
The overview of this paper
여러 vision-and-language task에서 좋은 성능을 내고 있는 VLP는 region supervision(object detection)과 convolutional architecture(ResNet)에 상당히 의존하여 이미지에서 feature를 추출한다. 이러한 점이 효율성/속도와 표현력 측면에서 문제라는 것을 발견하였다.
- 효율성/속도: 입력 feature 추출이 multi-modal 상호작용보다 더 많은 계산량을 필요로 함.
- 표현력: 시각적 임베더의 표현력과 미리 정의된 시각적 vocabulary에 대한 상한이 있기 때문.
이 논문에서는 작은 규모의 VLP model인 Vision-and-Language Transformer(ViLT)를 소개하였다. 이 모델에서 입력은 하나의 덩어리로 들어오는데 텍스트 입력을 처리할 때 convolution을 사용하지 않는 것처럼 visual input을 간단하게 만들어졌다. 그 결과 ViLT는 다른 VLP model들보다 10배 더 빠른 속도를 보여주고 downstream task에서 더 낫고 유망한 성능을 보여줬다.
Table of Contents
1. Introduction
2. Background
2-1. Taxonomy of Vision-and-Language Models
3. Vision-and-Language Transformer
3-1. Model Overview
3-2. Pre-training Objectives
3-3. Whole Word Masking
3-4. Image Augmentation
4. Experiments
4-1. Classification Tasks
4-2. Retrieval Tasks
4-3. Ablation Study
5. Conclusion
1. Introduction
지금까지 VLP model들은 vision-and-language task에서 유망한 결과들을 보여주고 있었다. VLP model에 입력으로 들어가기 위해서, 이미지 픽셀은 language token과 함께 embedding 되었어야 한다. 이러한 visual embedding 단계를 위해서는 CNN이 필수적이었다.
지금까지도 대부분의 VLP 연구들은 성능 향상을 위해 visual embedder의 힘을 증가시켰다. 무거운 visual embedder를 사용했을 때의 단점은 학술 실험에서 잘 생각되지 않았는데, 왜냐하면 학습 시간에 region feature는 저장되서 feature 추출의 부담을 줄여준다. 하지만, query가 wild 환경에서 느린 추출 프로세스를 가진다는 명확한 real-world 응용에 한계가 있다.
이를 위하여, 논문에서는 attention을 visual input의 빠른 임베딩과 가벼운 무게로 전환하였다. 최근의 연구들은 transformer에 픽셀이 들어가기 전에 patch의 간단한 linear projection을 사용하는 것이 효과적이라는 것을 보여줬다. 따라서 논문에서는 기존에 visual feature를 처리할 때 사용한 CNN 대신에 text feature을 사용할 때처럼 간단한 linear projection을 사용하는 것으로도 충분한 성능을 낼 수 있다고 생각하여 대체하였다.
이 논문에서는 하나의 통합된 방식에서 두 개의 modality를 다루는 VIsion-and-Language Transformer(ViLT)를 소개하였다. 이 모델이 기존의 VLP model과 다른 점은 pixel-level input의 embedding이 CNN을 사용하지 않았다는 점이다. 단지 visual input에 대한 deep embedder를 제거했을 뿐인데 모델의 크기와 러닝 타임이 상당히 줄었다. 다음의 그림 1은 ViLT의 파라미터 효율성을 보여준다.
