
The overview of this paper
논문에서는 modular Transformer를 사용해서 dual encoder와 fusion encoder를 공동으로 학습하는 통합 Vision-Language pretrained Model(VLMO)를 소개하였다. 특히 논문에서는 Mixture-of-Modality-Experts(MoME) Transformer를 소개하였는데, 이것의 각 블록은 modality-specific 한 전문가와 공유된 self-attention layer를 가진다. MoME의 모델링 유연성 덕분에, pretrained VLMo는 vision-language 분류 task를 위해 fusion encoder로 fine-tune 될 수도 있고, 효율적인 image-text retrieval을 위해 dual encoder로 사용될 수도 있다. 게다가, 논문에서는 대규모 image-pnly & text-only image-text 쌍을 효과적으로 활용할 수 있게 해주는 stagewise pre-training 전략을 제안하였다.
Table of Contents
1. Introduction
2. Methods
2-1. Input Representations
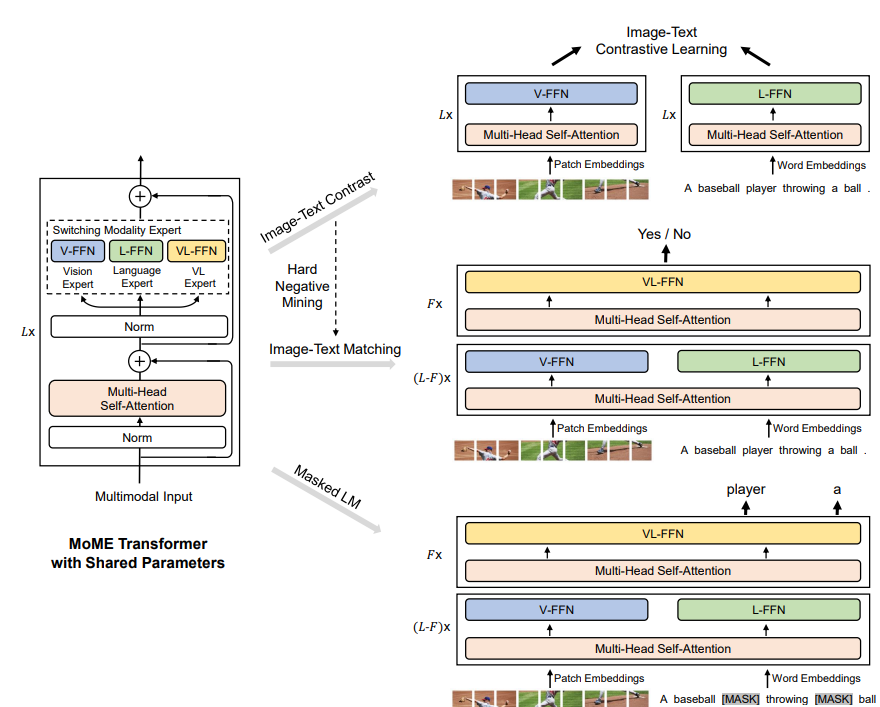
2-2. Mixture-of-Modality-Experts Transformer
2-3. Pre-training Tasks
2-4. Stagewise Pre-training
2-5. Fine-Tuning VLMo on Downstream Tasks
3. Experiments
1. Introduction
Vision-Language(VL) pre-training에서는 2개의 주된 아키텍처가 사용되었다.
- dual encoder: 이미지와 텍스트를 따로따로 인코딩. modality 상호작용은 이미지와 텍스트 벡터의 코사인 유사도에 의해 조정됨. retrieval task에 효과적 & 얕은 상호작용으로 인해 복잡한 VL 분류 task에는 부적합
- fusion encoder: image-text 쌍을 모델링하기 위해 cross-modal attention을 사용. 다층 Transformer는 image & text representation을 융합하기 위해 사용. retrieval task를 위해 모든 가능한 image-text 쌍간에 코사인 유사도를 계산해야 하므로 더 많은 시간 복잡도와 느린 추론 속도를 가짐.
