
The overview of this paper
다양한 SoTA vision & vision-and-language 모델들은 다양한 downstream task에서 좋은 성능을 얻기 위해 대규모의 vision-linguistic pre-training에 의존한다. 일반적으로 이러한 모델들은 주로 cross-model(contrastive) 이거나 multi-modal(earlier fusion)이다. 둘 다 아니라면 specific modality 또는 task를 타깃으로 한다. 앞으로 나아가야 할 방향은 모든 modality를 동시에 처리하는 하나의 universal model인 '토대(foundation)'를 사용하는 것이다. 논문에서는 이러한 모델인 FLAVA를 소개하고 35개의 task에서 이 모델의 인상적인 성능을 보여줬다.
Table of Contents
1. Introduction
2. Background
3. FLAVA: A Foundational Language And Vision Alignment Model
3-1. Model Architecture
3-2. Multimodal Pre-training Objectives
3-3. Unimodal Pre-training Objectives
3-4. Data: Public Multimodal Dataset(PMD)
4. Experiments
1. Introduction
vision & langauge transformer의 대규모 pre-training은 다양한 downstream task에서 인상적인 성능 향상을 이끌고 있다. 특히, CLIP과 ALIGN과 같은 contrastive method는 자연어 supervision이 전이 학습을 위한 매우 좋은 퀄리티의 visual model을 만들 수 있게 해준다고 보여줬다.
하지만 contrastive method에도 다음과 같은 단점이 존재한다.
- cross-modal 환경은 multi-modal 환경에 사용이 용이하지 않음.
- 대규모의 corpora를 필요로 함. 따라서 연구 환경에 적합하지 않음.
만약 서로 다른 능력에 대해 일반화된 '토대 모델' 혹은 범용적인 transformer가 나오게 된다면, 위의 한계점들은 극복될 것이다: vision & language 공간에서 진정한 토대 모델은 vision에만 좋을 뿐만 아니라 language, vision-and-language 문제에도 좋아야 한다. 한 마디로 이 3가지에 대해 동시에 모두 좋은 성능을 보여줘야 한다는 것이다.
서로 다른 modality로부터 정보를 조합해서 하나의 범용적인 architecture를 만드는 것은 사람이 세상을 인식하는 방법과 유사할 뿐만 아니라 더 나은 샘플 효율성과 더 풍부한 representation을 이끈다.
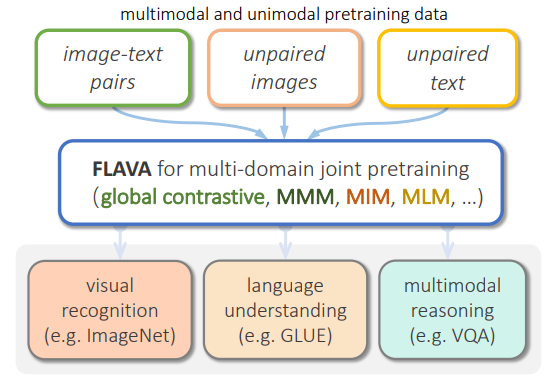
이 논문에서는 vision, language, multi-modal 조합을 동시에 처리하는 것을 목표로 삼는 토대가 되는 language & vision 정렬 모델인 FLAVA를 소개하였다. FLAVA는 unimodal 데이터와 multi-modal 데이터에서 공동으로 pre-train 해서 강력한 representation을 학습한다. FLAVA의 장점은 open source 데이터에서 학습해서 향후 연구 활용에 용이하다는 점과 다른 모델들에 비해 더 적은 양의 데이터를 사용했다는 것이다. 다음의 그림 1은 FLAVA의 대략적인 개요를 보여주고 있다.