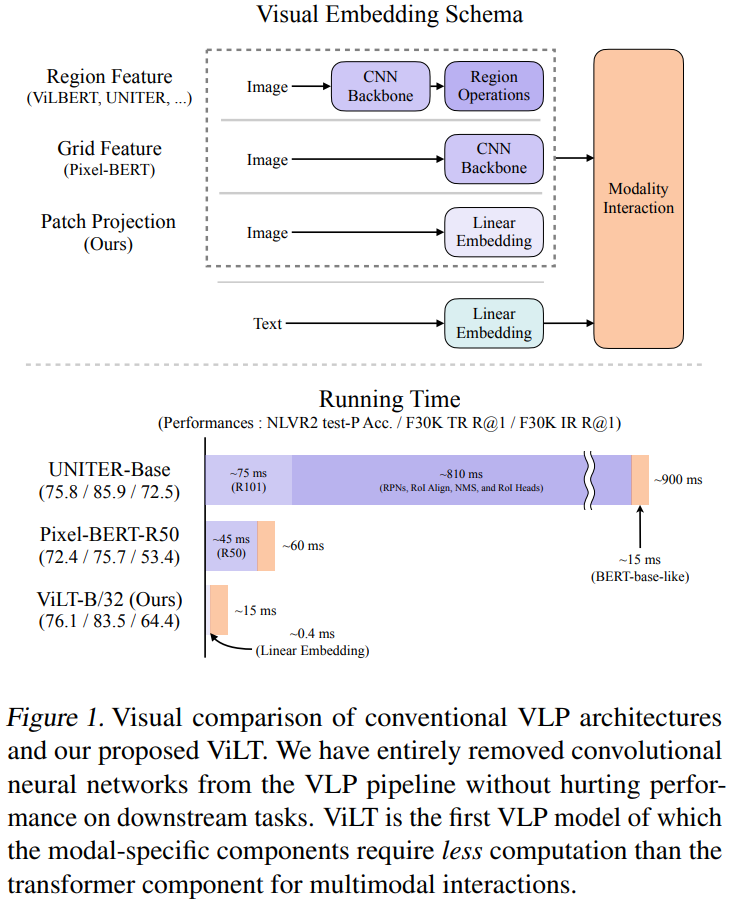
논문의 key contribution은 다음과 같다.
- 간단한 architecutre를 제안함. 별도의 deep embedder를 사용하기 보다는 Transformer에게 visual feature를 추출 & 처리하게 함. 이는 현저히 적은 런타임과 효율적인 파라미터들을 보여줬음.
- region feature or deep conv visual 임베더를 사용하지 않고 유망한 vision-and-language task 결과를 얻음.
- word masking & image augmentation은 downstream 성능을 향상시킴.
2. Background
2-1. Taxonomy of Vision-and-Language Models
논문에서는 vision-and-language model의 분류를 다음의 두 관점에서 기반해서 분류했다. 이렇게 나온 4개의 분류는 그림 2에 나타나 있다.
- 두 개의 modality가 파라미터와 계산량 측면에서 어느 정도의 표현을 가지는가
- 두 개의 modality가 deep network에서 상호작용을 하는가
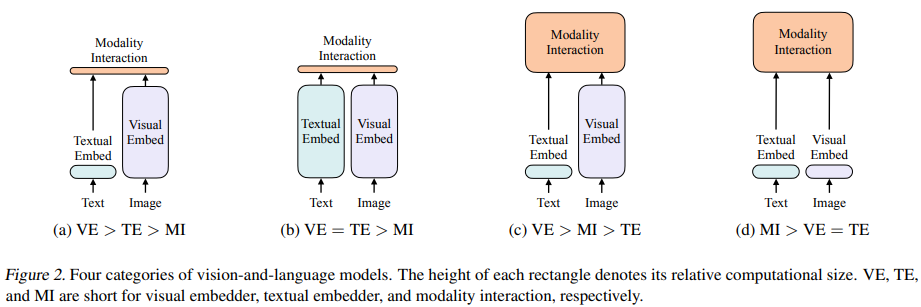
이 논문에서 제안된 ViLT는 위 그림 2에서 d 유형에 속하는 모델이다. 여기서 raw pixel의 임베딩 레이어는 얕고 text token처럼 계산적으로 가볍다. 이 architecture는 modality 상호작용을 모델링하는데 대부분의 계산에 집중하였다.
3. Vision-and-Language Transformer
3-1. Model Overview
ViLT는 VLP 모델에 비해 간결한 architecture이다. 최소의 visual embedding 파이프라인과 single-stream 방식을 사용하였다.
논문에서는 BERT 대신에 pre-trained ViT로부터 상호작용 transformer 가중치를 초기화한다는 환경에서 벗어났다. 이러한 초기화는 상호 작용 레이어의 기능을 활용하여 visual feature을 처리하는 동시에 별도의 심층 visual embedder가 부족하다.
