토큰 임베딩을 사용한 BERT를 사용하였다. 그리고 이미지 인코더와의 차원을 맞추기 위해 linear activation을 사용한 fully-connected layer가 BERT encoder의 위에 추가되었다. 이미지 인코더와 텍스트 인코더는 처음부터 학습된다.
이미지 인코더와 텍스트 인코더는 정규화된 softmax 손실을 통해 최적화된다. 학습에서 논문에서는 matched image-text 쌍을 positive로, 다른 랜덤 image-text 쌍은 negative 배치로 형성하였다.
논문에서는 최종 loss로 image-to-text 분류 loss와
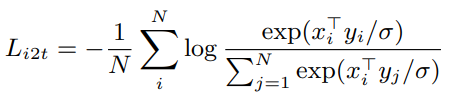
text-to-image 분류 loss의 합을 사용하였다.
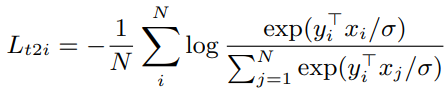
여기서 $x_i$는 $i$번째 이미지 임베딩이고, $y_j$는 $j$번째 텍스트 임베딩이다. $N$은 배치 사이즈, $\sigma$는 logit을 scale 하기 위한 temperature이다. 배치 내에서 negative가 보다 효과적이려면 모든 컴퓨팅 코어의 임베딩을 연결하여 훨씬 더 큰 배치를 형성해야 한다. 이미지 임베딩과 텍스트 임베딩이 모두 L2-normalized 되므로 temperature 변수가 중요하다. 수동적으로 최적의 temperature 값을 찾는 대신에 다른 모든 파라미터와 함께 학습되는 것이 효과적이라는 것을 찾아내었다.
3-2. Transferring to Image-Text Mathcing & Retrieval
논문에서는 ALIGN 모델을 image-to-text & text-to-image retrieval task에서 fine-tuning을 한 것과 안 한 것에 대해 평가하였다. 이를 위해 두 가지 벤치마크 데이터셋을 사용하였다: Flickr30K, MSCOCO. 그리고 추가적으로 Crisscrossed Caption(CxC) 데이터셋에 대해서도 평가하였다.
3-3. Transferring to Visual Classification
논문에서는 ALIGN의 zero-shot 전달을 ImageNet의 다양한 변형에 대해 적용하였다. 그리고 또한 이미지 인코더를 downstream visual classification task로 전달하였다.
4. Experiments & Results
논문에서는 EfficientNet을 이미지 인코더로, BERT를 텍스트 인코더로 사용함으로써 ALIGN model을 처음부터 학습시켰다. 이미지 인코더는 해상도 $289 \times 289$ pixel에서 학습되었는데, 입력 이미지를 $346 \times 346$ 해상도로 사이즈를 변경하고 학습 시에는 random crop을 수행하였고, 테스트 시에는 central crop을 사용하였다. BERT를 위해서 논문에서는 wordpiece 시퀀스를 최대 64개의 토큰까지만 포함하도록 하였다.
4-1. Image-Text Matching & Retrieval
논문에서는 ALIGN을 Flickr30K & MSCOCO 벤치마크에 대해서 zero-shot과 fully fine-tuned 세팅에서 평가하였다. 다음의 표 1은 이전의 모델들과의 비교 결과를 보여준다.
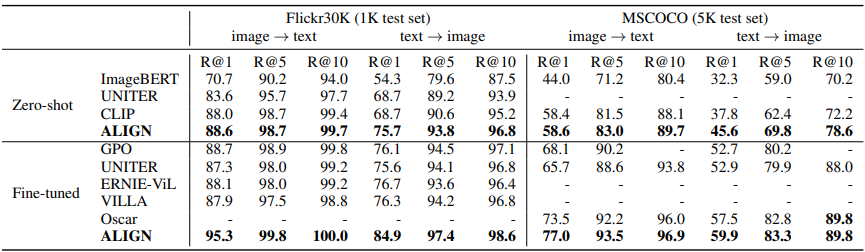
표 1을 살펴보면 ALIGN이 FLickr30K & MSCOCO 벤치마크에서 SoTA를 달성하였음을 알 수 있다.
- zero-shot: 이전의 SoTA에 비해 7% 더 향상된 성능을 보여줌
- fine-tune: 더욱 복잡한 cross-modal attention layer를 활용해 기존의 method보다 큰 마진을 두고 더 뛰어난 성능 향상을 보여줬음.
다음의 표 2에서는 CrissCrossed Captions 데이터셋에서 ALIGN의 성능을 기록하였다. image-to-text & text-to-image에서 기존의 SoTA보다 큰 마진을 두고 성능 향상을 보여줬다. 하지만, intra-modal task에서는 별 효과를 보지 못했다. 예를 들어 text-to-text & image-to-image task에서의 성능 향상은 image-to-text & text-to-image에 비해서 그리 크지 않다는 것을 보여준다.