2. Background
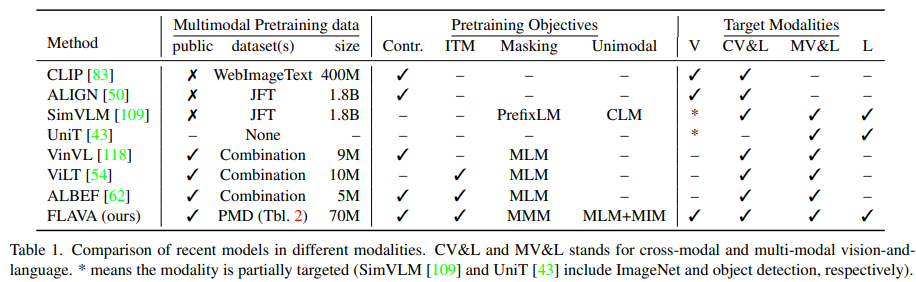
다음의 표 1은 FLAVA모델과 유명한 모델들 간의 광범위한 비교를 보여주고 있다. 최근의 연구들은 다음과 같은 경향들을 가지고 있다.
- single target 도메인에 집중
- 공동 vision-and-language 도메인과 함께 specific unimodal 도메인에 타깃을 둠.
- 모든 도메인에 타깃을 두나, 특정 도메인에서는 task의 specific 세트에 타깃을 둠.
일반적으로 vision-and-language 공간에서 모델은 다음의 2가지 카테고리로 나눠질 수 있다.
- dual encoder: 이미지 & 텍스트를 따로따로 인코딩. 얕은 상호작용을 가짐. unimodal & cross-modal retrieval task에서 좋은 성능을 보여줌.
- fusion encoder: modality 간에 self-attention을 사용. visual reasoning & question answering에서 좋은 성능을 보여줌.
dual encoder 모델은 가능한 $N^{2}$ 조합 중에서 알맞은 $N$ 쌍을 예측하기 위해 contrastive pre-training을 사용한다. 이와는 반대로, fusion encoder는 masked language modeling(MLM), masked image modeling(MIM), 일반적인 language modeling(LM)에 영감을 받았다.
이전 연구들과 비교하여, FLAVA는 각각의 vision, language, vision-and-language 도메인의 광범위한 task에서 작동한다. FLAVA는 dual & fusion encoder 방식을 두 카테고리로부터 pre-training objective를 활용하는 새로운 FLAVA pre-training 스키마를 사용하여 pre-train 할 수 있는 holistic model에 조합하였다. FLAVA는 multi-modal 쌍 데이터와 함께 쌍을 이루지 않는 unimodal 데이터를 활용할 수 있도록 설계되어 unimodal 및 retireval task는 물론 cross-modal 및 multi-modal vision-and-language task를 처리할 수 있는 모델을 생성한다.
3. FLAVA: A Foundational Language And Vision Alignment Model
FLAVA의 목표는 unimodal vision & language 이해 뿐만 아니라 multimodal 추리를 하나의 pre-trained model에서 가능하게 해주는 foundational language & vision representation을 학습하는 것이다.
3-1. Model Architecture
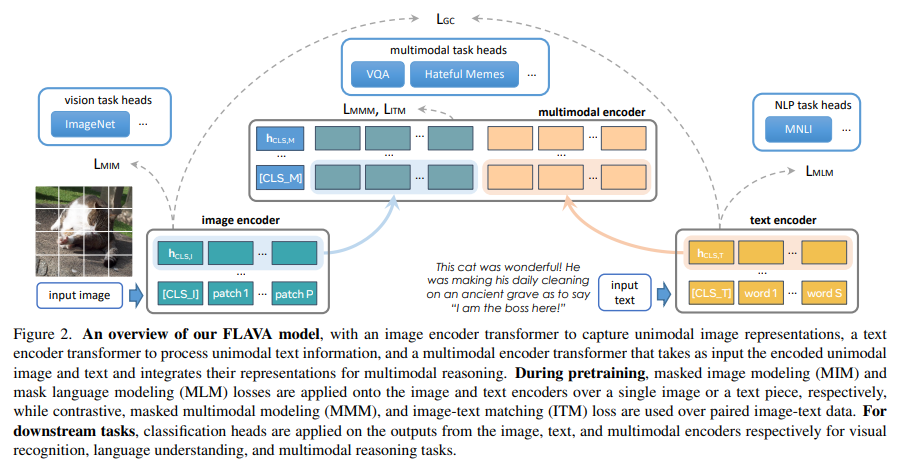
FLAVA 모델의 아키텍처는 다음의 그림 2에 나타나있다. 모델은 다음과 같은 인코더들로 구성되어 있다. 이 모든 인코더들은 transformer에 기반을 두고 있다.
