
The overview of this paper
기존의 Vision-Language Pre-training(VLP)는 많은 multi-modal downstream task에서 인상적인 성능을 보여주고 있지만, 값비싼 annotation은 기존 모델들의 scalability를 제한하고, 다양한 dataset-specific objective의 소개로 pre-training 프로시저를 복잡하게 만든다. 이 논문에서는 이러한 제약을 완화하고 최소한의 pre-training 프레임워크Simple Visual Language Model(SimVLM)를 소개하였다. SimVLM은 다음과 같은 이점을 가진다.
- 대규모의 weak supervision을 사용함으로써 학습 복잡도를 낮춤
- 하나의 prefic language modeling objective를 사용해서 학습
그 결과 SimVLM은 open-ended VQA와 cross-modality transfer를 포함하는 zero-shot 특성을 가능하게 해주는 강력한 일반화와 전이 능력을 얻을 수 있었다.
Table of Contents
1. Introduction
2. SimVLM
2-1. Background
2-2. PrefixLM
2-3. Architecture
2-4. Datasets
3. Experiments
4. Ablation Study
1. Introduction
textual representation pre-training의 성공에 영감을 받아, multi-modal(visual & textual) model을 만들려고 하는 많은 노력들이 있었다. 요즘의 연구들에서는 vision-language(VL) 벤치마크에서 fine-tune 되어야 하는 두 modality 간의 공동 representation을 학습하는 vision-language pre-training(VLP)를 활용한다. 이미지와 텍스트 간의 정렬을 캡처하기 위해서 이전의 method들은 다음의 2 가지의 human-labeled 데이터셋을 광범위하게 사용하였다.
- object detection 데이터셋: supervised object detector의 학습을 위해 사용됨. 이미지로부터 RoI 추출을 가능하게 해 줌.
- 정렬된 image-text 쌍 데이터셋: 추출된 RoI feature와 paired 텍스트의 조합을 입력으로 받는 fusion model의 MLM pre-training을 위해 사용됨.
한정된 규모의 human-annotated 데이터 때문에 성능 향상을 위해 다양한 task-specific auxiliary loss를 사용하게 된다. 하지만, 이러한 auxiliary loss는 VLP의 pre-training 프로토콜을 복잡하게 만든다. 이러한 점을 해결하기 위해 최근의 연구들은 pre-training을 수행하기 위해 웹에서 수집된 weakly labeled 데이터셋을 사용하였는데, 좋은 성능을 얻었을 뿐만 아니라 이미지 분류와 image-text retrieval에서 확실한 zero-shot 능력을 보여줬다. 그럼에도 불구하고 이러한 방법은 주로 특정 작업에 중점을 두므로 VL 벤치마크에 대한 일반적인 pretraining-finetuning representation으로 사용되지 않을 수 있다.
논문에서는 기존 방법의 이러한 단점에서 다음과 같은 특성을 가지는 SimVLM을 만드는데 관심을 가졌다. 이 SimVLM은 단지 language modeling objective를 weakly aligned image-text 쌍에 사용함으로써 VLP를 상당히 간단하게 만드는 모델이다.
- pre-training & fine-tuning 패러다임이고, 기존 VL 벤치마크에서 유망한 성능을 달성하는 모델 🔥
- 복잡한 pre-training 프로토콜 필요 ❌
- cross-modal 세팅에서 잠재적 text guided zero-shot 정규화 능력을 가지는 모델 👍
그리고 다음은 SimVLM을 구성하는 요소들이다.
- Objective: PrefixLM을 사용하였음 ➡️ 텍스트 생성(GPT-3) 뿐만 아니라 양방향 문맥 정보 처리(BERT)가 가능함. 😮
- Arhitecture: ViT/CoAtNet 프레임워크를 사용해서 raw image를 입력으로 받음. 이 모델은 대규모의 데이터에 적용 가능하고 PrefixLM에도 손쉽게 적용 가능함. 📐
- Data: 위의 셋업은 object detection의 필요를 완화하고 대규모 weakly labeled 데이터셋 활용을 가능하게 해 줌. 이것은 zero-shot 일반화에 잠재적인 힘을 가지게 해줌. ✨
다음은 SimVLM이 가지는 장점들이다.
- 매우 간단함! 😙
- object detection pre-training & auxiliary loss 둘 다 필요 ❌
- 이전의 method들보다 더 나은 성능 🔺
2. SimVLM
2-1. Background
논문에서는 총 두 가지의 training objective를 살펴봤는데, 이 둘에 대해서 간단하게만 살펴보고 자세한 내용은 넘기도록 하겠다.
- bi-directional Masked Language Modeling(MLM): 문맥의 이해를 도와주는 training objective로, BERT에서 처음 소개되었다. 특징은 문맥을 양방향으로 처리한다는 것이다. masked token을 예측할 때, 그 토큰의 앞뒤를 모두 참고해서 예측할 수 있다. 따라서 문맥의 이해에 특화되어 있다.
- uni-directional Language Modeling(LM): 문장 생성을 도와주는 training objective로, GPT와 같은 모델에 사용된다. 특징은 문맥을 단방향으로 처리해서 생성하려는 토큰의 이전 단어들만 참고할 수 있다. 따라서 문장의 생성에 특화되어 있다.