이 두 가지 유형의 아키텍처의 장점을 누리기 위해, 논문에서는 dual encoder & fusion encoder를 각 task를 위해 사용 가능한 Vision-Language pretrained Model(VLMo)를 제안하였다. 이는 다양한 modality(image, text, image-text pairs)를 Transformer 블록에서 인코딩할 수 있는 Mixture-of-Modality-Experts의 소개로 인해 가능해졌다. MoME는 기존 Transformer에서 feed-forward network(FFN)을 대체하기 위한 modality expert의 모임을 사용하였다. MoME는 서로 다른 modality expert 간에 스위치를 해서 modality-specific 정보를 얻을 수 있고, 공유된 self-attention을 modality 간에 사용해서 visual & linguistic 정보를 정렬할 수 있다. 이러한 MoME Transformer는 다음의 3가지 expert로 구성되어 있다. 그리고 MoME Transformer의 모델링 유연성 덕분에 서로 다른 목적에 대한 공유된 파라미터와 함께 MoME Transformer를 재사용할 수 있다.
- vision expert: image encoding을 수행
- language expert: text encoding을 수행
- vision-language expert: image-text fusion을 수행
VLMo는 3개의 pre-training task를 사용하여 공동으로 학습되었다: image-text contrastive learning(ITC), image-text matching(ITM), masked language modeling(MLM). 게다가 논문에서는 VLMo pre-training에서 대규모 image-only & text-only corpus & image-text 쌍을 효과적으로 활용하는 stagewise pre-training 전략을 제안하였다. stagewise pre-training 전략의 과정은 다음과 같다.
- vision expert & MoME Transformer의 self-attention을 image-only 데이터에서 MIM을 사용하여 pre-train
- language expert를 text-only 데이터에서 MLM을 사용하여 pre-train
최종적으로 모델은 vision-language pre-training을 초기화하기 위해 사용된다. image-text 쌍의 제한된 크기와 이들의 간단하고 짧은 캡션을 제거함으로써, 대규모의 image-only & text-only 데이터에서 stagewise pre-training은 VLMo가 더욱 일반적인 representation을 학습하도록 도와준다.
논문의 주된 contribution을 요약하면 다음과 같다.
- 분류 task를 위해 fusion encoder가 되기도 하고, retrieval task를 위해 dual encoder로 fine-tune되는 통합 vision-language pre-trained model인 VLMo를 제안 ✨
- general-purpose multi-modal Transformer인 서로 다른 modality를 인코딩하기 위한 MoME Transformer를 소개 ✨
- 대규모의 image-only & text-only 데이터를 사용하는 stagewise pre-training을 보여줌 ➡️ vision-language pre-trained model의 성능을 크게 향상시킴
2. Methods
image-text 쌍이 주어지면, VLMo는 MoME Transformer 네트워크로부터 image-only, text-only, image-text 쌍 representation을 얻게 된다. 그림 1에서 보이는 것처럼 통합 pre-training은 공유된 MoME Transformer를 image-only & text-only representation에서 ITC를 사용하여 최적화하고, image-text representation에서는 ITM을 사용하여 최적화한다. VLMo의 모델링 유연성 덕분에 다음과 같은 작업이 가능하다.
- dual encoder로 사용: retrieval task를 위해 fine-tuning 중에 이미지와 텍스트를 개별적으로 인코딩
- fusion encoder로 사용: 분류 task를 위해 이미지와 텍스트의 더 깊은 상호작용을 모델링
2-1. Input Representations
image-text 쌍이 주어지면, 논문에서는 이 쌍을 이미지, 텍스트, image-text 쌍 representation으로 인코딩한다. 이러한 representation들은 문맥화된 representation을 학습하고 이미지 feature vecotr와 텍스트 feature vecotr를 정렬하기 위해 MoME Transformer에 들어가게 된다.