- image encoder: unimodal image representation을 추출
- text encoder: unidmoal text representation을 추출
- multimodal encoder: multi-modal 추리를 위해 이미지 & 텍스트 representation을 융합하고 정렬
Image encoder. ViT-B/16 아키텍처를 사용하였다. 작동 방식은 ViT의 작동 방식과 똑같고, image encoder의 출력은 image hidden state 벡터 $\left\{ \textbf{h}_{I} \right\}$의 리스트이다. 각각은 이미지 패치에 해당하고, [CLS_I]를 위한 추가적 $\textbf{h}_{CLS, I}$를 추가한다. 여기서 [CLS_I] 토큰은 이미지 분류 토큰이다.
Text encoder. 텍스트가 들어오면 tokenization을 적용해서 word vector로 임베딩한다. 그 다음에, Transformer로 word vector를 텍스트 분류 토큰인 [CLS_T]를 위한 $\textbf{h}_{CLS, T}$를 포함하는 hidden state 벡터 $\left\{ \textbf{h}_{T} \right\}$로 인코딩한다. 중요한 것은 이전의 연구들과 달리, FLAVA의 text encoder는 image encoder와 똑같은 ViT 아키텍처를 사용한다.
Multimodal encoder. 이미지 & 텍스트 hidden state를 융합하기 위해 별개의 transformer를 사용한다. 구체적으로, [CLS_M] 토큰을 추가해서 $\left\{ \textbf{h}_{I} \right\}$ & $\left\{ \textbf{h}_{T} \right\}$ 벡터를 합친다. 합쳐진 벡터가 multi-modal encoder transformer에 들어가고, unimodal image & text representation 간에 cross-attention을 통해 두 modality를 융합한다. multimodal encoder의 출력은 hidden states $\left\{ \textbf{h}_{M} \right\}$의 리스트이다.
Applying to downstream tasks. FLAVA 모델은 unimodal & multi-modal task에 간단한 방식으로 적용될 수 있다. visual recognition task에 대해, 논문에서는 이미지 인코더로부터 나온 unimodal $\textbf{h}_{CLS, I}$의 위에 분류기 헤드를 적용하였다. 이와 유사하게, language understanding과 multi-modal reasoning task를 위해, 논문에서는 각각의 텍스트 인코더로부터 나온 $\textbf{h}_{CLS, T}$와 multi-modal 인코더로부터 나온 $\textbf{h}_{CLS, M}$ 위에 분류기 헤드를 적용하였다.
3-2. Multimodal Pre-training Objectives
논문에서는 multi-modal 데이터 뿐만 아니라 unimodal 데이터에서도 pre-training을 통해 강력한 representation을 얻을 수 있도록 목표를 잡았다. FLAVA pre-training은 다음의 multi-modal objective를 포함하고 있다.
Global contrastive(GC) loss. FLAVA의 image-text contrastive loss는 CLIP의 것을 따라하였다. 이미지와 텍스트 배치가 주어지면, 일치하는 이미지 & 텍스트 쌍의 코사인 유사도는 최대화시키고, 일치하지 않는 쌍에 대해서는 최소화시킨다. 이는 각 $\textbf{h}_{CLS,I}$ 및 $\textbf{h}_{CLS,T}$를 임베딩 공간에 선형으로 투영한 다음 L2-정규화, 내적 및 temperature에 따라 조정된 softmax loss를 수행하여 수행된다. 그리고 논문의 loss를 'global contrastive' $L_{GC}$로 부른다. 이것은 'local contrastive' 방식과 구분하기 위해서이다.