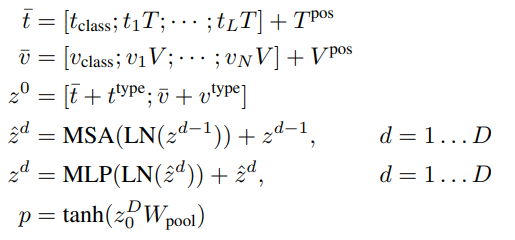
ViT는 multiheaded self-attention(MSA)와 MLP layer를 포함하는 적재된 블록으로 구성되어 있다. ViT에서 layer normalization(LN)의 위치는 BERT와 다른 유일한 점이다: BERT(post-norm, MSA와 MLP 후에 옴), ViT(pre-norm, MSA와 MLP 전에 옴). 입력 텍스트 $t \in \mathbb{R}^{L \times |V|}$은 word embedding 행렬 $T \in \mathbb{R}^{|V| \times H}$와 position embedding $T^{pos} \in \mathbb{R}^{(L+1) \times H}$와 함께 $\bar{t} \in \mathbb{R}^{L \times H}$으로 임베딩된다.
입력 이미지 $I \in \mathbb{R}^{C \times H \times W}$는 패치로 잘라지고 $v \in \mathbb{R}^{N \times (P^{2} \cdot C)}$로 납작해지고, 여기서 $(P, P)$는 패치의 해상도이고 $N = HW \setminus P^{2}$. linear projection $V \in \mathbb{R}^{(P^{2} \cdot C) \times H}$와 position embedding $V^{pos} \in \mathbb{R}^{(N+1) \times H}$이고, $v$는 $\bar{v} \in \mathbb{R}^{N \times H}$으로 임베딩된다.
텍스트 임베딩과 이미지 임베딩은 해당하는 modal-type 임베딩 벡터 $t^{type}, v^{type} \in \mathbb{R}^{H}$과 합해진 다음에, 결합된 시퀀스 $z^{0}$으로 연결된다. contextualized vector $z$는 최종 contextualized 시퀀스 $z^{D}$ 직전까지 깊이 $D$의 transformer layer을 통해 반복적으로 업데이트 된다. $p$는 전체 multi-modal 입력의 pooled representation이고, linear projection $W_{poop} \in \mathbb{R}^{H \times H}$와 하이퍼볼릭 탄젠트를 시퀀스 $z^{D}$의 첫 번째 인덱스에 적용함으로써 얻어지게 된다.
모든 실험에서, ImageNet에서 pre-train 된 ViT-B/32로부터 가중치가 사용되고, 따라서 이름을 ViLT-B/32라고 지었다. hidden size $H$는 768이고, layer 깊이 $D$는 12, 패치 사이즈 $P$는 32, MLP 사이즈는 3,072, attention head의 수의 12이다.
3-2. Pre-training Objectives
논문에서는 ViLT를 보통 VLP model을 학습시킬 때 일반적으로 사용하는 두 개의 objective를 사용하여 학습시켰다: image text matching(ITM) & masked language modeling(MLM).
Image Text Matching. 0.5의 확률로 정렬된 이미지를 다른 이미지로 대체한다. single layer ITM head는 풀링된 출력 feature $p$를 이진 클래스에 대한 logit으로 투영하고 negative log-liklihood를 ITM loss로 계산한다.
추가적으로 논문에서 word region alignment 목표에 영감을 받아서, 두 개의 서브셋: $z^{D}|_{t}$(textual subset) & $z^{D}|_{v}$(visual subset) 간의 정렬 점수를 최적의 전송을 위한 IPOT를 사용하여 계산하는 word patch alignment(WPA)를 제안하였다.
Masked Language Modeling. 이 목표는 contextualized vector $z_{masked}^{D}|_{t}$로부터 masked text token $t_{masked}$의 실제 라벨을 예측하는 목표이다. BERT의 마스킹 전략을 사용해서 확률 0.15로 $t$를 랜덤하게 마스킹하였다.
논문에서는 BERT의 MLM 목표처럼 입력으로 $z_{masked}^{D}|_{t}$가 들어오고 vocabulary애 대한 logit을 출력하는 two-layer MLP MLM head를 사용하였다. MLM loss는 masked token을 위한 negative log-liklihood loss처럼 계산되었다.
3-3. Whole Word Masking
whole word masking은 전체 단어를 구성하는 연속되는 subword들을 모두 mask하는 masking technique이다. 이 technique은 기존 & Chinese BERT을 적용할 때 downstream task에서 효과적인 결과를 보여줬다. 논문에서는 다른 modality로부터 정보의 사용을 full로 하기 위해서는 VLP를 위한 whole word masking을 사용하는 것이 중요하다고 가정하였다. 그래서 실제로 WordPiece로 나눠진 모든 토큰을 masking 하였다. 그렇지 않으면 이미지로부터 정보를 사용하지 않고, 인접 단어로만 예측을 진행하기 때문이다.
