
The overview of this paper
대부분의 vision & language representation 학습에는 visual token과 word token을 공동으로 모델링하기 위해 transformer 기반 multi-modal encoder가 사용되고 있다. 왜냐하면 visual 토큰과 word 토큰이 정렬되어 있지 않으면, multi-modal model이 image-text 상호작용을 학습하기 어렵기 때문이다. 이 논문에서는 ALign the image & text representations BEfore Fusing(ALBEF) 하기 위해 더욱 gorunded vision & language 학습을 가능하게 하는 cross-modal attention을 가능하게 해주는 contrastive loss를 소개하였다. 기존의 method들과 논문의 method는 bounding box와 고해상도 이미지가 필요 없다. noisy web data로부터 학습을 향상하기 위해, 논문에서는 momentum model에 의해 생성된 모조의 타깃으로부터 학습하는 self-training method인 momentum distillation을 제안하였다.
Table of Contents
1. Introduction
2. ALBEF Pre-training
3. A Mutual Information Maximization Perspective
4. Downstream V+L Tasks
5. Experiments
6. Conclusion
1. Introduction
기존의 VLP method들은 대부분 region 기반의 image feature을 추출하기 위한 pre-trained object detector에 의존하고, image feature과 word token을 융합하기 위해 multi-modal encoder을 사용하고 있다. 이러한 multi-modal encoder는 이미지와 텍스트 공동의 이해를 요구하는 masked language modeling(MLM)과 image-text matching(ITM) 같은 task에서 학습된다.
이러한 방법은 효과적이긴 하지만, 몇 가지 중요한 한계점을 갖고 있다.
- image feature & word token 임베딩은 서로 다른 공간에 있음. 이것이 이들 간의 상호작용을 어렵게 만듦.
- object detector는 라벨링 & 계산적으로 비용이 비쌈. 왜냐하면 pre-training 시에는 bounding box를 필요로 하고, inference 시에는 고해상도 이미지를 필요로 하기 때문임.
- 기존 image-text 데이터는 웹에서 수집되기 때문에 noise가 섞여 있음. 그리고 기존의 pre-training objective는 noisy text에 overfit 되어서 모델의 일반화 성능을 다운그레이드 시킨다.
논문에서는 이러한 한계점을 해결하기 위해 ALign BEfore Fuse(ALBEF)라는 새로운 VLP method를 제안하였다. ALBEF는 다음의 과정을 거쳐서 작동한다.
- detector-free 이미지 인코더 & 텍스트 인코더를 사용해서 이미지 & 텍스트를 독립적으로 encoding 함.
- cross-modal attention을 통해 multi-modal encoder로 image feature & text feature를 융합시킴.
논문에서는 다음의 세 가지 목적을 수반하는 image-text contrastive(ITC) loss를 소개하였다. 이 ITC loss는 unimodal encoder로부터 representation에 대한 loss이다.
- cross-modal learning을 수행하기 위해 image & text feature를 정렬함.
- 이미지와 텍스트의 semantic meaning을 더 잘 이해하기 위해 unimodal encoder를 향상시킴.
- 이미지와 텍스트를 임베딩하기 위해 저차원 공간을 학습. 이는 contrastive hard negative mining을 통해 더욱 정보적인 샘플을 찾기 위한 image-text matching objective가 가능하게 만들어 줌.
noisy supervision에서의 학습을 향상시키기 위해, 논문에서는 모델이 더욱 큰 uncurated 웹 데이터셋을 활용하게 해주는 간단한 method인 Momentum Distillation(MoD)을 제안하였다. 학습 중에 논문에서는 이 파라미터들에 이동 평균(moving-average)을 취함으로써 모델의 momentum 버전을 유지하고, 모조 타깃을 추가적 supervision으로 생성하기 위해 momentum model을 사용하였다. MoD를 사용하면, 모델은 웹 라벨링과는 다르지만 다른 합리적인 출력을 생성하는 것에 대해 벌을 주지 않았다. 논문에서는 MoD가 pre-training을 향상시킬 뿐만 아니라 정리된 라벨을 사용하여 downstream task에서도 향상된 모습을 보여줬다.