2-2. PrefixLM
LM loss가 있는 pre-training을 통해 도입된 zero-shot 능력에서 동기를 얻어, 논문에서는 Prefix Language Modeling(PrefixLM)을 사용해서 vision-language representation을 pre-train 하기로 제안하였다. PrefixLM은 prefix 시퀀스(다음의 수식에서 $\textbf{x}_{<T_{p}}$)에서 bi-directional attention을 가능하게 하고 나머지 토큰(다음의 수식에서 $\textbf{x}_{\geq T_{p}}$)에 대해서만 autoregressive factorization을 수행한다는 점에서 표준 LM과 다르다. pre-training 중에 길이 $T_{p}$인 토큰의 prefix 시퀀스는 입력 문장으로부터 줄어들게 되고 training objective는 다음과 같아진다:
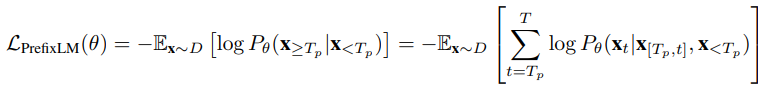
직관적으로 웹 문서에서 이미지는 텍스트 이전에 나타나기 때문에 이미지는 textual description을 위한 prefix라고 생각할 수 있다. 따라서 주어진 image-text 쌍에 대해 논문에서는 길이 $T_{i}$의 이미지 feature 시퀀스를 텍스트 시퀀스 앞에 붙인다. 그리고 text data only에서 LM loss를 계산하기 위해 길이 $T_{p} \geq T_{i}$의 prefix를 샘플링하기 위해서 모델을 사용한다. (그림 1 참고) 이전 MLM 스타일 VLP method들과 비교해서, 논문의 seq2seq 프레임워크의 PrefixLM 모델은 MLM의 양방향 문맥 rerpesentation도 가능할 뿐만 아니라 LM과 유사한 텍스트 생성도 수행이 가능하다.
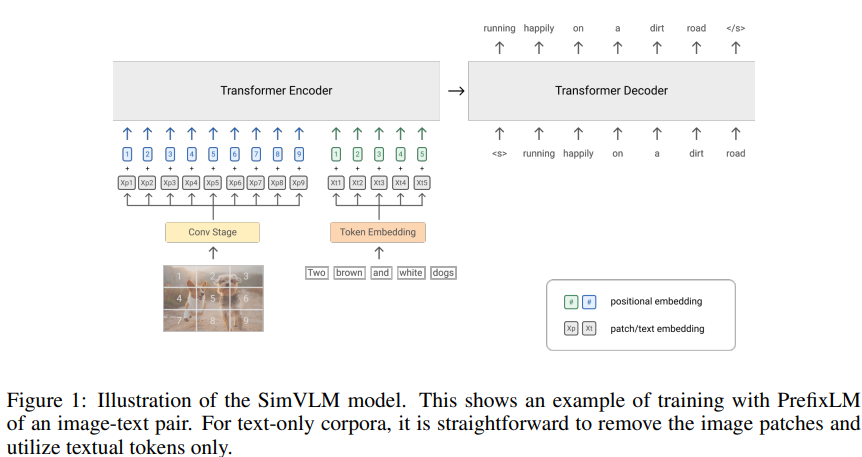
2-3. Architecture
논문에서는 vision과 language task에서 모두 성공적인 모습을 보여주고 있는 Transfomer를 backbone으로 사용하였다. 기존의 LM과 달리 PrefixLM은 prefix 시퀀스에서 양방향 attention을 가능하게 해 주고, 따라서 decoder-only & encoder-decoder seq2seq LM에 적용을 가능하게 해 준다.
SimVLM 모델의 구조는 그림 1에 묘사되어 있다. visual modlaity와 textual modality 관점에서 설명하도록 하겠다.
- visual modality: ViT & CoAtNet을 활용하였다. raw image $\textbf{x} \in \mathbb{R}^{H \times W \times C}$를 입력으로 받아서 패치의 flattened 1D sequence $\textbf{x}){p} \in \mathbb{R}^{T_{i} \times D}$로 매핑을 해서 Transformer의 입력으로 사용한다. 여기서 $D$는 transformer layer의 고정된 hidden size이고 $T_{i} = \frac {HW}{P^{2}}$는 주어진 패치 사이즈 $P$에 대한 이미지 토큰의 길이이다. 이전의 방법들을 따라서 논문에서는 ResNet의 첫 3블록으로 구성되어 있는 Conv stage를 사용해서 contextualized 패치를 추출하였다. 이것은 ViT에서 사용되는 naive linear projection(1×1 Conv 레이어와 동일) 보다 유리하다는 것을 발견하였다.
- textual modality: 입력 문장을 sub-word 토큰으로 토큰화하는 기존의 방법을 따랐고, 임베딩은 고정된 voacbulary를 위해 학습된다.
position 정보를 얻기 위해 논문에서는 이미지와 텍스트에 개별적으로 2개의 학습 가능한 1D positional embedding을 추가하였고, 이미지 패치와 transformer layer 간에 추가적으로 2D relative attention을 추가하였다. 그리고 추가적인 modality type embedding은 추가하지 않았다.