3-4. Image Augmentation
image augmentation은 vision model의 일반화 능력을 향상시킨다. 하지만, image augmentation의 능력은 VLP model에서 아직 탐구되지 않았다. visual feature 저장은 region feature 기반 VLP 모델이 image augmentation을 사용하지 못하도록 제한했기 때문이다.
이를 위해 논문에서는 fine-tuning 중에 RandAugment를 적용하였다. 왠만한 policy를 모두 사용하였지만, 두 가지만은 제외하였다: color inversion → 텍스트는 색깔 정보를 가지고 있기도 하기 때문, cutout → 이미지의 조그마한 부분을 제거하지만, 이 부분이 중요한 object일 수도 있기 때문.
4. Experiments
4-1. Classification Tasks
논문에서는 일반적으로 사용되는 두 개의 데이터셋에서 ViLT-B/32를 평가하였다: VQAv2 & NLVR2. 논문에서는 fine-tuned downstream head 처럼 히든 사이즈 1,536의 two-layer MLP를 사용하였다.
Visual Question Answering. ViLT-B/32를 VQAv2 데이터셋에서 평가하였다. 표 1에서 그 결과를 보여주는데, ViLT는 visual embedder가 많은 다른 VLP 모델에 비해 VQA 점수에 미치지는 못하였다.
Natural Language for Visual Reasoning. ViLT-B/32를 NLVR2 데이터셋에서 평가하였다.
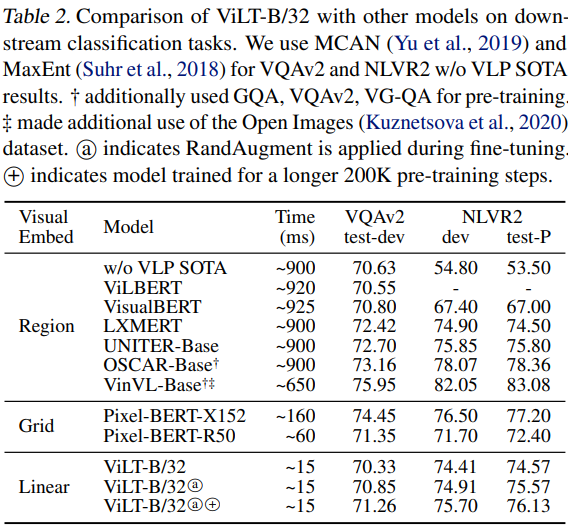
다음의 표 2는 이 두 task에 대한 결과를 보여주고 있다. 결과를 살펴보면 ViLT-B/32는 두 데이터셋에서 유망한 성능을 달성하였고, 좋은 추론 속도를 얻었다.
4-2. Retrieval Tasks
논문에서는 ViLT-B/32를 MSCOCO & F30k의 분할에서 fine-tune 하였다. image-to-text & text-to-image 검색을 위해, 논문에서는 zero-shot과 fine-tuned 성능을 모두 비교하였다. 논문에서는 15개의 텍스트를 negative sample로 샘플링하고 model을 positive 쌍의 score를 극대화하는 cross-entropy loss를 사용해서 tuning 하였다.