2. ALBEF Pre-training
2-1. Model Architecture
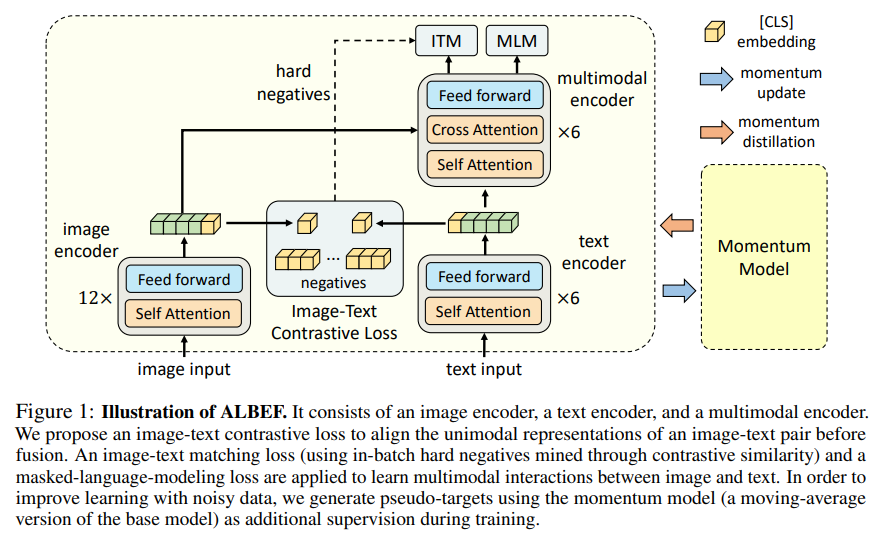
그림 1에서 보이는 것처럼, ALBEF는 image, text, multi-modal encoder를 포함하고 있다. 논문에서는 12-layer visual transformer인 ViT-B/16을 이미지 인코더로 사용하고 ImageNet-1k에서 pre-train 된 가중치를 사용하여 초기화하였다. 입력 이미지 $I$는 임베딩 $\left\{ \textbf{v}_{cls}, \textbf{v}_{1}, ..., \textbf{v}_{N} \right\}$ 의 시퀀스로 인코딩 된다. 여기서 $v_{cls}$는 [CLS] 토큰의 임베딩이다. text encoder는 BERT BASE의 마지막 6개의 레이어를 사용하여 초기화된다. 텍스트 인코더는 입력 텍스트 $T$를 임베딩 $\left\{ \textbf{w}_{cls}, \textbf{w}_{1}, ..., \textbf{w}_{N} \right\}$의 시퀀스로 인코딩 돼서 multi-modal encoder에 들어가게 된다. image feature은 multi-modal encoder의 각 레이어에서 cross attention을 통해 text feature와 함께 융합된다.
2-2. Pre-training Objectives
논문에서는 ALBEF를 3개의 objective를 사용하여 pre-train 하였다: unimodal encoder에서 image-text contrastive(ITC) 학습, multi-modal encoder에서 masked language modeling(MLM) & image-text matching(ITM). 논문에서는 ITM을 온라인 contrastive hard negative mining을 사용하여 향상시켰다. hard negative mining은 분류 문제에서 더욱 어려운 negative 샘플을 모으는 것이다. 이는 모델의 학습 난이도를 더 어렵게 해서 더욱 효과적인 학습을 가능하게 한다.
Image-Text Contrastive Learning은 융합 이전에 더 나은 unimodal representation을 학습할 수 있도록 목표를 잡았다. 이 학습은 병렬 image-text 쌍이 더 높은 유사성 점수를 갖도록 유사도 함수 $s = g_{v}(\textbf{v}_{cls})^{\top}g_{w}(\textbf{w}_{cls})$을 학습시켰다. $g_{v}$와 $g_{w}$는 [CLS] 임베딩을 정규화된 저차원 representation으로 매핑하는 선형 변환이다. momentum encoder로부터 얻어진 정규화된 feature는 $g_{v}^{'}(\textbf{v}_{cls}^{'})$와 $g_{w}^{'}(\textbf{w}_{cls}^{'})$로 표시된다. 논문에서는 $s(I, T) = g_{v}(\textbf{v}_{cls})^{\top}g_{w}^{'}(\textbf{w}_{cls}^{'})$와 $s(T, I) = g_{w}(\textbf{w}_{cls})^{\top}g_{cls}^{'}(\textbf{v}_{cls}^{'})$.
각각의 이미지 & 텍스트에 대해서, 논문에서는 softmax 정규화된 image-to-text & text-to-image 유사도를 다음과 같이 계산하였다:
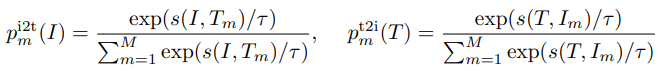
여기서 $\tau$은 학습 가능한 temperature 파라미터이다. $\textbf{y}^{i2t}(I)$와 $\textbf{y}^{t2i}(T)$은 ground-truth one-hot 유사도를 나타낸다. 여기서 negative 쌍은 0의 확률을 가지고 positive 쌍은 1의 확률을 가진다. image-text contrastive loss는 $\textbf{p}$와 $\textbf{y}$ 간의 cross-entropy $H$로 정의하였다.
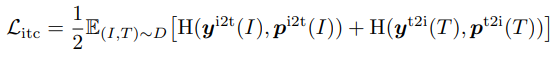
Masked Language Modeling은 masked word를 예측하기 위해 이미지와 텍스트를 모두 활용한다. 논문에서는 입력 토큰을 랜덤 하게 스페셜 토큰 [MASK]로 대체하였다. $\hat{T}$은 masked text를 나타내고, $\textbf{p}^{msk}(I, \hat{T})$은 masekd token에 대한 모델의 예측 확률을 나타낸다. MLM은 cross-entropy loss를 최소화하였다:
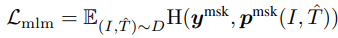
여기서 $\textbf{y}^{msk}$는 one-hot vocabulary 분포인데 여기서 ground-truth 토큰을 1의 확률을 가진다.