2-4. Datasets
논문의 방식은 object detection 모듈에 의존하지 않고, 오직 raw image patch 입력을 사용하여 작동하기 때문에, 대규모 noisy image-text 데이터를 사용해서 처음부터 모든 모델 파라미터를 pre-train 하였다. 특히, 논문에서는 ALIGN에서 소개된 웹에서 수집된 데이터에 최소한의 후처리를 거친 image & alt-text 쌍을 사용하였다. 이와는 반대로, 논문의 PrefixLM의 공식은 modality-agnostic 하고 따라서 alt-text 데이터에서 noisy text supervision을 보상하기 위한 text-only corpora를 추가적으로 포함할 수 있다. 이러한 통합된 PrefixLM은 modality 불일치를 감소시키고 모델의 퀄리티를 향상시킨다.
2개의 pre-training 스테이지와 다양한 auxiliary objectives로 구성되어 있는 이전의 VLP method와 비교하여 SimVLM은 하나의 language modeling loss를 사용하는 one-pass pre-training만을 필요로 해서 Simple Visual Language Model이라고 불리게 된 것이다.
3. Experiments
논문에서는 다양한 visual-linguistic 벤치마크 세트에서 실험을 진행하였다: visual question answering(VQA), image cpationing, visual reasoning, visual entailment, multimodal translation. 그리고 SimVLM의 zero-shot 일반화 능력을 open-ended VL understanding에서 연구하였다.
3-1. Comparison with Existing Approaches
vision-language pre-training의 퀄리티를 검사하기 위해 논문에서는 SimVLM을 유명한 multi-modal task의 SoTA VLP method(LXMERT, VL-T5, UNITER, OSCAR, Villa, SOHO, UNMO, VinVL)들과 비교하였다.
다음의 표 1에서 보이듯이 SimVLM은 모든 기존 모델들을 능가하는 성능을 보여주고, 상당한 마진을 가지고 새로운 SoTA를 달성하였다. 이것은 논문의 generative pre-training 방식이 MLM 기반 모델들과 비슷한 성능을 보여주고 weak supervision을 사용하는 간단한 프레임워크는 high-quality multi-modal representation을 학습하는데 충분하다는 것을 보여준다.
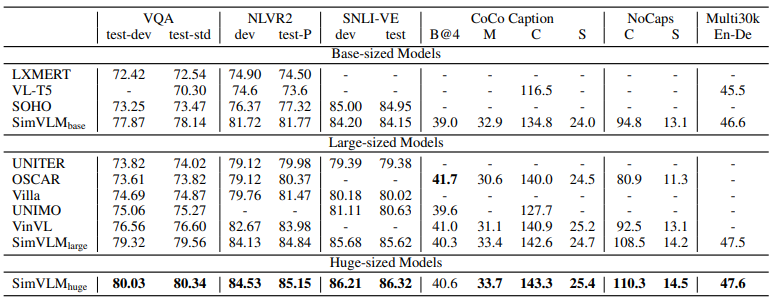
구별 task에 대해서, $SimVLM_{base}$는 더 적은 능력을 사용하고도 이미 이전의 모든 method들을 능가하는 성능을 보여줬다. 그리고 $SimVLM_{huge}$는 이전의 SoTA에 비해 4 포인트 더 향상된 결과를 보여줬다. 게다가 SimVLM은 NLVR2와 SNLI-VE에서 이전의 method들을 일관되게 능가하는 성능을 보여줬다. 이는 이 모델의 더욱 복잡한 visual-linguistic reasoning에 대한 처리 능력을 설명한다. image captioning과 image translation을 포함하는 생성 task에 대해서 SimVLM은 naive fine-tuning 기술을 사용하여 큰 성능 향상을 보여줬다. 논문의 모델은 CoCo captioning과 Multi30k 에서도 좋은 성능을 보여줬다. 이 실험을 통해 SimVLM이 최소한의 pre-training & fine-tuning 프로시저를 사용해서 더 나은 성능의 pretraining-finetuning 패러다임이 되었다는 것을 보여줬다.
3-2. Zero-shot Generalization
generative modeling과 weak supervision을 사용한 scaling의 가장 중요한 이점은 zero-shot 일반화에 대한 잠재력이다. 이 섹션에서는 이전에 해본 적이 거의 없던 3개의 서로 다른 zero-shot 응용 VLP 작업에 대한 결과를 보여줬다: 본 적 없는 task, modality, test instances로 전달.
Zero-shot/Few-shot Image Captioning
SimVLM의 pre-training 프로시저는 real-word web corpus에서 noisy image captioning objective로 해석될 수 있다. 이를 위해 pre-trained SimVLM 모델을 사용하여 zero-shot 세팅에서는 image captioning 벤치마크에서 바로 디코딩을 하고, few-shot 세팅에서는 5개의 epoch에 대해 1%의 학습 데이터를 fine-tune 하였다. 논문에서는 또한 "A picture of"라는 prompt를 사용하는 decoded caption의 퀄리티를 향상시킨다는 것을 발견하였다.
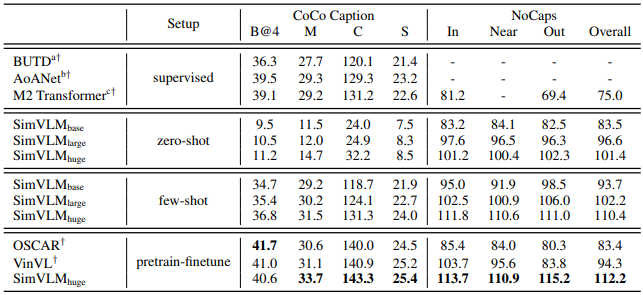
표 2에서 보이는 것처럼 SimVLM의 zero-shot & few-shot 성능을 fully supervised baseline과 견줄 만한 성능을 보여주고, pre-trained model 보다 더 나은 스코어를 얻음으로써 concept-rich NoCaps 벤치마크에서 강력한 일반화 성능을 보여줬다. 그림 2의 (a)를 보면 SimVLM의 다음과 같은 특성들을 알 수 있다.