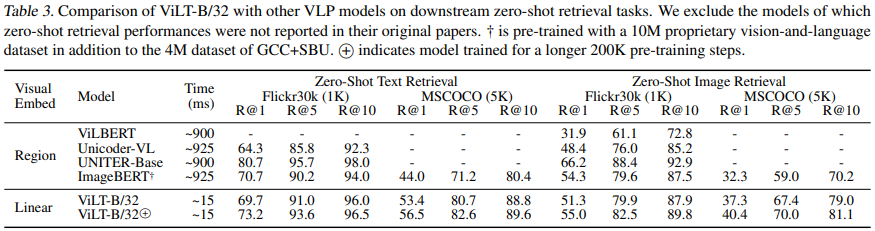
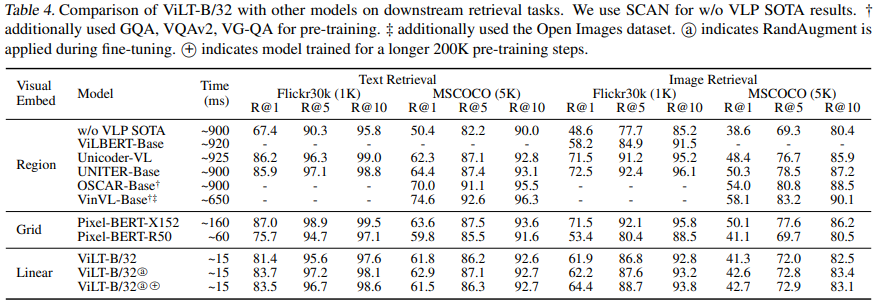
다음의 표 2는 zero-shot 검색 결과를 보여주고 있고, 표 3은 fine-tuned 결과를 보여주고 있다. zero-shot 검색에서 ViLT-B/32는 더욱 큰 데이터셋에서 pre-train 된 ImageBERT 보다 더 나은 성능을 보여줬다. fine-tuned 검색에서 2 번째로 빠른 모델보다 높은 마진으로 큰 recall을 보여줬다.
4-3. Ablation Study
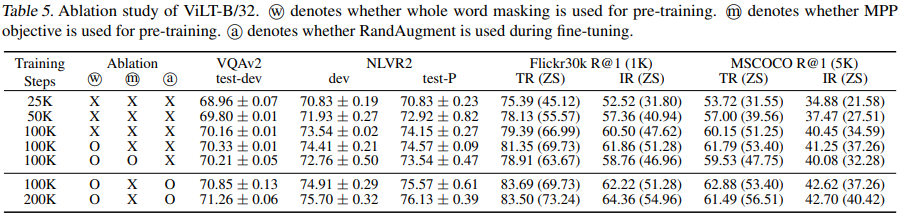
표 4에서 여러 ablation에 대해서 수행하였다: ↑ training steps & whole word masking & image augmentation. 이 ablation의 이점을 파악하였다. 더욱 긴 training step에서 모델을 학습시켰을 때, 성능은 상승되었다(1열~3열). MLM 목표를 위한 전체 단어 마스킹(3열~4열)과 augmentation을 사용한 fine-tuning(6열)을 한 결과 성능이 향상되었다.
5. Conclusion
논문에서는 최소화된 VLP architecture인 Vision-and-Language Transformer(ViLT)를 소개하였다. ViLT는 visual embedding을 위한 CNN을 사용하는 다른 모델들에 비해 유망한 성능을 보여줬다. 그리고 ViLT의 요소들의 중요성에 대해 알아보았다.
Scalability. 적당양의 데이터가 주어지면 pre-trained transformer의 성능은 잘 scale 된다.
Masked Modeling for Visual Inputs. MRM의 성공은 visual modality를 위한 masked modeling objective가 transformer의 마지막 레이어까지 정보를 보존함으로써 도와주었다.
Augmentation Strategies. RandAugment를 사용한 결과, 다른 간단한 augmentation 전략을 사용한 것과 비교해서 downstream 성능을 gain할 수 있었다.
출처
https://arxiv.org/abs/2102.03334
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
Vision-and-Language Pre-training (VLP) has improved performance on various joint vision-and-language downstream tasks. Current approaches to VLP heavily rely on image feature extraction processes, most of which involve region supervision (e.g., object dete
arxiv.org
'Paper Reading 📜 > multimodal models' 카테고리의 다른 글
The overview of this paper
여러 vision-and-language task에서 좋은 성능을 내고 있는 VLP는 region supervision(object detection)과 convolutional architecture(ResNet)에 상당히 의존하여 이미지에서 feature를 추출한다. 이러한 점이 효율성/속도와 표현력 측면에서 문제라는 것을 발견하였다.
- 효율성/속도: 입력 feature 추출이 multi-modal 상호작용보다 더 많은 계산량을 필요로 함.
- 표현력: 시각적 임베더의 표현력과 미리 정의된 시각적 vocabulary에 대한 상한이 있기 때문.