Image-Text Matching은 이미지와 텍스트 쌍이 positive(일치함)인지 negative(일치하지 않음)인지 예측한다. multi-modal encoder의 [CLS] 토큰 출력 임베딩을 image-text 쌍의 공동 representation으로 사용하고 fully-connected(FC) 레이어를 추가한 다음 softmax를 추가하여 2 클래스 확률 $p_{itm}$을 예측한다. ITM loss는 다음과 같다.
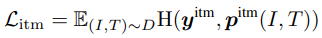
여기서 $\textbf{y}^{itm}$은 ground-truth 라벨을 나타내는 2차원 one-hot 벡터이다.
이 모든 것을 종합하여 만든 ALBEF의 pre-training objective이다.
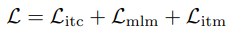
3-3. Momentum Distillation
pre-training에 사용되는 image-text 쌍은 대부분에 웹에서 수집되는데 이들은 noisy 한 경향이 있다. 이 데이터들에서 positive 쌍은 대부분 약하게 연관되어 있다: 텍스트는 이미지와 연관되어 있지 않기도 하거나 이미지는 텍스트에서 설명되지 않은 객체를 포함하고 있기도 한다. ITC 학습에 대해 이미지에 대한 negative 텍스트는 이미지의 내용과 일치하기도 한다. MLM에 대해 기존의 라벨과는 다르지만 이미지에 대해 비슷하게 잘 설명하는 word를 포함하기도 한다. 하지만 ITC와 MLM에 대한 one-hot 라벨은 정확도를 고려하지 않고 모든 negative 예측은 무시해 버린다.
이를 해결하기 위해 논문에서는 momentum model로부터 생성되는 paseudo target으로부터 학습된다. momentum model은 계속적으로 발전하는 선생으로 unimodal과 multi-modal encoder의 exponential-moving-average로 구성되어 있다. 학습 중에는 base model의 예측이 momentum model의 것 중 하나를 예측하도록 학습시킨다. 특히 ITC에 대해서 논문에서는 처음에 momentum model encoder로부터 나온 feature를 $s’(I, T)=g_{v}^{‘}(\textbf{v}_{cls}^{‘})^{\top}g_{w}^{‘}(\textbf{w}_{cls}^{‘})$과 $s’(T, I)=g_{w}^{‘}(\textbf{w}_{cls})^{\top}g_{v}^{‘}(\textbf{v}_{cls}^{‘})$로 사용하여 image-text 유사도를 측정하였다. 그다음에 앞서 첫 번째 수식에서 $s$를 $s’$으로 대체함으로써 soft pseudo target $\textbf{q}^{i2t}$와 $\textbf{q}^{t2i}$를 계산하였다. ITC_MoD loss는 다음과 같다.
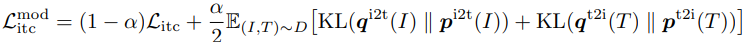
이와 유사하게 MLM에 대해 $\textbf{q}^{msk}(I, \hat{T})$는 masked token에 대한 momentum model의 예측 확률을 나타낸다. 그래서 $MLM_{MoD}$ loss는 다음과 같다.
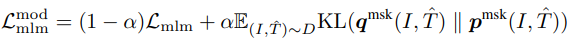
그림 2에서는 pseudo target으로부터 top-5 후보자의 예시를 보여주고 있다. 이것은 이미지에 대해 연관된 word/text를 효과적으로 캡처한다.

논문에서는 또한 downstream task에 MoD를 적용하였다. 각 task에 대한 최종 loss는 model의 예측과 pseudo target 간의 기존 task loss와 KL-divergence의 가중치 된 조합이다. 간단함을 위해, 논문에서는 모든 pre-training & downstream task를 위해 가중치 $\alpha = 0.4$로 설정하였다.
3. A Mutual Information Maximization Persepctive
이 섹션에서는 ALBEF의 대안이 되는 보기를 제공하고, 이것이 image-text 쌍의 서로 다른 '시점' 간의 mutual information(MI)에 대한 lower bound를 최대화시켜 줬다. ITC, MLM, MoD는 보기를 생성하기 위한 서로 다른 방법으로 해석될 수 있다.
논문에서는 두 개의 랜덤 한 변수 $a$와 $b$를 데이터의 서로 다른 두 보기로 정의하였다. self-supervised learning에서, $a$와 $b$는 똑같은 이미지의 두 augmentation이다. vision-language representation learning에서는 semantic meaning을 캡처하는 image-text 쌍의 서로 다른 변수 $a$와 $b$로 고려하였다. 이는 $a$와 $b$ 간의 MI를 최대화시킴으로써 달성될 수 있다. 실제로 논문에서는 다음과 같이 정의되는 InfoNCE loss를 최소화시킴으로써 $MI(a, b)$에 대한 lower bound를 최소화시켰다. InfoNCE loss는 두 데이터 샘플을 비교하여, 샘플 간의 유사도를 측정하는 데에 활용된다.