- 그림 2 (a): real-world concept를 캡처할 뿐만 아니라 visual input의 세밀한 묘사도 제공. decoding 된 샘플은 여러 object를 사용하여 복잡한 장면 설명이 가능하다. 자동차 브랜드나 모델 같은 fine-grained abstraction의 이해도 보여준다. 어려운 이미지에 대해서도 robustness를 보여준다.
Zero-shot Cross-modality Transfer
기존의 pre-training method들은 동종의 데이터 공간 간에 성공적인 지식 전달을 보여줬다. 이 셋업에 영감을 받아서 논문에서는 VLP model을 활용하는 새로운 zero-shot cross-modality transfer 패러다임을 실험해 보았고, 논문의 모델이 modality 간에 얼마나 잘 일반화하는지를 평가하였다. 텍스트 학습 데이터는 visual 학습 데이터보다 비교적 더 쉽게 구할 수 있기 때문에, 논문에서는 SimVLM을 text-only downstream 데이터에서 fine-tune 하고 그다음에 공동 VL task에서 zero-shot transfer를 평가하였다.
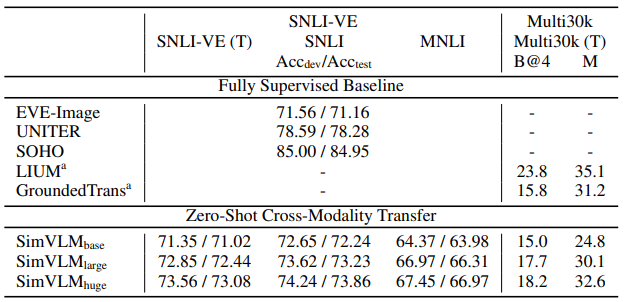
논문에서는 zero-shot transfer 성능을 검사하기 위해 SNLI-VE와 Multi30k를 활용하였다. 표 3에 보이는 것처럼, SimVLM은 zero-shot 세팅에서 fully supervised baseline와 비슷한 성능을 보여줬다.
게다가 SimVLM은 MNLI 데이터셋으로부터 SNLI-VE 데이터셋으로 전달을 함으로써 도메인 적응도 가능하다. 여기서 데이터는 서로 다른 modality로부터 올뿐만 아니라 다른 도메인에서 오기도 한다. 논문에서는 SimVLM을 사용하여 서로 다른 language와 modality 간에 전달이 가능하다는 것을 발견하였다. 표 3은 SimVLM이 generative task에서 modality와 language 간의 지식 전달이 가능하다는 것을 보여주면서 supervised baseline에 견줄 만한 성능 또한 달성하였다. (디코딩된 예시는 그림 2의 (b) 참고) 결과는 zero-shot cross-modality 전달이 weakly labeled 데이터의 scaling과 함께 나타난다는 것을 제안한다.
Open-ended VQA
SimVLM과 같은 generative model은 VQA 같은 문제를 사전에 정의된 대답 중에서 하나를 고르는 문제가 아닌 자유형식의 answer를 생성하는 문제로 생각하는 대안이 되는 솔루션을 제공하였다. 이를 위해, 논문에서는 앞서 언급한 PrefixLM loss를 사용해서 SimVLM을 fine-tune 하였다. 여기서는 이미지와 질문을 prefix로 생각하고 모델을 학습시켜서 대답을 생성하게 하였다.
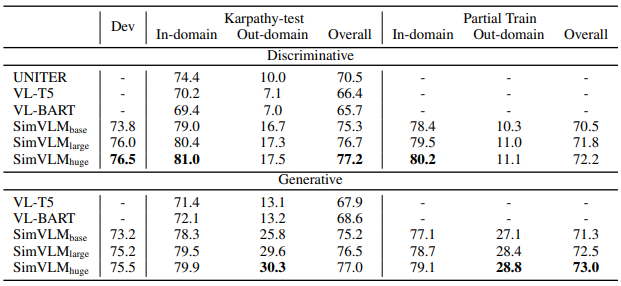
다음의 표 4에서 분류 method를 사용한 generative 방식들을 비교하였다. 첫 번째로 논문에서는 Karpathy-test split의 희귀한 대답을 사용한 질문에서 모델의 성능을 평가하였다. 결과는 SimVLM이 모든 split에서 generative & discriminative baseline보다 좋은 성능을 보여준다는 것을 보여준다. 여기서 더욱 중요한 것은 generative SimVLM이 out-of-domain split에 대해서 17 포인트 정도의 상당한 성능 향상을 보여준다는 것인데, 이는 SimVLM의 강력한 일반화 능력을 보여준다. 하지만, 이러한 셋업은 희귀한 대답에만 집중할 수도 있기 때문에, 모델이 어떻게 본 적 없는 일반적인 대답을 잘 일반화시키는지는 불분명하다. 이를 위해 Partial Train도 수행해 본 결과, 표 4는 generative SimVLM이 이 셋업에서도 유망한 성능을 보여준다는 것을 보여주고 있다. 전반적으로 일반적인 셋업에서 generative SimVLM이 discriminative SimVLM과 비슷한 성능을 보여주고, 일반적으로 out-of-domain 케이스에서 더 나은 성능을 보여준다.