이 논문에서는 작은 규모의 VLP model인 Vision-and-Language Transformer(ViLT)를 소개하였다. 이 모델에서 입력은 하나의 덩어리로 들어오는데 텍스트 입력을 처리할 때 convolution을 사용하지 않는 것처럼 visual input을 간단하게 만들어졌다. 그 결과 ViLT는 다른 VLP model들보다 10배 더 빠른 속도를 보여주고 downstream task에서 더 낫고 유망한 성능을 보여줬다.
Table of Contents
1. Introduction
2. Background
2-1. Taxonomy of Vision-and-Language Models
3. Vision-and-Language Transformer
3-1. Model Overview
3-2. Pre-training Objectives
3-3. Whole Word Masking
3-4. Image Augmentation
4. Experiments
4-1. Classification Tasks
4-2. Retrieval Tasks
4-3. Ablation Study
5. Conclusion
1. Introduction
지금까지 VLP model들은 vision-and-language task에서 유망한 결과들을 보여주고 있었다. VLP model에 입력으로 들어가기 위해서, 이미지 픽셀은 language token과 함께 embedding 되었어야 한다. 이러한 visual embedding 단계를 위해서는 CNN이 필수적이었다.
지금까지도 대부분의 VLP 연구들은 성능 향상을 위해 visual embedder의 힘을 증가시켰다. 무거운 visual embedder를 사용했을 때의 단점은 학술 실험에서 잘 생각되지 않았는데, 왜냐하면 학습 시간에 region feature는 저장되서 feature 추출의 부담을 줄여준다. 하지만, query가 wild 환경에서 느린 추출 프로세스를 가진다는 명확한 real-world 응용에 한계가 있다.
이를 위하여, 논문에서는 attention을 visual input의 빠른 임베딩과 가벼운 무게로 전환하였다. 최근의 연구들은 transformer에 픽셀이 들어가기 전에 patch의 간단한 linear projection을 사용하는 것이 효과적이라는 것을 보여줬다. 따라서 논문에서는 기존에 visual feature를 처리할 때 사용한 CNN 대신에 text feature을 사용할 때처럼 간단한 linear projection을 사용하는 것으로도 충분한 성능을 낼 수 있다고 생각하여 대체하였다.
이 논문에서는 하나의 통합된 방식에서 두 개의 modality를 다루는 VIsion-and-Language Transformer(ViLT)를 소개하였다. 이 모델이 기존의 VLP model과 다른 점은 pixel-level input의 embedding이 CNN을 사용하지 않았다는 점이다. 단지 visual input에 대한 deep embedder를 제거했을 뿐인데 모델의 크기와 러닝 타임이 상당히 줄었다. 다음의 그림 1은 ViLT의 파라미터 효율성을 보여준다.
논문의 key contribution은 다음과 같다.
- 간단한 architecutre를 제안함. 별도의 deep embedder를 사용하기 보다는 Transformer에게 visual feature를 추출 & 처리하게 함. 이는 현저히 적은 런타임과 효율적인 파라미터들을 보여줬음.
- region feature or deep conv visual 임베더를 사용하지 않고 유망한 vision-and-language task 결과를 얻음.
- word masking & image augmentation은 downstream 성능을 향상시킴.
2. Background
2-1. Taxonomy of Vision-and-Language Models
논문에서는 vision-and-language model의 분류를 다음의 두 관점에서 기반해서 분류했다. 이렇게 나온 4개의 분류는 그림 2에 나타나 있다.
- 두 개의 modality가 파라미터와 계산량 측면에서 어느 정도의 표현을 가지는가
- 두 개의 modality가 deep network에서 상호작용을 하는가
이 논문에서 제안된 ViLT는 위 그림 2에서 d 유형에 속하는 모델이다. 여기서 raw pixel의 임베딩 레이어는 얕고 text token처럼 계산적으로 가볍다. 이 architecture는 modality 상호작용을 모델링하는데 대부분의 계산에 집중하였다.
3. Vision-and-Language Transformer
3-1. Model Overview
ViLT는 VLP 모델에 비해 간결한 architecture이다. 최소의 visual embedding 파이프라인과 single-stream 방식을 사용하였다.
논문에서는 BERT 대신에 pre-trained ViT로부터 상호작용 transformer 가중치를 초기화한다는 환경에서 벗어났다. 이러한 초기화는 상호 작용 레이어의 기능을 활용하여 visual feature을 처리하는 동시에 별도의 심층 visual embedder가 부족하다.