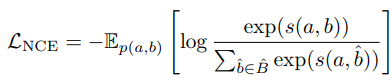
여기서 $s(a, b)$는 scoring function이고, $\hat{B}$는 확률 분포로부터 뽑아진 positive sample $b$와 $|\hat{B}|-1$ negative sample로 구성되어 있다.
논문의 ITC loss는 one-hot 라벨을 사용하여 다음과 같이 작성될 수 있다:
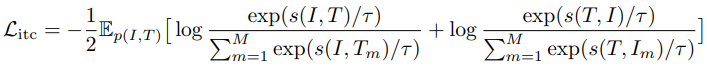
$\mathfrak{L}_{itc}$를 최소화하는 것은 InfoNCE의 대칭 버전을 최대화시키는 것처럼 보일 수 있다. 그래서 ITC는 2개의 modality($I$ & $T$)를 image-text 쌍의 2개의 보기로 고려하고, positive 쌍에 대한 이미지 보기와 텍스트 보기 간의 MI를 최대화하는 unimodal encoder를 학습시킨다.
그리고 MLM을 masked word token과 이것의 masked context 간의 MI를 최대화하는 것으로 해석될 수 있다. 특히 MLM loss를 one-hot 라벨을 사용하여 다음과 같이 재작성할 수 있다:
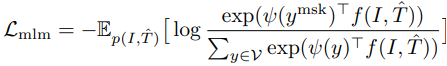
여기서 $\psi (y) : \mathfrak{V} \to \mathbb{R}^{d}$는 word token $y$를 벡터로 매핑하는 multi-modal encoder의 출력 레이어에서의 lookup function이고, $\mathfrak{V}$는 전체 vocabulary 세트이고, $f(I, \hat{T})$는 masked context에 해당하는 multi-modal encoder의 최종 hidden state를 반환하는 함수이다. 그래서 MLM은 image-text 쌍의 두 가지 보기를 다음과 같이 간주한다:
- 랜덤 하게 선택된 word token
- image + 해당 단어가 마스킹된 text
ITC와 MLM은 image-text 쌍으로부터 modality 분리 또는 word masking을 통해 얻은 부분적 정보를 취함으로써 보기를 생성한다. 논문의 momentum distillation은 전체 제안 분포로부터 대안이 되는 보기를 생성하는 것으로 간주될 수 있다. 위의 ITC MoD 수식에서 $KL(\textbf{p}^{i2t}(I), \textbf{q}^{i2t}(I))$을 최소화하는 것은 다음의 objective를 최소화시키는 것과 동일하다.
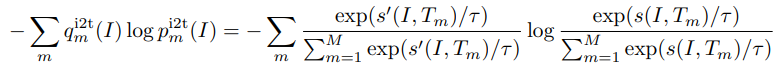
이 objective는 이미지 $I$를 사용하여 유사한 semantic meaning을 공유하는 텍스트에 대한 $MI(I, T_{m})$을 최대화하는데, 왜냐하면 텍스트는 더 큰 $q_{m}^{i2t}(I)$를 가지기 때문이다. 이와 유사하게, $ITC_{MoD}$는 $T$와 유사한 이미지에 대한 $MI(I_{m}, T)$를 최대화시킨다. 논문에서는 masked word $y^{msk}$에 대한 대안이 되는 보기 $y' \in \mathfrak{V}$를 생성하는 $MLM_{MoD}$을 보여주기 위한 똑같은 method를 따랐고, $y'$과 $(I, \hat{T})$ 간의 MI를 최대화하였다. 그래서 momentum distillation은 기존의 보기에 augmentation을 수행하는 것처럼 간주될 수 있다. momentum model은 기존의 image-text 쌍에는 없는 보기의 다양한 세트를 생성할 수 있고, base model이 view-invariant semantic 정보를 캡처하는 representation을 학습할 수 있게 만들었다.
4. Downstream V+L Tasks
논문에서는 pre-trained model을 5개의 downstream V+L task에 적용하였다.
- Image-Text Retrieval
- Visual Entailment
- Visual Question Answering(VQA)
- Natural Language for Visual Reasoning(NLVR2)
- Visual Grounding
5. Experiments
5-1. Evaluation on the Proposed Methods
논문에서는 처음에 제안된 method의 효과를 평가하였다. 표 1은 method의 서로 다른 변형을 사용하여 downstream task의 성능을 보여준다. baseline pre-training task(MLM+ITC)와 비교해서, ITC를 추가하는 것은 모든 task에 대해서 pre-trained model의 성능을 향상시켜준다.