4-2. Zero-shot Visual Classification
논문에서는 클래스 네임을 텍스트 인코더에 바로 넣으면, ALIGN은 image-text retrieval을 통해 이미지를 후보자 클래스로 분류할 수 있다. 표 3은 ImageNet과 그 변형에 대해서 ALIGN과 CLIP을 비교하였다. ALIGN은 CLIP과 유사하게 서로 다른 이미지 분포를 사용하여 분류 task에서 좋은 robustness를 보여주고 있다.

4-3. Visual Classification w/ Image Encoder Only
ImageNet 벤치마크에서 학습된 visual feature를 동결시키고 오직 classification head만 학습시켰다. 그다음에 모든 레이어를 fine-tune 하였다. 논문에서는 random cropping과 horizontal flip을 포함한 일반적인 data augmentation을 사용하였다. 다음의 표 4는 ImageNet 벤치마크에서 ALIGN과 이전의 method들 간에 비교를 하고 있다. 결과를 살펴보면 frozen feature에서는 ALIGN이 CLIP과 다른 SoTA 결과들보다 살짝 능가하는 성능을 보여주는 것을 알 수 있다. fine-tuning 후에는 ALIGN이 BiT와 ViT 보다 더 높은 정확도를 보이는 것을 알 수 있다.
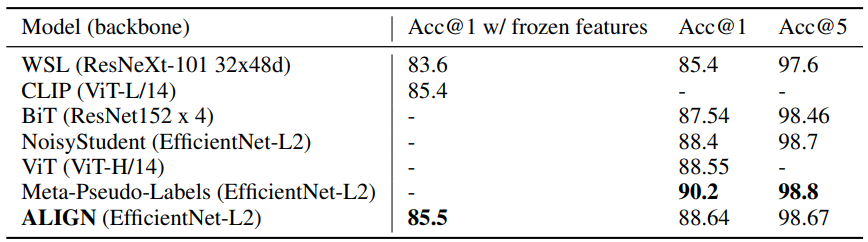
표 5는VTAB에서 3개의 fine-tuning 실행으로부터 평균 정확도와 표준 편차를 기록하고 있다. 그리고 결과를 보면 ALIGN이 BiT-L과 비슷한 하이퍼 파라미터 선택이 적용되었음에도 이를 능가하는 성능을 보여주고 있는 것을 알 수 있다.

5. Ablation Study
ablation study에서는 모델의 성능을 대부분 MSCOCO zero-shot retrieval과 ImageNet KNN task에서 비교하였다.
5-1. Model Architectures
논문에서는 처음에 ALIGN의 성능을 서로 다른 image & text backbone을 사용해서 연구하였다. EfficientNet은 B1부터 L2까지 학습시켰고, BERT는 BERT-Mini부터 BERT-Large까지 학습시켰다.
그림 3은 서로 다른 image & text backbone 조합의 결과를 보여주고 있다. 모델 퀄리티는 더욱 거대한 backbone을 사용함에 따라 향상되는 것을 알 수 있었다. 예상대로 이미지 인코더의 능력을 늘리는 것은 vision task를 위해 더욱 중요하다. image-text retrieval task에서는 image & text encoder의 능력은 동등하게 중요하다.

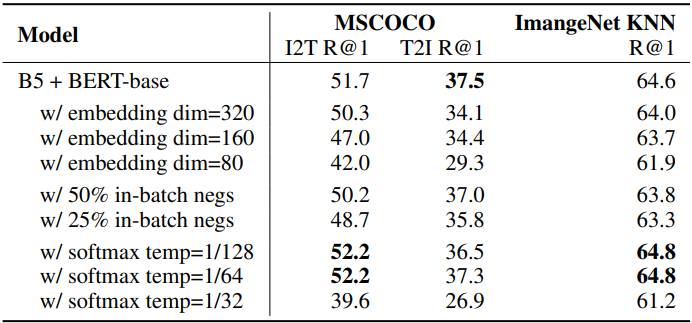
그다음에 embedding 차원, 배치에서 랜덤 negative의 수, softmax temperature를 포함한 핵심 architecture 하이퍼 파라미터에 대해 연구하였다. 표 6은 모델의 변형들은 다음의 세팅에서 학습된 baseline model을 비교하였다: EfficientNet-B5 image encoder, BERT-Base text encoder, 640의 임베딩 차원, 배치 내에서 모두 negative, 학습 가능한 softmax temperature.