ViT는 multiheaded self-attention(MSA)와 MLP layer를 포함하는 적재된 블록으로 구성되어 있다. ViT에서 layer normalization(LN)의 위치는 BERT와 다른 유일한 점이다: BERT(post-norm, MSA와 MLP 후에 옴), ViT(pre-norm, MSA와 MLP 전에 옴). 입력 텍스트 $t \in \mathbb{R}^{L \times |V|}$은 word embedding 행렬 $T \in \mathbb{R}^{|V| \times H}$와 position embedding $T^{pos} \in \mathbb{R}^{(L+1) \times H}$와 함께 $\bar{t} \in \mathbb{R}^{L \times H}$으로 임베딩된다.
입력 이미지 $I \in \mathbb{R}^{C \times H \times W}$는 패치로 잘라지고 $v \in \mathbb{R}^{N \times (P^{2} \cdot C)}$로 납작해지고, 여기서 $(P, P)$는 패치의 해상도이고 $N = HW \setminus P^{2}$. linear projection $V \in \mathbb{R}^{(P^{2} \cdot C) \times H}$와 position embedding $V^{pos} \in \mathbb{R}^{(N+1) \times H}$이고, $v$는 $\bar{v} \in \mathbb{R}^{N \times H}$으로 임베딩된다.
텍스트 임베딩과 이미지 임베딩은 해당하는 modal-type 임베딩 벡터 $t^{type}, v^{type} \in \mathbb{R}^{H}$과 합해진 다음에, 결합된 시퀀스 $z^{0}$으로 연결된다. contextualized vector $z$는 최종 contextualized 시퀀스 $z^{D}$ 직전까지 깊이 $D$의 transformer layer을 통해 반복적으로 업데이트 된다. $p$는 전체 multi-modal 입력의 pooled representation이고, linear projection $W_{poop} \in \mathbb{R}^{H \times H}$와 하이퍼볼릭 탄젠트를 시퀀스 $z^{D}$의 첫 번째 인덱스에 적용함으로써 얻어지게 된다.
모든 실험에서, ImageNet에서 pre-train 된 ViT-B/32로부터 가중치가 사용되고, 따라서 이름을 ViLT-B/32라고 지었다. hidden size $H$는 768이고, layer 깊이 $D$는 12, 패치 사이즈 $P$는 32, MLP 사이즈는 3,072, attention head의 수의 12이다.
3-2. Pre-training Objectives
논문에서는 ViLT를 보통 VLP model을 학습시킬 때 일반적으로 사용하는 두 개의 objective를 사용하여 학습시켰다: image text matching(ITM) & masked language modeling(MLM).
Image Text Matching. 0.5의 확률로 정렬된 이미지를 다른 이미지로 대체한다. single layer ITM head는 풀링된 출력 feature $p$를 이진 클래스에 대한 logit으로 투영하고 negative log-liklihood를 ITM loss로 계산한다.
추가적으로 논문에서 word region alignment 목표에 영감을 받아서, 두 개의 서브셋: $z^{D}|_{t}$(textual subset) & $z^{D}|_{v}$(visual subset) 간의 정렬 점수를 최적의 전송을 위한 IPOT를 사용하여 계산하는 word patch alignment(WPA)를 제안하였다.
Masked Language Modeling. 이 목표는 contextualized vector $z_{masked}^{D}|_{t}$로부터 masked text token $t_{masked}$의 실제 라벨을 예측하는 목표이다. BERT의 마스킹 전략을 사용해서 확률 0.15로 $t$를 랜덤하게 마스킹하였다.
논문에서는 BERT의 MLM 목표처럼 입력으로 $z_{masked}^{D}|_{t}$가 들어오고 vocabulary애 대한 logit을 출력하는 two-layer MLP MLM head를 사용하였다. MLM loss는 masked token을 위한 negative log-liklihood loss처럼 계산되었다.
3-3. Whole Word Masking
whole word masking은 전체 단어를 구성하는 연속되는 subword들을 모두 mask하는 masking technique이다. 이 technique은 기존 & Chinese BERT을 적용할 때 downstream task에서 효과적인 결과를 보여줬다. 논문에서는 다른 modality로부터 정보의 사용을 full로 하기 위해서는 VLP를 위한 whole word masking을 사용하는 것이 중요하다고 가정하였다. 그래서 실제로 WordPiece로 나눠진 모든 토큰을 masking 하였다. 그렇지 않으면 이미지로부터 정보를 사용하지 않고, 인접 단어로만 예측을 진행하기 때문이다.