Masked multimodal modeling(MMM). 이미지 패치와 텍스트 토큰을 함께 마스킹하고 두 modality에서 공동으로 작동하는 새로운 masked multimodal modeling(MMM) pre-training objective $L_{MMM}$을 소개하였다. 이미지와 텍스트 입력이 주어지면, 각각의 이미지 패치를 word dictionary와 유사한 visual codebook의 인덱스로 매핑하는 pre-trained dVAE tokenizer를 사용해서 입력 이미지 패치를 토큰화한다. 그 다음에, 사각형 블록 이미지 영역에 기반을 둔 이미지 패치의 서브셋을 스페셜 [MASK] 토큰으로 대체하고, 15%의 텍스트 토큰도 [MASK] 토큰으로 대체한다. 그 다음에, multi-modal encoder의 출력 $\left\{ \textbf{h}_{M} \right\}$ 로부터 다층 퍼셉트론을 적용하여 마스킹된 이미지 패치의 visual codebook 인덱스 또는 마스킹된 텍스트 토큰의 word vocabulary 인덱스를 예측한다.
Image-text matching(ITM). 이전의 vision-and-language pre-training 방법들을 따라서 image-text matching loss $L_{ITM}$을 추가하였다. pre-training 중에 논문에서는 일치하거나 일치하지 않는 image-text 쌍 모두를 포함하는 샘플 배치를 넣어준다. 그러면 multi-modal encoder 로부터 나온 $\textbf{h}_{CLS, M}$의 위에 분류기를 적용해서 입력 이미지와 텍스트가 일치하는지 결정한다.
3-3. Unimodal Pre-training Objectives
3-2에서 설명한 objective들은 쌍을 이룬 image-and-text 데이터에서 FLAVA model을 pre-training 할 수 있으며, 대부분의 데이터셋은 다른 modality의 쌍 데이터 없이 unimodal이다. 광범위한 downstream task에 대해서 효율적으로 representation을 학습하기 위해, 논문에서는 이 데이터셋을 사용하고 unimodal 및 정렬되지 않은 정보를 representation에 통합하고자 한다.
이 작업에서는 다음을 통해 어떻게 unimodal 데이터셋으로부터 지식과 정보를 가져오는지 소개하였다.
- multi-modal 데이터셋에서 이미지 & 텍스트 인코더 pre-training
- 전체 FLAVA 모델을 unimodal & multi-modal 데이터셋 모두에서 공동으로 pre-training
- pre-trained 인코더에서 시작한 다음 공동 학습을 통해 두 가지를 결합한다.
stand-alone 이미지 또는 텍스트 데이터를 적용할 때, 논문에서는 masked image modeling(MIM)과 masked language modeling(MLM) loss를 이미지 & 텍스트 인코더를 사용하였다.
Masked image modeling(MIM). unimodal 이미지 데이터셋에서는 BEiT의 사각형 block-wise masking을 따라서 이미지 패치 세트를 마스킹하고 다른 이미지 패치로부터 재구조화하였다. 입력 이미지는 처음에 pre-trained dVAE tokenizer를 사용해서 토큰화되었고, 그 다음에 masked 패치의 dVAE 토큰을 예측하기 위해 이미지 인코더 출력 $\left\{ \textbf{h}_{I} \right\}$에 분류기가 적용되었다.
Masked language modeling(MLM). 논문에서는 stand-alone 텍스트 데이터셋에서 pre-train 하기 위해 텍스트 인코더의 위에 masked language modeling loss를 적용하였다. 입력에서 텍스트 토큰의 일부(15%)는 마스킹되고 unimodal text hidden states 출력 $\left\{ \textbf{h}_{T} \right\}$의 위에 분류기를 사용해서 다른 토큰으로부터 재구조화된다.