논문에서는 score 계산을 위해 생성된 대답과 human label 간의 완벽한 일치를 사용하였지만, 모델은 서로 다른 형식 또는 동의어를 사용해서 적절한 대답을 생성할 수도 있다. 따라서, 그림 2의 (c)에서 괜찮은 생성 결과들을 보여주고 있다. 이 결과를 보면 SimVLM이 3,129개의 후보자 세트에 포함되어 있지 않은 대답(surgeon & wood carving)을 생성 가능하다는 것을 보여주고 있다. 이는 SimVLM이 pre-training corpus으로부터 얻은 지식을 VQA에 전달할 수 있다는 것을 보여준다. 따라서 SimVLM이 fine-tuning 없이 zero-shot VQA를 수행할 수 있는지에 대한 궁금증이 생기는 것은 자연스럽다. 논문의 실험에 따르면 그림 2의 (d)에서 보여지는 것처럼 prompting 문장을 완성시킴으로써 SimVLM은 '대답'을 생성할 수 있다. 그럼에도 불구하고 모델이 실제 질문에 대한 의미 있는 답변을 생성하는 데 부족함이 있음을 관찰했다. 논문에서는 이것이 pre-training 데이터의 낮은 퀄리티 때문이라고 가정하였다. 이 가정을 증명하기 위해 논문에서는 정리되어 있는 WIT 데이터셋에서 pre-training을 진행해 본 결과, 그림 2의 (e)는 그럴듯한 open-ended VQA 능력을 보여주고 있다.

출처
https://arxiv.org/abs/2108.10904
SimVLM: Simple Visual Language Model Pretraining with Weak Supervision
With recent progress in joint modeling of visual and textual representations, Vision-Language Pretraining (VLP) has achieved impressive performance on many multimodal downstream tasks. However, the requirement for expensive annotations including clean imag
arxiv.org
'Paper Reading 📜 > multimodal models' 카테고리의 다른 글
The overview of this paper
기존의 Vision-Language Pre-training(VLP)는 많은 multi-modal downstream task에서 인상적인 성능을 보여주고 있지만, 값비싼 annotation은 기존 모델들의 scalability를 제한하고, 다양한 dataset-specific objective의 소개로 pre-training 프로시저를 복잡하게 만든다. 이 논문에서는 이러한 제약을 완화하고 최소한의 pre-training 프레임워크Simple Visual Language Model(SimVLM)를 소개하였다. SimVLM은 다음과 같은 이점을 가진다.
- 대규모의 weak supervision을 사용함으로써 학습 복잡도를 낮춤
- 하나의 prefic language modeling objective를 사용해서 학습
그 결과 SimVLM은 open-ended VQA와 cross-modality transfer를 포함하는 zero-shot 특성을 가능하게 해주는 강력한 일반화와 전이 능력을 얻을 수 있었다.
Table of Contents
1. Introduction
2. SimVLM
2-1. Background
2-2. PrefixLM
2-3. Architecture
2-4. Datasets
3. Experiments
4. Ablation Study
1. Introduction
textual representation pre-training의 성공에 영감을 받아, multi-modal(visual & textual) model을 만들려고 하는 많은 노력들이 있었다. 요즘의 연구들에서는 vision-language(VL) 벤치마크에서 fine-tune 되어야 하는 두 modality 간의 공동 representation을 학습하는 vision-language pre-training(VLP)를 활용한다. 이미지와 텍스트 간의 정렬을 캡처하기 위해서 이전의 method들은 다음의 2 가지의 human-labeled 데이터셋을 광범위하게 사용하였다.
- object detection 데이터셋: supervised object detector의 학습을 위해 사용됨. 이미지로부터 RoI 추출을 가능하게 해 줌.
- 정렬된 image-text 쌍 데이터셋: 추출된 RoI feature와 paired 텍스트의 조합을 입력으로 받는 fusion model의 MLM pre-training을 위해 사용됨.
한정된 규모의 human-annotated 데이터 때문에 성능 향상을 위해 다양한 task-specific auxiliary loss를 사용하게 된다. 하지만, 이러한 auxiliary loss는 VLP의 pre-training 프로토콜을 복잡하게 만든다. 이러한 점을 해결하기 위해 최근의 연구들은 pre-training을 수행하기 위해 웹에서 수집된 weakly labeled 데이터셋을 사용하였는데, 좋은 성능을 얻었을 뿐만 아니라 이미지 분류와 image-text retrieval에서 확실한 zero-shot 능력을 보여줬다. 그럼에도 불구하고 이러한 방법은 주로 특정 작업에 중점을 두므로 VL 벤치마크에 대한 일반적인 pretraining-finetuning representation으로 사용되지 않을 수 있다.
논문에서는 기존 방법의 이러한 단점에서 다음과 같은 특성을 가지는 SimVLM을 만드는데 관심을 가졌다. 이 SimVLM은 단지 language modeling objective를 weakly aligned image-text 쌍에 사용함으로써 VLP를 상당히 간단하게 만드는 모델이다.