표 6의 2열~4열은 높은 임베딩 차원을 사용하여 모델의 성능이 향상했음을 보여주고 있다. 그래서 논문에서는 더욱 거대한 EfficientNet baskbone을 사용하여 차원 scaling을 가능케 하였다. 5열~6열에서는 배치 내에서 더 적은 negative가 softmax loss에서 다운그레이드된 성능을 보여줬다. temperature 파라미터를 학습한 baseline 모델과 비교해서, 손수 선택된 고정된 temperature는 살짝 더 나은 성능을 보여줬다. 하지만, 논문에서는 유망한 성능을 보여주고 학습을 쉽게 만들어주는 학습 가능한 temperature을 선택하였다. 또한 처음 100k 단계에서 temperature가 일반적으로 수렴된 값의 약 1.2배로 빠르게 감소한 다음 학습이 끝날 때까지 천천히 수렴된다는 것을 알 수 있었다.
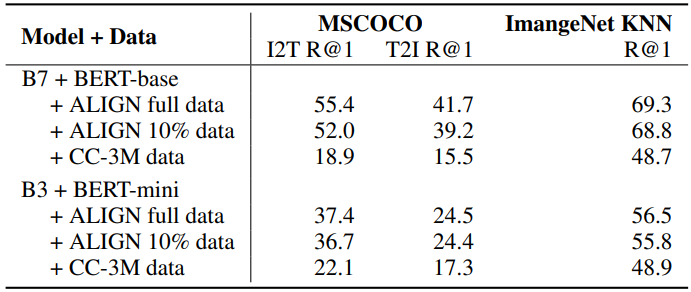
5-2. Pre-training Datasets
서로 다른 데이터셋에서 다양한 사이즈에 대해서 학습될 때, 모델이 어떻게 수행되는지를 이해하는 것 또한 중요하다. 이 목표를 위해 논문에서는 2개의 모델을 학습시켰다: 3개의 서로 다른 데이터셋(full ALIGN 학습 데이터, ALIGN 학습 데이터에서 랜덤 하게 10% 정도 샘플링 됨, Conceptual Captions)에서 EfficientNet-B7 + BERT-base & EfficientNet-B3 + BERT-mini. 표 7에서 보이는 것처럼 모델의 규모를 늘리고 더 나은 성능을 얻기 위해서는 대규모의 training set가 필수적이다. 예를 들어 ALIGN 데이터에서 학습된 모델은 CC-3M 데이터에서 학습한 모델보다 분명하게 더 나은 성능을 보여준다. CC-3M은 규모가 더 작은 데이터셋이다.
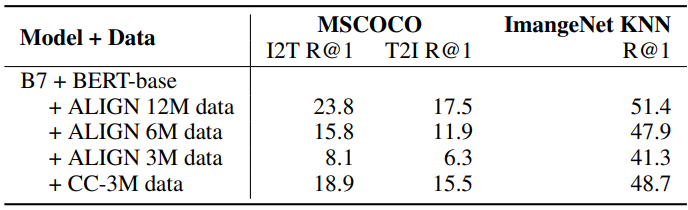
데이터 사이즈 조정이 어떻게 증가된 노이즈를 극복하는지 더 잘 알기 위해, 논문에서는 추가적으로 랜덤하게 샘플링된 3M, 6M, 12M ALIGN 학습 데이터와 정리된 CC-3M 데이터를 B7+BERT-base model에서 비교하였다. 표 8은 CC 데이터와 똑같은 사이즈(3M) 일 때는 ALIGN 데이터가 더 안 좋은 성능을 보여주지만, 6M과 12M에서 학습된 ALIGN data는 이 간격을 빠르게 따라붙었다. 잡음이 있음에도 불구하고 ALIGN 데이터는 Conceptual Captions를 4배 더 작은 사이즈로 능가하는 성능을 보여줬다.
6. Conclusion
논문에서는 visual & vision-language representation 학습의 규모를 늘리기 위해 대규모의 noisy image-text 데이터를 활용하는 간단한 method를 제안하였다. 논문의 method는 데이터 큐레이션과 라벨링에 대한 무거운 작업을 피하고, 최소한의 빈도 기반의 정리를 필요로 하였다. 이 데이터셋에서 간단한 dual-encoder model을 contrastive loss를 사용해서 학습시켰다. 그 결과로 나온 모델이 ALIGN이다. 이 모델은 cross-modal retrieval이 가능하고 SoTA VSE와 cross-attention vision-language 모델을 상당히 능가하는 성능을 보여줬다. visual-only downstream task에서 ALIGN은 대규모의 labeled data를 사용하여 학습된 SoTA 모델에 준하거나 능가하는 성능을 보여줬다.
출처
https://arxiv.org/abs/2102.05918
Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
Pre-trained representations are becoming crucial for many NLP and perception tasks. While representation learning in NLP has transitioned to training on raw text without human annotations, visual and vision-language representations still rely heavily on cu
arxiv.org