Encoder initialization from unimodal pre-training. 논문에서는 3개의 소스의 데이터를 pre-training을 위해 사용하였다: unimodal image(ImageNet-1K), unimodal text data(CCNews & BookCorpus), multimodal image-text 쌍 데이터. 논문에서는 처음에 unimodal text 데이터셋에서 MLM objective를 사용하여 텍스트 인코더를 pre-train 하였다. 그 다음에 이미지 인코더를 위한 서로 다른 pre-training 방법을 실험해보았다: unimodal & multimodal 데이터셋에서 공동으로 학습하기 전에 MIM과 DINO objective를 사용하여 쌍이 맞지 않는 이미지 데이터셋에서 이미지 인코더를 pre-train하였다. 논문에서는 초기화 후 이미지에서 MIM objective로 전환했음에도 불구하고 DINO가 꽤 잘 작동한다는 것을 발견했다. 그 다음에 논문에서는 전체 FLAVA 모델을 두 개의 각기의 nuimodally pre-trained 인코더를 사용하여 초기화하거나, 맨 처음부터 학습을 할 때는 랜덤하게 초기화하였다. 논문에서는 pre-training을 위해 항상 multi-modal encoder를 랜덤하게 초기화하였다.
Joint unimodal and multimodal training. 이미지 & 텍스트 인코더의 unimodal pre-training 후에 round-robin 샘플링을 사용하여 3개의 유형의 데이터셋에서 공동으로 전체 FLAVA 모델 학습을 계속하였다. 각 학습 반복에서 경험적으로 결정한 샘플링 비율에 따라 데이터셋 중 하나를 선택하고 샘플 배치를 얻는다. 그 다음에 데이터셋 유형에 의존해서, unimodal MIM을 이미지 데이터에, unimodal MLM을 텍스트 데이터에, multimodal loss를 image-text 쌍에 적용하였다.
3-4. Data: Prublic Multimodal Datasets(PMD)
multi-modal pre-training을 위해 논문에서는 image-text 데이터의 대중에 공개된 소스의 corpus로 구성되었다. 전체 text-image 쌍의 수는 70M 정도이다.
4. Experiments
논문에서는 FLAVA를 vision, language, multi-modal task에서 평가하였다. 각 능력들을 위해 평가한 task는 다음과 같다.
- vision tasks: 22 common vision tasks
- NLP tasks: GLUE 벤치마크의 8개의 tasks
- multi-modal tasks: VQAv2, SNLI-VE, Hateful Memes, Flickr30K, COCO
논문에서는 다른 세팅을 사용한 공동 pre-training method와 다양한 35개의 task에서 비교하였다. 이를 위해 NLP, vision, multi-modal task에 대한 평균 점수를 기록하고, 추가적인 macro average를 3개의 modality를 표 2에서 비교하였고, 각 task에 대한 자세한 성능을 표 3에 기록하였다.
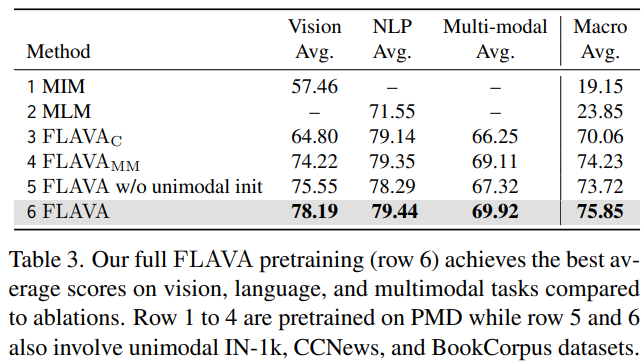
Full FLAVA pre-training achieves the best results. 표 2에서는 baseline과 서로 다른 ablation 세팅의 FLAVA를 보여주고 있다: unimodal MIM과 MLM loss만을 사용해서 학습된 모델, image-text contrastive loss에서만 학습된 FLAVA_C, multi-=modal 데이터에서 unimodal 초기화없이 학습된 FLAVA_MM, 그리고 full model. 위 표 2의 6행을 보면 full FLAVA model이 다른 모든 세팅의 평균 스코어를 능가하는 모습을 확인할 수 있다.