- pre-training & fine-tuning 패러다임이고, 기존 VL 벤치마크에서 유망한 성능을 달성하는 모델 🔥
- 복잡한 pre-training 프로토콜 필요 ❌
- cross-modal 세팅에서 잠재적 text guided zero-shot 정규화 능력을 가지는 모델 👍
그리고 다음은 SimVLM을 구성하는 요소들이다.
- Objective: PrefixLM을 사용하였음 ➡️ 텍스트 생성(GPT-3) 뿐만 아니라 양방향 문맥 정보 처리(BERT)가 가능함. 😮
- Arhitecture: ViT/CoAtNet 프레임워크를 사용해서 raw image를 입력으로 받음. 이 모델은 대규모의 데이터에 적용 가능하고 PrefixLM에도 손쉽게 적용 가능함. 📐
- Data: 위의 셋업은 object detection의 필요를 완화하고 대규모 weakly labeled 데이터셋 활용을 가능하게 해 줌. 이것은 zero-shot 일반화에 잠재적인 힘을 가지게 해줌. ✨
다음은 SimVLM이 가지는 장점들이다.
- 매우 간단함! 😙
- object detection pre-training & auxiliary loss 둘 다 필요 ❌
- 이전의 method들보다 더 나은 성능 🔺
2. SimVLM
2-1. Background
논문에서는 총 두 가지의 training objective를 살펴봤는데, 이 둘에 대해서 간단하게만 살펴보고 자세한 내용은 넘기도록 하겠다.
- bi-directional Masked Language Modeling(MLM): 문맥의 이해를 도와주는 training objective로, BERT에서 처음 소개되었다. 특징은 문맥을 양방향으로 처리한다는 것이다. masked token을 예측할 때, 그 토큰의 앞뒤를 모두 참고해서 예측할 수 있다. 따라서 문맥의 이해에 특화되어 있다.
- uni-directional Language Modeling(LM): 문장 생성을 도와주는 training objective로, GPT와 같은 모델에 사용된다. 특징은 문맥을 단방향으로 처리해서 생성하려는 토큰의 이전 단어들만 참고할 수 있다. 따라서 문장의 생성에 특화되어 있다.
2-2. PrefixLM
LM loss가 있는 pre-training을 통해 도입된 zero-shot 능력에서 동기를 얻어, 논문에서는 Prefix Language Modeling(PrefixLM)을 사용해서 vision-language representation을 pre-train 하기로 제안하였다. PrefixLM은 prefix 시퀀스(다음의 수식에서 $\textbf{x}_{<T_{p}}$)에서 bi-directional attention을 가능하게 하고 나머지 토큰(다음의 수식에서 $\textbf{x}_{\geq T_{p}}$)에 대해서만 autoregressive factorization을 수행한다는 점에서 표준 LM과 다르다. pre-training 중에 길이 $T_{p}$인 토큰의 prefix 시퀀스는 입력 문장으로부터 줄어들게 되고 training objective는 다음과 같아진다:
직관적으로 웹 문서에서 이미지는 텍스트 이전에 나타나기 때문에 이미지는 textual description을 위한 prefix라고 생각할 수 있다. 따라서 주어진 image-text 쌍에 대해 논문에서는 길이 $T_{i}$의 이미지 feature 시퀀스를 텍스트 시퀀스 앞에 붙인다. 그리고 text data only에서 LM loss를 계산하기 위해 길이 $T_{p} \geq T_{i}$의 prefix를 샘플링하기 위해서 모델을 사용한다. (그림 1 참고) 이전 MLM 스타일 VLP method들과 비교해서, 논문의 seq2seq 프레임워크의 PrefixLM 모델은 MLM의 양방향 문맥 rerpesentation도 가능할 뿐만 아니라 LM과 유사한 텍스트 생성도 수행이 가능하다.
2-3. Architecture
논문에서는 vision과 language task에서 모두 성공적인 모습을 보여주고 있는 Transfomer를 backbone으로 사용하였다. 기존의 LM과 달리 PrefixLM은 prefix 시퀀스에서 양방향 attention을 가능하게 해 주고, 따라서 decoder-only & encoder-decoder seq2seq LM에 적용을 가능하게 해 준다.
SimVLM 모델의 구조는 그림 1에 묘사되어 있다. visual modlaity와 textual modality 관점에서 설명하도록 하겠다.
- visual modality: ViT & CoAtNet을 활용하였다. raw image $\textbf{x} \in \mathbb{R}^{H \times W \times C}$를 입력으로 받아서 패치의 flattened 1D sequence $\textbf{x}){p} \in \mathbb{R}^{T_{i} \times D}$로 매핑을 해서 Transformer의 입력으로 사용한다. 여기서 $D$는 transformer layer의 고정된 hidden size이고 $T_{i} = \frac {HW}{P^{2}}$는 주어진 패치 사이즈 $P$에 대한 이미지 토큰의 길이이다. 이전의 방법들을 따라서 논문에서는 ResNet의 첫 3블록으로 구성되어 있는 Conv stage를 사용해서 contextualized 패치를 추출하였다. 이것은 ViT에서 사용되는 naive linear projection(1×1 Conv 레이어와 동일) 보다 유리하다는 것을 발견하였다.