Image Representations vision Transformer의 방식을 따라서 이미지를 패치화해서 벡터로 flatten 하고 linear projection을 사용해서 패치 임베딩을 얻었다. 그리고 패치 임베딩 앞에 학습 가능한 스페셜 토큰 [I_CLS]를 추가하였다. 마지막으로 패치 임베딩과 학습 가능한 1D position embedding과 image type embedding을 추가해서 가능과 같은 image input representation을 얻게 된다.
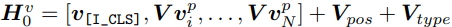
Text Representations BERT를 따라서 WordPiece tokenizer를 사용해서 텍스트를 subword로 토큰화하였다. 시퀀스의 시작을 알려주는 토큰 [T_CLS]와 스페셜 경계 토큰 [T_SEP]를 텍스트 시퀀스에 추가하였다. text input representation은 word embedding과 text position embedding, text type embedding을 합쳐서 다음과 같이 나온다.
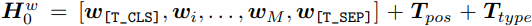
Image-Text Representations 논문에서는 image-text input representation $\textbf{H}_{0}^{vl} = [\textbf{H}_{0}^{w};\textbf{H}_{0}^{v}]$을 형성하기 위해 이미지 입력 벡터와 텍스트 입력 벡터를 연결하였다.
2-2. Mixture-of-Modality-Experts Transformer
논문에서는 vision-language task를 위한 general-purpose multi-modal Transformer인 MoME Transformer를 제안하였다. MoME Transformer는 modality expert의 모음을 기존 Transformer의 feed forward network(FFN)을 대체하기 위해 소개하였다. 이전 레이어의 출력 벡터 $\textbf{H}_{L-1}, l \in [1, L]$이 주어지면, 각각의 expert는 visual & linguistic contents를 정렬하기 위해 multi-head self-attention(MSA)를 modality 간에 사용하였다. 아래 수식에서 LN은 layer normalization의 약자이다. 그림 1의 MoME Transformer의 구조를 보면서 수식을 보면 이해하기 쉽다.
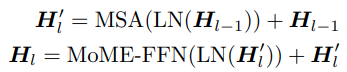
MoME-FFN은 입력 벡터 $\textbf{H}_{l}^{'}$의 modality에 해당하는 입력과 Transformer layer의 인덱스를 처리하기 위해 여러 modality expert 중에서 expert를 선택한다. 여기에는 3개의 modality expert가 있다: vision expert(V-FFN), language expert(L-FFN), vision-language expert(VL-FFN). 상황에 따라서 다른 expert가 사용되는데 그 상황은 다음과 같다.
- 입력이 image-only 또는 text-only 벡터로 이루어져 있으면 ➡️ 이미지 인코딩을 위해 vision expert 사용 또는 텍스트 인코딩을 위해 text expert 사용
- 입력이 여러 modality(image-text 쌍)의 벡터로 이루어져 있으면 ➡️ Transformer layer의 바닥 쪽에서 각각의 modality 벡터를 인코딩하기 위해 vision expert와 text expert 사용. 그다음에 vision-language expert는 위쪽 레이어에서 사용돼서 더 많은 modality 상호작용을 캡처함.
3가지 유형의 입력 벡터가 들어오면, image-only, text-only, image-text 쌍의 문맥화된 representation을 얻게 된다.
2-3. Pre-training Tasks
VLMo는 이미지와 텍스트 representation에서 ITC를 통해, 공유된 파라미터를 사용하는 image-text 쌍 representation에서 MLM과 ITM을 통해 공동으로 pre-train 된다.
VLMo에 사용되는 pre-training task인 ITC, MLM, ITM의 방식은 기존의 방식과 똑같다. 이중에 ITM에서는 기존과 살짝 다른 방식을 사용하였는데, 기존에는 단일 GPU에서 hard negative 샘플을 사용한 반면에, 논문에서는 global hard negative mining을 제안하고 모든 GPU로부터 모여진 더욱 많은 training example로부터 hard negative image-text 쌍을 샘플링하였다. global hard negative mining은 더욱 정보적인 image-text 쌍을 찾을 수 있고 더욱 향상된 모델을 얻을 수 있게 해 준다.