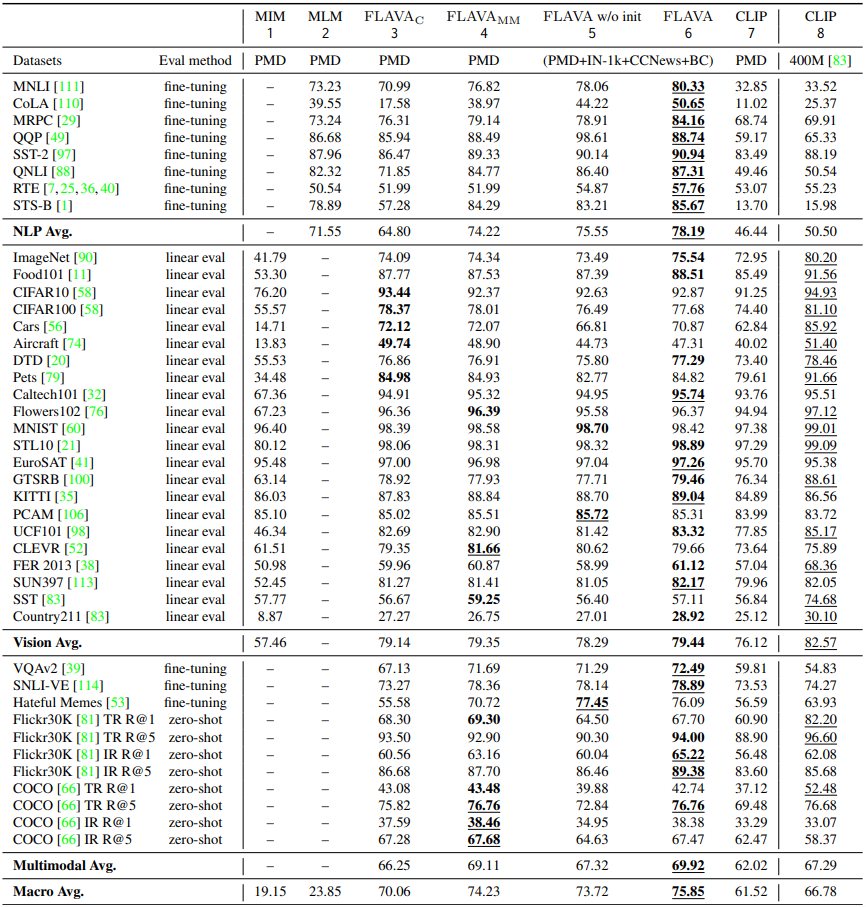
Effective global contrastive loss in FLAVA. 이제는 FLAVA의 step-by-step ablation을 수행할 것이다(표 3). 논문에서는 처음에 오직 global contrastive loss $L_{GC}$만을 사용해서 FLAVA의 제한된 버전을 multi-modal 데이터에서 학습시켰고, 이것을 3열의 $FLAVA_{C}$로 나타내었다. 이러한 제한된 세팅은 CLIP과 유사한데, 논문에서는 똑같은 PMD 데이터에서 학습된 CLIP과 $FLAVA_{C}$를 비교하였다. (표 2의 3열과 7열 비교) 그 결과를 살펴보면 $FLAVA_{C}$가 vision, language, multi-modal 도메인에서 모두 더 뛰어난 성능을 보여주는 것을 알 수 있다. 이는 다음의 2개의 요인 덕분이다:
- FLAVA의 서로 다른 모델 디테일
- global back-propagation을 모든 GPU worker에 대해 수행
MMM & ITM objective benefit multimodal tasks. 다음으로는 다른 multimodal objectives인 $L_{MMM}$과 $L_{ITM}$을 $L_{GC}$와 함께 사용해보았다. 그 결과는 표 3의 4열에 $FLAVA_{MM}$으로 나타나있다. 오직 contrastive loss만 사용한 $FLAVA_{C}$(3열 vs. 4열)와 비교해보면, 이 세팅은 더 뛰어난 성능을 보여준다.