- textual modality: 입력 문장을 sub-word 토큰으로 토큰화하는 기존의 방법을 따랐고, 임베딩은 고정된 voacbulary를 위해 학습된다.
position 정보를 얻기 위해 논문에서는 이미지와 텍스트에 개별적으로 2개의 학습 가능한 1D positional embedding을 추가하였고, 이미지 패치와 transformer layer 간에 추가적으로 2D relative attention을 추가하였다. 그리고 추가적인 modality type embedding은 추가하지 않았다.
2-4. Datasets
논문의 방식은 object detection 모듈에 의존하지 않고, 오직 raw image patch 입력을 사용하여 작동하기 때문에, 대규모 noisy image-text 데이터를 사용해서 처음부터 모든 모델 파라미터를 pre-train 하였다. 특히, 논문에서는 ALIGN에서 소개된 웹에서 수집된 데이터에 최소한의 후처리를 거친 image & alt-text 쌍을 사용하였다. 이와는 반대로, 논문의 PrefixLM의 공식은 modality-agnostic 하고 따라서 alt-text 데이터에서 noisy text supervision을 보상하기 위한 text-only corpora를 추가적으로 포함할 수 있다. 이러한 통합된 PrefixLM은 modality 불일치를 감소시키고 모델의 퀄리티를 향상시킨다.
2개의 pre-training 스테이지와 다양한 auxiliary objectives로 구성되어 있는 이전의 VLP method와 비교하여 SimVLM은 하나의 language modeling loss를 사용하는 one-pass pre-training만을 필요로 해서 Simple Visual Language Model이라고 불리게 된 것이다.
3. Experiments
논문에서는 다양한 visual-linguistic 벤치마크 세트에서 실험을 진행하였다: visual question answering(VQA), image cpationing, visual reasoning, visual entailment, multimodal translation. 그리고 SimVLM의 zero-shot 일반화 능력을 open-ended VL understanding에서 연구하였다.
3-1. Comparison with Existing Approaches
vision-language pre-training의 퀄리티를 검사하기 위해 논문에서는 SimVLM을 유명한 multi-modal task의 SoTA VLP method(LXMERT, VL-T5, UNITER, OSCAR, Villa, SOHO, UNMO, VinVL)들과 비교하였다.
다음의 표 1에서 보이듯이 SimVLM은 모든 기존 모델들을 능가하는 성능을 보여주고, 상당한 마진을 가지고 새로운 SoTA를 달성하였다. 이것은 논문의 generative pre-training 방식이 MLM 기반 모델들과 비슷한 성능을 보여주고 weak supervision을 사용하는 간단한 프레임워크는 high-quality multi-modal representation을 학습하는데 충분하다는 것을 보여준다.
구별 task에 대해서, $SimVLM_{base}$는 더 적은 능력을 사용하고도 이미 이전의 모든 method들을 능가하는 성능을 보여줬다. 그리고 $SimVLM_{huge}$는 이전의 SoTA에 비해 4 포인트 더 향상된 결과를 보여줬다. 게다가 SimVLM은 NLVR2와 SNLI-VE에서 이전의 method들을 일관되게 능가하는 성능을 보여줬다. 이는 이 모델의 더욱 복잡한 visual-linguistic reasoning에 대한 처리 능력을 설명한다. image captioning과 image translation을 포함하는 생성 task에 대해서 SimVLM은 naive fine-tuning 기술을 사용하여 큰 성능 향상을 보여줬다. 논문의 모델은 CoCo captioning과 Multi30k 에서도 좋은 성능을 보여줬다. 이 실험을 통해 SimVLM이 최소한의 pre-training & fine-tuning 프로시저를 사용해서 더 나은 성능의 pretraining-finetuning 패러다임이 되었다는 것을 보여줬다.
3-2. Zero-shot Generalization
generative modeling과 weak supervision을 사용한 scaling의 가장 중요한 이점은 zero-shot 일반화에 대한 잠재력이다. 이 섹션에서는 이전에 해본 적이 거의 없던 3개의 서로 다른 zero-shot 응용 VLP 작업에 대한 결과를 보여줬다: 본 적 없는 task, modality, test instances로 전달.
Zero-shot/Few-shot Image Captioning
SimVLM의 pre-training 프로시저는 real-word web corpus에서 noisy image captioning objective로 해석될 수 있다. 이를 위해 pre-trained SimVLM 모델을 사용하여 zero-shot 세팅에서는 image captioning 벤치마크에서 바로 디코딩을 하고, few-shot 세팅에서는 5개의 epoch에 대해 1%의 학습 데이터를 fine-tune 하였다. 논문에서는 또한 "A picture of"라는 prompt를 사용하는 decoded caption의 퀄리티를 향상시킨다는 것을 발견하였다.
표 2에서 보이는 것처럼 SimVLM의 zero-shot & few-shot 성능을 fully supervised baseline과 견줄 만한 성능을 보여주고, pre-trained model 보다 더 나은 스코어를 얻음으로써 concept-rich NoCaps 벤치마크에서 강력한 일반화 성능을 보여줬다. 그림 2의 (a)를 보면 SimVLM의 다음과 같은 특성들을 알 수 있다.
- 그림 2 (a): real-world concept를 캡처할 뿐만 아니라 visual input의 세밀한 묘사도 제공. decoding 된 샘플은 여러 object를 사용하여 복잡한 장면 설명이 가능하다. 자동차 브랜드나 모델 같은 fine-grained abstraction의 이해도 보여준다. 어려운 이미지에 대해서도 robustness를 보여준다.