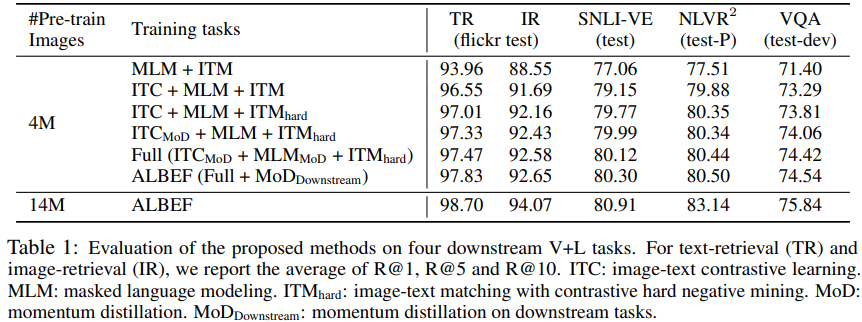
제안된 hard negative mining은 ITM을 더욱 정보적인 학습 샘플을 찾음으로써 향상시킨다. 게다가 momentum distillation을 추가하는 것은 ITC(4행), MLM(5행), 모든 downstream tasks(6행)에 대한 학습을 향상시킨다. 마지막 행에서는 ALBEF가 pre-training 성능을 향상시키기 위해 더욱 noise가 섞인 웹 데이터를 효과적으로 활용한다는 것을 보여주고 있다.
6. Conclusion
이 논문에서는 vision-language representation 학습을 위한 새로운 프레임워크인 ALBEF를 제안하였다. ALBEF는 처음에 nuimodal representation과 text representation을 정렬하고 그다음에 multimodal encoder를 사용하여 이들을 융합한다. 논문에서는 이론적 및 실험적으로 제안된 image-text contrastive learning과 momentum distillation의 효과를 입증하였다. 기존의 method들과 비교했을 때, ALBEF는 여러 downstream V+L tasks에서 더 나은 성능과 더 빠른 추론 속도를 제공하였다.
출처
https://arxiv.org/abs/2107.07651
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
Large-scale vision and language representation learning has shown promising improvements on various vision-language tasks. Most existing methods employ a transformer-based multimodal encoder to jointly model visual tokens (region-based image features) and
arxiv.org
'Paper Reading 📜 > multimodal models' 카테고리의 다른 글
The overview of this paper
대부분의 vision & language representation 학습에는 visual token과 word token을 공동으로 모델링하기 위해 transformer 기반 multi-modal encoder가 사용되고 있다. 왜냐하면 visual 토큰과 word 토큰이 정렬되어 있지 않으면, multi-modal model이 image-text 상호작용을 학습하기 어렵기 때문이다. 이 논문에서는 ALign the image & text representations BEfore Fusing(ALBEF) 하기 위해 더욱 gorunded vision & language 학습을 가능하게 하는 cross-modal attention을 가능하게 해주는 contrastive loss를 소개하였다. 기존의 method들과 논문의 method는 bounding box와 고해상도 이미지가 필요 없다. noisy web data로부터 학습을 향상하기 위해, 논문에서는 momentum model에 의해 생성된 모조의 타깃으로부터 학습하는 self-training method인 momentum distillation을 제안하였다.
Table of Contents
1. Introduction
2. ALBEF Pre-training
3. A Mutual Information Maximization Perspective
4. Downstream V+L Tasks
5. Experiments
6. Conclusion
1. Introduction
기존의 VLP method들은 대부분 region 기반의 image feature을 추출하기 위한 pre-trained object detector에 의존하고, image feature과 word token을 융합하기 위해 multi-modal encoder을 사용하고 있다. 이러한 multi-modal encoder는 이미지와 텍스트 공동의 이해를 요구하는 masked language modeling(MLM)과 image-text matching(ITM) 같은 task에서 학습된다.
이러한 방법은 효과적이긴 하지만, 몇 가지 중요한 한계점을 갖고 있다.
- image feature & word token 임베딩은 서로 다른 공간에 있음. 이것이 이들 간의 상호작용을 어렵게 만듦.
- object detector는 라벨링 & 계산적으로 비용이 비쌈. 왜냐하면 pre-training 시에는 bounding box를 필요로 하고, inference 시에는 고해상도 이미지를 필요로 하기 때문임.
- 기존 image-text 데이터는 웹에서 수집되기 때문에 noise가 섞여 있음. 그리고 기존의 pre-training objective는 noisy text에 overfit 되어서 모델의 일반화 성능을 다운그레이드 시킨다.
논문에서는 이러한 한계점을 해결하기 위해 ALign BEfore Fuse(ALBEF)라는 새로운 VLP method를 제안하였다. ALBEF는 다음의 과정을 거쳐서 작동한다.
- detector-free 이미지 인코더 & 텍스트 인코더를 사용해서 이미지 & 텍스트를 독립적으로 encoding 함.
- cross-modal attention을 통해 multi-modal encoder로 image feature & text feature를 융합시킴.
논문에서는 다음의 세 가지 목적을 수반하는 image-text contrastive(ITC) loss를 소개하였다. 이 ITC loss는 unimodal encoder로부터 representation에 대한 loss이다.
- cross-modal learning을 수행하기 위해 image & text feature를 정렬함.