추가적으로 $FLAVA_{MM}$을 다른 두 baseline 세팅과 비교하였다 - 오직 unimodal MIM 또는 MLM loss를 사용해서 학습한 FLAVA 모델. 이 두 baseline은 표 3의 1열과 2열에 나타나 있다. 이것을 보면 이 baseline들이 $FLAVA_{MM}$보다 성능이 훨씬 더 뛰어난 것을 알 수 있다. 이 결과들은 종합 multimodal objectives(contrastive, MMM, ITM)이 FLAVA가 unimodal & multimodal downstream task에 대해 강력한 representation을 학습하도록 허락해준다는 것을 알 수 있다.
Joint unimodal & multimodal pre-training helps NLP. full FLAVA pre-training을 위해, 논문에서는 ImageNet-1k로부터 unimodal 데이터를 소개하였고, CCNews와 BookCorpus로부터 텍스트 데이터를 소개하였다. 이 세팅에서 적용된 loss는 다음과 같다(표 3의 5열).
- $FLAVA_{MM}$ loss: PMD 데이터 배치에 적용
- MIM loss: IN-1k unimodal 이미지 데이터에 적용
- MLM loss: CCNews 텍스트 데이터에 적용
이것을 multi-modal pre-training만 있는 4열의 $FLAVA_{MM}$과 비교하면, 이 공동 unimodal & multimodal pre-training은 NLP 평균 스코어를 향상시킨다. 이것은 CCNews와 BookCorpus로부터의 추가적인 데이터는 MLM objective를 통해 language understanding에 이익을 준다는 것을 제안한다.
하지만 4열과 5열과의 비교에서 모든 task에 대한 macro 평균 점수가 살짝 감소했다는 것 또한 관찰할 수 있었다. 논문에서는 이것이 서로 다른 task를 추가해서 섞은 것이 특히 전체 모델이 랜덤하게 초기화 될 때 최적화 문제를 더욱 어렵게 만드는 것으로 추측하였다. 따라서 multimodal task를 학습하기 전에 vision & language understanding을 가지고 있는 것이 중요하다. 이것은 이 논문으로 하게끔 처음으로 unimodal pre-training을 공동 학습 전에 활용하게 만들었다.
Better image & text encoder via unimodal pre-training. 공동 학습 이전에 unimodal 학습을 활용하기 위해, 논문에서는 vision & language encoder에 대한 pre-trained self-supervised 가중치로부터 모델을 초기화하였다. 표 3의 5열과 6열을 비교하면, pre-trained encoder가 FLAVA의 성능을 모든 task에 대해서 향상시키는 것을 확인할 수 있다.
4-1. Comparison to state-of-the-art models
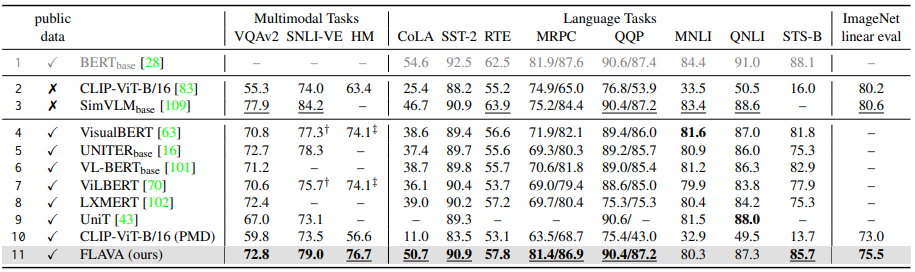
논문에서는 full FLAVA 모델(표 3의 6열)을 여러 SoTA 모델들과 multimodal task, language task, ImageNet 선형 평가에서 비교하였다. 표 4를 보면 FLAVA는 language 및 multi-modal task 모두에서 공개 데이터(4행에서 11행)로 pre-train된 이전의 multi-modal 방식과 잘 확립된 BERT 모델보다 크게 능가하며 여러 GLUE 작업에서 좋은 성능을 보여줬다.
