
논문 리뷰를 시작하기 전에 이번 논문 리뷰는 full paper를 읽고 작성하는 리뷰가 아니라는 점 감안하길 바란다. 원래는 full paper를 읽어보려고 하였으나, 이 논문에서 소개하고자 하는 것이 딱히 새로운 기술의 소개가 아닌 더 나은 모델을 사용하여 더 나은 결과를 얻어냈다고 생각하여 Microsoft Blog를 참고하여 작성하였다.
The overview of this paper
이 논문에서는 vision language(VL) task에 대한 visual representation을 향상시키는 디테일한 연구를 진행하고 이미지에서 object 중심의 representation을 제공하기 위한 개선된 object detection model을 개발하였다. 주로 사용되는 모델들과 비교하여 논문에서 소개하는 모델은 더욱 크고, VL task에 대해 더욱 잘 디자인 되어 있고, 다양한 공공 annotated object detection 데이터셋을 합친 더욱 큰 training corpora에서 pre-train 되었다. 따라서 이 모델은 더욱 풍부한 visual object와 concept의 모음의 representation을 생성할 수 있다. 반면에 이전의 VL 연구들은 vision-language 모델을 향상시키는데만 집중하고 object detection 모델의 개선은 건들지 않아서, 이 논문에서는 VL 모델에서 visual feature가 얼마나 상당한 영향을 미치는지 보여줬다. 논문의 실험에서는 새로운 object detection 모델로부터 생성된 visual feature를 Transformer 기반 VL model인 OSCAR에 넣고, VL model을 pre-train 하고 다양한 downstream VL task에서 fine-tune 하기 위해 더 개선된 방법인 OSCAR+를 사용하였다.
Introduction
그림 1에서 묘사되어 있는 것처럼, 기존의 VL system은 VL understanding을 위해 2개의 모듈을 사용하는 modular architecture을 사용한다.
- Image encoding module: visual feature extractor로 알려져 있는 것처럼, 입력 이미지의 feature map 생성을 위해 CNN을 사용해서 구현한다. Fast-RCNN을 사용하는 것이 보편적이다.
- Vision-language fusion module: 인코딩된 이미지와 텍스트를 똑같은 semantic space로 매핑해서 이들의 semantic 유사도는 이 벡터들 간의 코사인 거리를 사용해서 계산된다. 보통 OSCAR 같은 Transformer 기반의 모델을 사용하여 구현된다.
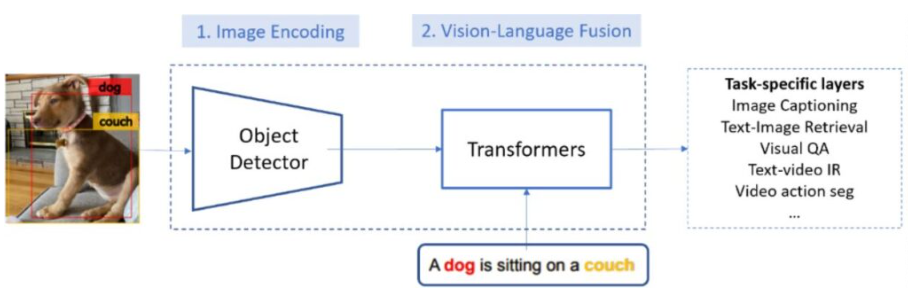
최근의 vision-language pre-training(VLP)는 대규모의 image-text 쌍 corpus에서 pre-training 함으로써 vision-language fusion module을 향상시키는 것에 대해 큰 발전을 이룩하였다. 이때 가장 전형적인 방법은 거대한 Transformer 기반 모델을 방대한 image-text 쌍 데이터에서 학습시키는 것이다. pre-trained vision-language fusion model 또한 다양한 downstream vision-language task에 적용하기 위해 fine-tune 될 수 있다. 하지만, 기존의 VLP method들은 image encoding module을 블랙박스로 두고 visual feature 개선은 건드리지 않았다. 더 나은 기술을 사용할 수 있었음에도 2017년에 개발된 기술을 아직까지 사용하고 있던 것이다.
여기서, 논문에서는 image encoding 모듈을 향상시키기 위한 연구를 소개하였다. 논문에서는 이미지 인코딩을 위한 새로운 object-attribute detection model인 VinVL(Visual features in Vision-Language)을 소개하였다. 이 VinVL을 SoTA 모델인 OSCAR와 VIVO와 합치니, 7개의 주요한 VL 벤치마크에서 상위 포지션을 차지할 수 있었다.
VinVL: A generic object-attribute detection model
object detection 같은 일반적인 computer vision task와 달리, VL task는 더욱 다양한 visual concept에 대한 이해와 text modality에서 해당하는 conmcept와의 정렬을 필요로 한다. 대부분의 object detection 벤치마크는 600개 이상의 objec class에 대한 annotation을 포함하고 있다. 이 클래스들은 잘 정의된 모양의 object에 주로 집중하지만, 이미지를 묘사하는데 유용한 무정형의 영역들에 대해서는 놓쳐버린다. 제한되고 편향적인 object class는 이러한 object detection 데이터셋이 실세계 활용에 매우 유용한 VL understanding 모델을 학습시키는데 불충분하다는 것을 보여준다.
Dataset. 논문에서는 VL task를 위한 object-attribute detection 모델을 학습시키기 위해, 4개의 공공 object detection 데이터셋(COCO, Open Images, Object365, VG)을 합쳐서 1,848개의 object class와 524개의 attribute class에 대한 2.49M 개의 이미지를 포함하는 거대한 object detection 데이터셋을 만들었다. 논문에서도 object-attribute detection 모델을 만들기 위해 pre-training & fine-tuning 전략을 사용하였다.