- 이미지와 텍스트의 semantic meaning을 더 잘 이해하기 위해 unimodal encoder를 향상시킴.
- 이미지와 텍스트를 임베딩하기 위해 저차원 공간을 학습. 이는 contrastive hard negative mining을 통해 더욱 정보적인 샘플을 찾기 위한 image-text matching objective가 가능하게 만들어 줌.
noisy supervision에서의 학습을 향상시키기 위해, 논문에서는 모델이 더욱 큰 uncurated 웹 데이터셋을 활용하게 해주는 간단한 method인 Momentum Distillation(MoD)을 제안하였다. 학습 중에 논문에서는 이 파라미터들에 이동 평균(moving-average)을 취함으로써 모델의 momentum 버전을 유지하고, 모조 타깃을 추가적 supervision으로 생성하기 위해 momentum model을 사용하였다. MoD를 사용하면, 모델은 웹 라벨링과는 다르지만 다른 합리적인 출력을 생성하는 것에 대해 벌을 주지 않았다. 논문에서는 MoD가 pre-training을 향상시킬 뿐만 아니라 정리된 라벨을 사용하여 downstream task에서도 향상된 모습을 보여줬다.
2. ALBEF Pre-training
2-1. Model Architecture
그림 1에서 보이는 것처럼, ALBEF는 image, text, multi-modal encoder를 포함하고 있다. 논문에서는 12-layer visual transformer인 ViT-B/16을 이미지 인코더로 사용하고 ImageNet-1k에서 pre-train 된 가중치를 사용하여 초기화하였다. 입력 이미지 $I$는 임베딩 $\left\{ \textbf{v}_{cls}, \textbf{v}_{1}, ..., \textbf{v}_{N} \right\}$ 의 시퀀스로 인코딩 된다. 여기서 $v_{cls}$는 [CLS] 토큰의 임베딩이다. text encoder는 BERT BASE의 마지막 6개의 레이어를 사용하여 초기화된다. 텍스트 인코더는 입력 텍스트 $T$를 임베딩 $\left\{ \textbf{w}_{cls}, \textbf{w}_{1}, ..., \textbf{w}_{N} \right\}$의 시퀀스로 인코딩 돼서 multi-modal encoder에 들어가게 된다. image feature은 multi-modal encoder의 각 레이어에서 cross attention을 통해 text feature와 함께 융합된다.
2-2. Pre-training Objectives
논문에서는 ALBEF를 3개의 objective를 사용하여 pre-train 하였다: unimodal encoder에서 image-text contrastive(ITC) 학습, multi-modal encoder에서 masked language modeling(MLM) & image-text matching(ITM). 논문에서는 ITM을 온라인 contrastive hard negative mining을 사용하여 향상시켰다. hard negative mining은 분류 문제에서 더욱 어려운 negative 샘플을 모으는 것이다. 이는 모델의 학습 난이도를 더 어렵게 해서 더욱 효과적인 학습을 가능하게 한다.
Image-Text Contrastive Learning은 융합 이전에 더 나은 unimodal representation을 학습할 수 있도록 목표를 잡았다. 이 학습은 병렬 image-text 쌍이 더 높은 유사성 점수를 갖도록 유사도 함수 $s = g_{v}(\textbf{v}_{cls})^{\top}g_{w}(\textbf{w}_{cls})$을 학습시켰다. $g_{v}$와 $g_{w}$는 [CLS] 임베딩을 정규화된 저차원 representation으로 매핑하는 선형 변환이다. momentum encoder로부터 얻어진 정규화된 feature는 $g_{v}^{'}(\textbf{v}_{cls}^{'})$와 $g_{w}^{'}(\textbf{w}_{cls}^{'})$로 표시된다. 논문에서는 $s(I, T) = g_{v}(\textbf{v}_{cls})^{\top}g_{w}^{'}(\textbf{w}_{cls}^{'})$와 $s(T, I) = g_{w}(\textbf{w}_{cls})^{\top}g_{cls}^{'}(\textbf{v}_{cls}^{'})$.
각각의 이미지 & 텍스트에 대해서, 논문에서는 softmax 정규화된 image-to-text & text-to-image 유사도를 다음과 같이 계산하였다:
여기서 $\tau$은 학습 가능한 temperature 파라미터이다. $\textbf{y}^{i2t}(I)$와 $\textbf{y}^{t2i}(T)$은 ground-truth one-hot 유사도를 나타낸다. 여기서 negative 쌍은 0의 확률을 가지고 positive 쌍은 1의 확률을 가진다. image-text contrastive loss는 $\textbf{p}$와 $\textbf{y}$ 간의 cross-entropy $H$로 정의하였다.
Masked Language Modeling은 masked word를 예측하기 위해 이미지와 텍스트를 모두 활용한다. 논문에서는 입력 토큰을 랜덤 하게 스페셜 토큰 [MASK]로 대체하였다. $\hat{T}$은 masked text를 나타내고, $\textbf{p}^{msk}(I, \hat{T})$은 masekd token에 대한 모델의 예측 확률을 나타낸다. MLM은 cross-entropy loss를 최소화하였다:
여기서 $\textbf{y}^{msk}$는 one-hot vocabulary 분포인데 여기서 ground-truth 토큰을 1의 확률을 가진다.