FLAVA는 unimodal loss와 multi-modal loss를 합치고 vision, language, multi-modal task로 전이될 수 있는 더욱 일반적인 representation을 학습하였다. 논문에서는 가장 좋은 성능의 400M image-text 쌍을 사용하고, FLAVA와 똑같은 이미지 인코더인 ViT-B/16을 사용한 CLIP과 task 벤치마크에서 비교하였다. (표 4의 2행) CLIP과 비교하여 FLAVA는 6배 더 적은 70M 데이터에서 학습하였다. 그림 3을 보면 FLAVA가 language & multi-modal task에서 살짝 더 나은 성능을 보여주는 반면, 몇 개의 vision-only task에서는 CLIP보다 살짝 떨어지는 성능을 보여주는 것을 알 수 있다. 추가적으로 FLAVA는 오직 PMD 데이터셋에서 pre-train된 CLIP model의 변형을 능가하는 성능을 보여줬다 (표 4의 10행).
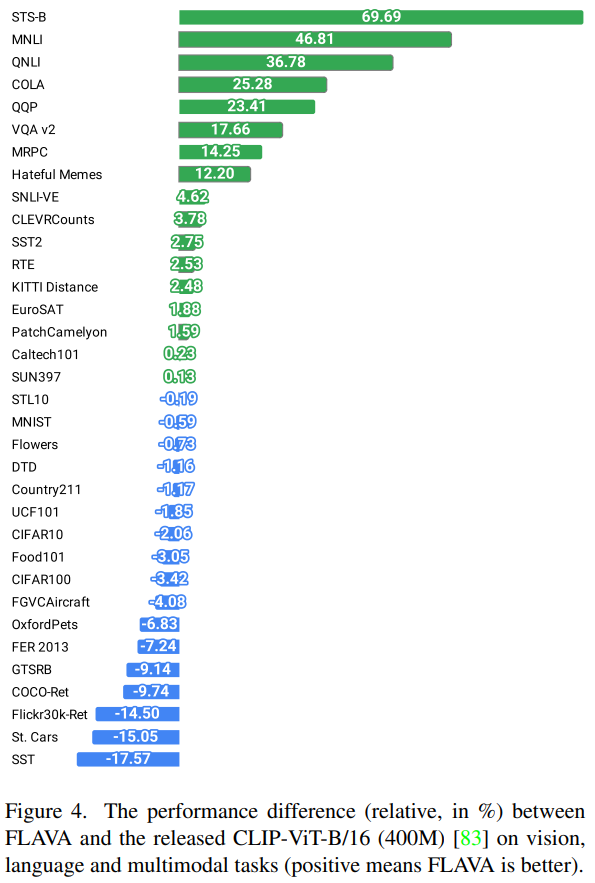
FLAVA는 language task에서 SimVLM(표 4의 3행)과 비슷한 성능을 보여주는 반면, multi-modal task와 ImageNet 선형 평가에서는 살짝 떨어지는 성능을 보여줬다. FLAVA는 1.8B image-text 쌍에 비해 훨씬 작은 데이터셋을 사용하고 FLAVA의 성능은 pre-training 데이터셋의 사이즈가 증가하게 되면 더욱 증가할 것이라고 예상된다.
출처