Zero-shot Cross-modality Transfer
기존의 pre-training method들은 동종의 데이터 공간 간에 성공적인 지식 전달을 보여줬다. 이 셋업에 영감을 받아서 논문에서는 VLP model을 활용하는 새로운 zero-shot cross-modality transfer 패러다임을 실험해 보았고, 논문의 모델이 modality 간에 얼마나 잘 일반화하는지를 평가하였다. 텍스트 학습 데이터는 visual 학습 데이터보다 비교적 더 쉽게 구할 수 있기 때문에, 논문에서는 SimVLM을 text-only downstream 데이터에서 fine-tune 하고 그다음에 공동 VL task에서 zero-shot transfer를 평가하였다.
논문에서는 zero-shot transfer 성능을 검사하기 위해 SNLI-VE와 Multi30k를 활용하였다. 표 3에 보이는 것처럼, SimVLM은 zero-shot 세팅에서 fully supervised baseline와 비슷한 성능을 보여줬다.
게다가 SimVLM은 MNLI 데이터셋으로부터 SNLI-VE 데이터셋으로 전달을 함으로써 도메인 적응도 가능하다. 여기서 데이터는 서로 다른 modality로부터 올뿐만 아니라 다른 도메인에서 오기도 한다. 논문에서는 SimVLM을 사용하여 서로 다른 language와 modality 간에 전달이 가능하다는 것을 발견하였다. 표 3은 SimVLM이 generative task에서 modality와 language 간의 지식 전달이 가능하다는 것을 보여주면서 supervised baseline에 견줄 만한 성능 또한 달성하였다. (디코딩된 예시는 그림 2의 (b) 참고) 결과는 zero-shot cross-modality 전달이 weakly labeled 데이터의 scaling과 함께 나타난다는 것을 제안한다.
Open-ended VQA
SimVLM과 같은 generative model은 VQA 같은 문제를 사전에 정의된 대답 중에서 하나를 고르는 문제가 아닌 자유형식의 answer를 생성하는 문제로 생각하는 대안이 되는 솔루션을 제공하였다. 이를 위해, 논문에서는 앞서 언급한 PrefixLM loss를 사용해서 SimVLM을 fine-tune 하였다. 여기서는 이미지와 질문을 prefix로 생각하고 모델을 학습시켜서 대답을 생성하게 하였다.
다음의 표 4에서 분류 method를 사용한 generative 방식들을 비교하였다. 첫 번째로 논문에서는 Karpathy-test split의 희귀한 대답을 사용한 질문에서 모델의 성능을 평가하였다. 결과는 SimVLM이 모든 split에서 generative & discriminative baseline보다 좋은 성능을 보여준다는 것을 보여준다. 여기서 더욱 중요한 것은 generative SimVLM이 out-of-domain split에 대해서 17 포인트 정도의 상당한 성능 향상을 보여준다는 것인데, 이는 SimVLM의 강력한 일반화 능력을 보여준다. 하지만, 이러한 셋업은 희귀한 대답에만 집중할 수도 있기 때문에, 모델이 어떻게 본 적 없는 일반적인 대답을 잘 일반화시키는지는 불분명하다. 이를 위해 Partial Train도 수행해 본 결과, 표 4는 generative SimVLM이 이 셋업에서도 유망한 성능을 보여준다는 것을 보여주고 있다. 전반적으로 일반적인 셋업에서 generative SimVLM이 discriminative SimVLM과 비슷한 성능을 보여주고, 일반적으로 out-of-domain 케이스에서 더 나은 성능을 보여준다.
논문에서는 score 계산을 위해 생성된 대답과 human label 간의 완벽한 일치를 사용하였지만, 모델은 서로 다른 형식 또는 동의어를 사용해서 적절한 대답을 생성할 수도 있다. 따라서, 그림 2의 (c)에서 괜찮은 생성 결과들을 보여주고 있다. 이 결과를 보면 SimVLM이 3,129개의 후보자 세트에 포함되어 있지 않은 대답(surgeon & wood carving)을 생성 가능하다는 것을 보여주고 있다. 이는 SimVLM이 pre-training corpus으로부터 얻은 지식을 VQA에 전달할 수 있다는 것을 보여준다. 따라서 SimVLM이 fine-tuning 없이 zero-shot VQA를 수행할 수 있는지에 대한 궁금증이 생기는 것은 자연스럽다. 논문의 실험에 따르면 그림 2의 (d)에서 보여지는 것처럼 prompting 문장을 완성시킴으로써 SimVLM은 '대답'을 생성할 수 있다. 그럼에도 불구하고 모델이 실제 질문에 대한 의미 있는 답변을 생성하는 데 부족함이 있음을 관찰했다. 논문에서는 이것이 pre-training 데이터의 낮은 퀄리티 때문이라고 가정하였다. 이 가정을 증명하기 위해 논문에서는 정리되어 있는 WIT 데이터셋에서 pre-training을 진행해 본 결과, 그림 2의 (e)는 그럴듯한 open-ended VQA 능력을 보여주고 있다.
출처
https://arxiv.org/abs/2108.10904
SimVLM: Simple Visual Language Model Pretraining with Weak Supervision
With recent progress in joint modeling of visual and textual representations, Vision-Language Pretraining (VLP) has achieved impressive performance on many multimodal downstream tasks. However, the requirement for expensive annotations including clean imag
arxiv.org