Image-Text Matching은 이미지와 텍스트 쌍이 positive(일치함)인지 negative(일치하지 않음)인지 예측한다. multi-modal encoder의 [CLS] 토큰 출력 임베딩을 image-text 쌍의 공동 representation으로 사용하고 fully-connected(FC) 레이어를 추가한 다음 softmax를 추가하여 2 클래스 확률 $p_{itm}$을 예측한다. ITM loss는 다음과 같다.
여기서 $\textbf{y}^{itm}$은 ground-truth 라벨을 나타내는 2차원 one-hot 벡터이다.
이 모든 것을 종합하여 만든 ALBEF의 pre-training objective이다.
3-3. Momentum Distillation
pre-training에 사용되는 image-text 쌍은 대부분에 웹에서 수집되는데 이들은 noisy 한 경향이 있다. 이 데이터들에서 positive 쌍은 대부분 약하게 연관되어 있다: 텍스트는 이미지와 연관되어 있지 않기도 하거나 이미지는 텍스트에서 설명되지 않은 객체를 포함하고 있기도 한다. ITC 학습에 대해 이미지에 대한 negative 텍스트는 이미지의 내용과 일치하기도 한다. MLM에 대해 기존의 라벨과는 다르지만 이미지에 대해 비슷하게 잘 설명하는 word를 포함하기도 한다. 하지만 ITC와 MLM에 대한 one-hot 라벨은 정확도를 고려하지 않고 모든 negative 예측은 무시해 버린다.
이를 해결하기 위해 논문에서는 momentum model로부터 생성되는 paseudo target으로부터 학습된다. momentum model은 계속적으로 발전하는 선생으로 unimodal과 multi-modal encoder의 exponential-moving-average로 구성되어 있다. 학습 중에는 base model의 예측이 momentum model의 것 중 하나를 예측하도록 학습시킨다. 특히 ITC에 대해서 논문에서는 처음에 momentum model encoder로부터 나온 feature를 $s’(I, T)=g_{v}^{‘}(\textbf{v}_{cls}^{‘})^{\top}g_{w}^{‘}(\textbf{w}_{cls}^{‘})$과 $s’(T, I)=g_{w}^{‘}(\textbf{w}_{cls})^{\top}g_{v}^{‘}(\textbf{v}_{cls}^{‘})$로 사용하여 image-text 유사도를 측정하였다. 그다음에 앞서 첫 번째 수식에서 $s$를 $s’$으로 대체함으로써 soft pseudo target $\textbf{q}^{i2t}$와 $\textbf{q}^{t2i}$를 계산하였다. ITC_MoD loss는 다음과 같다.
이와 유사하게 MLM에 대해 $\textbf{q}^{msk}(I, \hat{T})$는 masked token에 대한 momentum model의 예측 확률을 나타낸다. 그래서 $MLM_{MoD}$ loss는 다음과 같다.
그림 2에서는 pseudo target으로부터 top-5 후보자의 예시를 보여주고 있다. 이것은 이미지에 대해 연관된 word/text를 효과적으로 캡처한다.
논문에서는 또한 downstream task에 MoD를 적용하였다. 각 task에 대한 최종 loss는 model의 예측과 pseudo target 간의 기존 task loss와 KL-divergence의 가중치 된 조합이다. 간단함을 위해, 논문에서는 모든 pre-training & downstream task를 위해 가중치 $\alpha = 0.4$로 설정하였다.
3. A Mutual Information Maximization Persepctive
이 섹션에서는 ALBEF의 대안이 되는 보기를 제공하고, 이것이 image-text 쌍의 서로 다른 '시점' 간의 mutual information(MI)에 대한 lower bound를 최대화시켜 줬다. ITC, MLM, MoD는 보기를 생성하기 위한 서로 다른 방법으로 해석될 수 있다.
논문에서는 두 개의 랜덤 한 변수 $a$와 $b$를 데이터의 서로 다른 두 보기로 정의하였다. self-supervised learning에서, $a$와 $b$는 똑같은 이미지의 두 augmentation이다. vision-language representation learning에서는 semantic meaning을 캡처하는 image-text 쌍의 서로 다른 변수 $a$와 $b$로 고려하였다. 이는 $a$와 $b$ 간의 MI를 최대화시킴으로써 달성될 수 있다. 실제로 논문에서는 다음과 같이 정의되는 InfoNCE loss를 최소화시킴으로써 $MI(a, b)$에 대한 lower bound를 최소화시켰다. InfoNCE loss는 두 데이터 샘플을 비교하여, 샘플 간의 유사도를 측정하는 데에 활용된다.
여기서 $s(a, b)$는 scoring function이고, $\hat{B}$는 확률 분포로부터 뽑아진 positive sample $b$와 $|\hat{B}|-1$ negative sample로 구성되어 있다.