- 합쳐진 데이터셋에서 object detection 모델을 pre-train 시킴
- VG에서 추가적 attribute branch를 사용해서 모델을 fine-tune. 이는 object와 attribute 둘 다 감지할 수 있게 해줌.
그 결과로 얻어진 object-attribute detection 모델이 152개의 convolutional layer와 133M개의 파라미터를 사용하는 Faster-RCNN 모델인 'ResNeXt-152 C4'이다.
논문의 object-attribute detection 모델은 1,594개의 object class와 524개의 visual attribute를 감지할 수 있다. 그 결과 모델은 입력 이미지에서 거의 모든 의미를 가지는 영역을 감지하고 인코딩할 수 있었다. 그림 2에 묘사되어 있는 것처럼, 일반적인 object detection 모델보다 논문의 모델이 훨씬 더 많은 visual object와 attribute를 감지하고 더 풍부한 visual feature을 사용하여 이들을 인코딩할 수 있다. 이는 광범위한 VL task에서 매우 중요하다.

OSCAR+
논문에서는 image-text 정렬에 대한 anchor로 image tag를 사용해서 공동 image-text representation을 학습하기 위해 OSCAR의 개선된 버전이 OSCAR+를 pre-train 해서 사용하였다. OSCAR+의 pre-training objective로는 Masked Token Loss와 기존 OSCAR의 binary contrastive loss에서 조금 달라진 3-way Contrastive Loss를 사용하였다. 다음의 수식은 OSCAR+의 pre-training loss이다.
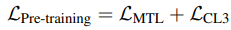
위의 수식에서 $\mathfrak{L}_{MTL}$은 Masked Token Loss이고, $\mathfrak{L}_{CL3}$은 3-way Contrastive Loss이다. 먼저 3-way contrastive loss부터 살펴보면 아래의 수식과 $\mathfrak{L}_{CL3}$는 이미지 캡션 및 이미지 태깅 데이터의 {caption, image-tags, image-features} 삼중항과 VQA 데이터의 {question, answer, image-features} 삼중항의 두 가지 유형의 학습 샘플 $textbf{x}$를 고려한다.
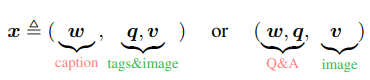
contrastive loss를 계산하기 위해, negative example이 만들어져야 할 필요가 있다. 논문에서는 학습 샘플의 두 가지 유형에 대한 두 가지 유형의 negative(일치하지 않는) 삼중항을 만들었다. 하나는 '오염된(polluted)' 캡션 $(\textbf{w}', \textbf{q}, \textbf{v})$이고, 다른 하나는 '오염된' 대답 $(\textbf{w}, \textbf{q}', \textbf{v})$이다. 이를 이용해서 수행하는 task는 다음과 같다.
- text-image matching: caption-tag-image 삼중항이 오염된 캡션을 포함하는지 분류
- VQA의 대답 선택: question-answer-image 삼중항이 오염된 대답을 포함하는지 분류
[CLS]의 인코딩이 삼중항 $(\textbf{w}, \textbf{q}, \textbf{v})$의 representation으로 보이기 때문에 그 위에 fully-connected(FC) 레이어를 3-way classifier $f(.)$로 적용하여 삼중항이 일치하는지$(c = 0)$, 오염된 $\textbf{w}$를 포함하는지$(c = 1)$ 또는 오염된 $\textbf{q}$ $(c = 2)$을 포함하는지 예측한다. 3-way contrastive loss는 다음과 같이 정의된다.
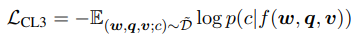
Comparison with SoTA Models on Vision-Language Tasks
VL system에서 이미지 인코딩 모듈은 fundamental이기 때문에, 그림 1에서 묘사되어 있는 것처럼, VL task에서의 성능을 향상시키기 위해 논문의 새로운 이미지 인코딩은 기존의 VL fusion module들과 함께 사용될 수 있다. 예를 들어서 표 1에 나와있는 것처럼 인기 있는 bottom-up 모델에서 생성된 visual feature를 논문의 모델에서 생성된 visual feature으로 간단히 대체하지만 VL fusion model(OSCAR 및 VIVO)을 그대로 유지함으로써 논문에서는 7가지 VL task 모두에서 상당한 개선을 보여줬다. 그리고 이전 SoTA 모델보다 상당히 큰 차이가 있었다. 심지어는 VinVL base model이 이전의 large model을 능가하는 성능을 보여줬다. 이는 더 나은 이미지 인코딩을 사용하면 VL fusion module은 더욱 파라미터 효율적이라는 것을 보여준다.

출처
VinVL: Advancing the state of the art for vision-language models - Microsoft Research
VinVL: Advancing the state of the art for vision-language models - Microsoft Research
Humans understand the world by perceiving and fusing information from multiple channels, such as images viewed by the eyes, voices heard by the ears, and other forms of sensory input. One of the core aspirations in AI is to develop algorithms that endow co
www.microsoft.com
https://arxiv.org/abs/2101.00529
VinVL: Revisiting Visual Representations in Vision-Language Models
This paper presents a detailed study of improving visual representations for vision language (VL) tasks and develops an improved object detection model to provide object-centric representations of images. Compared to the most widely used \emph{bottom-up an
arxiv.org
VinVL: Revisiting Visual Representations in Vision-Language Models
This paper presents a detailed study of improving visual representations for vision language (VL) tasks and develops an improved object detection model to provide object-centric representations of images. Compared to the most widely used \emph{bottom-up an
arxiv.org