3-4. Image Augmentation
image augmentation은 vision model의 일반화 능력을 향상시킨다. 하지만, image augmentation의 능력은 VLP model에서 아직 탐구되지 않았다. visual feature 저장은 region feature 기반 VLP 모델이 image augmentation을 사용하지 못하도록 제한했기 때문이다.
이를 위해 논문에서는 fine-tuning 중에 RandAugment를 적용하였다. 왠만한 policy를 모두 사용하였지만, 두 가지만은 제외하였다: color inversion → 텍스트는 색깔 정보를 가지고 있기도 하기 때문, cutout → 이미지의 조그마한 부분을 제거하지만, 이 부분이 중요한 object일 수도 있기 때문.
4. Experiments
4-1. Classification Tasks
논문에서는 일반적으로 사용되는 두 개의 데이터셋에서 ViLT-B/32를 평가하였다: VQAv2 & NLVR2. 논문에서는 fine-tuned downstream head 처럼 히든 사이즈 1,536의 two-layer MLP를 사용하였다.
Visual Question Answering. ViLT-B/32를 VQAv2 데이터셋에서 평가하였다. 표 1에서 그 결과를 보여주는데, ViLT는 visual embedder가 많은 다른 VLP 모델에 비해 VQA 점수에 미치지는 못하였다.
Natural Language for Visual Reasoning. ViLT-B/32를 NLVR2 데이터셋에서 평가하였다.
다음의 표 2는 이 두 task에 대한 결과를 보여주고 있다. 결과를 살펴보면 ViLT-B/32는 두 데이터셋에서 유망한 성능을 달성하였고, 좋은 추론 속도를 얻었다.
4-2. Retrieval Tasks
논문에서는 ViLT-B/32를 MSCOCO & F30k의 분할에서 fine-tune 하였다. image-to-text & text-to-image 검색을 위해, 논문에서는 zero-shot과 fine-tuned 성능을 모두 비교하였다. 논문에서는 15개의 텍스트를 negative sample로 샘플링하고 model을 positive 쌍의 score를 극대화하는 cross-entropy loss를 사용해서 tuning 하였다.
다음의 표 2는 zero-shot 검색 결과를 보여주고 있고, 표 3은 fine-tuned 결과를 보여주고 있다. zero-shot 검색에서 ViLT-B/32는 더욱 큰 데이터셋에서 pre-train 된 ImageBERT 보다 더 나은 성능을 보여줬다. fine-tuned 검색에서 2 번째로 빠른 모델보다 높은 마진으로 큰 recall을 보여줬다.
4-3. Ablation Study
표 4에서 여러 ablation에 대해서 수행하였다: ↑ training steps & whole word masking & image augmentation. 이 ablation의 이점을 파악하였다. 더욱 긴 training step에서 모델을 학습시켰을 때, 성능은 상승되었다(1열~3열). MLM 목표를 위한 전체 단어 마스킹(3열~4열)과 augmentation을 사용한 fine-tuning(6열)을 한 결과 성능이 향상되었다.
5. Conclusion
논문에서는 최소화된 VLP architecture인 Vision-and-Language Transformer(ViLT)를 소개하였다. ViLT는 visual embedding을 위한 CNN을 사용하는 다른 모델들에 비해 유망한 성능을 보여줬다. 그리고 ViLT의 요소들의 중요성에 대해 알아보았다.
Scalability. 적당양의 데이터가 주어지면 pre-trained transformer의 성능은 잘 scale 된다.
Masked Modeling for Visual Inputs. MRM의 성공은 visual modality를 위한 masked modeling objective가 transformer의 마지막 레이어까지 정보를 보존함으로써 도와주었다.
Augmentation Strategies. RandAugment를 사용한 결과, 다른 간단한 augmentation 전략을 사용한 것과 비교해서 downstream 성능을 gain할 수 있었다.
출처
https://arxiv.org/abs/2102.03334
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
Vision-and-Language Pre-training (VLP) has improved performance on various joint vision-and-language downstream tasks. Current approaches to VLP heavily rely on image feature extraction processes, most of which involve region supervision (e.g., object dete
arxiv.org