논문의 ITC loss는 one-hot 라벨을 사용하여 다음과 같이 작성될 수 있다:
$\mathfrak{L}_{itc}$를 최소화하는 것은 InfoNCE의 대칭 버전을 최대화시키는 것처럼 보일 수 있다. 그래서 ITC는 2개의 modality($I$ & $T$)를 image-text 쌍의 2개의 보기로 고려하고, positive 쌍에 대한 이미지 보기와 텍스트 보기 간의 MI를 최대화하는 unimodal encoder를 학습시킨다.
그리고 MLM을 masked word token과 이것의 masked context 간의 MI를 최대화하는 것으로 해석될 수 있다. 특히 MLM loss를 one-hot 라벨을 사용하여 다음과 같이 재작성할 수 있다:
여기서 $\psi (y) : \mathfrak{V} \to \mathbb{R}^{d}$는 word token $y$를 벡터로 매핑하는 multi-modal encoder의 출력 레이어에서의 lookup function이고, $\mathfrak{V}$는 전체 vocabulary 세트이고, $f(I, \hat{T})$는 masked context에 해당하는 multi-modal encoder의 최종 hidden state를 반환하는 함수이다. 그래서 MLM은 image-text 쌍의 두 가지 보기를 다음과 같이 간주한다:
- 랜덤 하게 선택된 word token
- image + 해당 단어가 마스킹된 text
ITC와 MLM은 image-text 쌍으로부터 modality 분리 또는 word masking을 통해 얻은 부분적 정보를 취함으로써 보기를 생성한다. 논문의 momentum distillation은 전체 제안 분포로부터 대안이 되는 보기를 생성하는 것으로 간주될 수 있다. 위의 ITC MoD 수식에서 $KL(\textbf{p}^{i2t}(I), \textbf{q}^{i2t}(I))$을 최소화하는 것은 다음의 objective를 최소화시키는 것과 동일하다.
이 objective는 이미지 $I$를 사용하여 유사한 semantic meaning을 공유하는 텍스트에 대한 $MI(I, T_{m})$을 최대화하는데, 왜냐하면 텍스트는 더 큰 $q_{m}^{i2t}(I)$를 가지기 때문이다. 이와 유사하게, $ITC_{MoD}$는 $T$와 유사한 이미지에 대한 $MI(I_{m}, T)$를 최대화시킨다. 논문에서는 masked word $y^{msk}$에 대한 대안이 되는 보기 $y' \in \mathfrak{V}$를 생성하는 $MLM_{MoD}$을 보여주기 위한 똑같은 method를 따랐고, $y'$과 $(I, \hat{T})$ 간의 MI를 최대화하였다. 그래서 momentum distillation은 기존의 보기에 augmentation을 수행하는 것처럼 간주될 수 있다. momentum model은 기존의 image-text 쌍에는 없는 보기의 다양한 세트를 생성할 수 있고, base model이 view-invariant semantic 정보를 캡처하는 representation을 학습할 수 있게 만들었다.
4. Downstream V+L Tasks
논문에서는 pre-trained model을 5개의 downstream V+L task에 적용하였다.
- Image-Text Retrieval
- Visual Entailment
- Visual Question Answering(VQA)
- Natural Language for Visual Reasoning(NLVR2)
- Visual Grounding
5. Experiments
5-1. Evaluation on the Proposed Methods
논문에서는 처음에 제안된 method의 효과를 평가하였다. 표 1은 method의 서로 다른 변형을 사용하여 downstream task의 성능을 보여준다. baseline pre-training task(MLM+ITC)와 비교해서, ITC를 추가하는 것은 모든 task에 대해서 pre-trained model의 성능을 향상시켜준다.
제안된 hard negative mining은 ITM을 더욱 정보적인 학습 샘플을 찾음으로써 향상시킨다. 게다가 momentum distillation을 추가하는 것은 ITC(4행), MLM(5행), 모든 downstream tasks(6행)에 대한 학습을 향상시킨다. 마지막 행에서는 ALBEF가 pre-training 성능을 향상시키기 위해 더욱 noise가 섞인 웹 데이터를 효과적으로 활용한다는 것을 보여주고 있다.
6. Conclusion
이 논문에서는 vision-language representation 학습을 위한 새로운 프레임워크인 ALBEF를 제안하였다. ALBEF는 처음에 nuimodal representation과 text representation을 정렬하고 그다음에 multimodal encoder를 사용하여 이들을 융합한다. 논문에서는 이론적 및 실험적으로 제안된 image-text contrastive learning과 momentum distillation의 효과를 입증하였다. 기존의 method들과 비교했을 때, ALBEF는 여러 downstream V+L tasks에서 더 나은 성능과 더 빠른 추론 속도를 제공하였다.
출처
https://arxiv.org/abs/2107.07651
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
Large-scale vision and language representation learning has shown promising improvements on various vision-language tasks. Most existing methods employ a transformer-based multimodal encoder to jointly model visual tokens (region-based image features) and
arxiv.org