2-4. Stagewise Pre-training
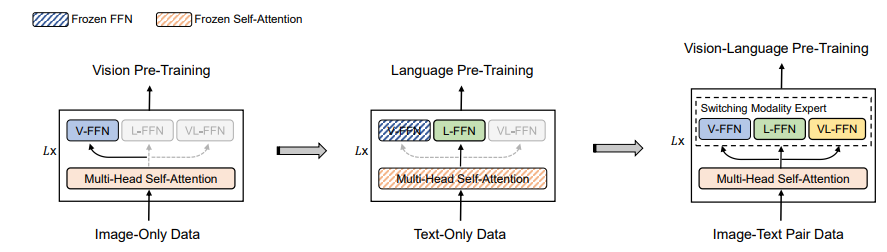
논문에서는 vision-language 모델을 향상시키기 위해 대규모 image-only & text-only corpus를 활용하는 stagewise pre-training을 소개하였다. 그림 2에서 보이는 것처럼, 논문에서는 처음에 image-only 데이터에서 vision pre-training을 수행하고, 그다음에 image & text representation을 학습하기 위해 text-only 데이터에서 language pre-training을 수행하였다. 모델은 visual & linguistic 정보의 정렬을 학습하기 위해 vision-language pre-training을 초기화하기 위해 사용된다. vision pre-training을 위해 MoME Transformer의 vision expert와 attention module을 BEIT로 image-only 데이터에서 학습시켰다. 논문에서는 attention module과 vision expert를 초기화하기 위해 pre-train 된 BEIT의 파라미터를 활용하였다. language pre-training을 위해서, attention module의 파라미터와 vision expert를 동결시켜 놓고 text-only 데이터에서 language expert를 최적화하기 위해 MLM을 활용하였다. image-text 쌍과 비교하여 text-only 데이터는 수집하기 더 쉽다. 게다가, image-text 쌍의 텍스트 데이터는 대게 짧거나 간단하다. 그래서 image-only와 text-only corpus에서 pre-training을 하면 복잡한 쌍에서의 일반화를 향상시켜준다.
2-5 Fine-tuning VLMo on Downstream Tasks
그림 3에 나타나 있는 것처럼, 논문의 모델은 다양한 vision-language retrieval과 분류 task에 적응하기 위해 fine-tune 될 수 있다.
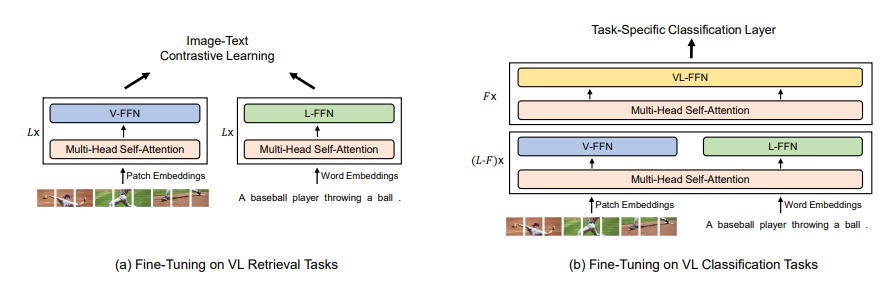
VIsion-Language Classification VQA나 visual reasoning과 같은 분류 task에 대해, VLMo는 이미지와 텍스트의 modality 상호작용을 모델링하기 위해 fusion encoder처럼 사용된다. 논문에서는 토큰 [T_CLS]의 최종 인코딩 벡터를 image-text 쌍의 representation으로 사용하고, 이를 task-specific 분류기 레이어에 넣어서 라벨을 예측한다.
Vision-Language Retrieval retrieval task에 대해, VLMo는 이미지와 텍스트를 따로따로 인코딩하기 위해 dual encoder처럼 사용될 수 있다. fine-tuning 중에 VLMo는 ITC loss에 대해 최적화된다. 추론 중에는 모든 이미지와 텍스트의 representation을 계산하고, 그다음에 모든 가능한 image-text 쌍의 image-to-text & text-to-image 유사도 스코어를 얻기 위해 내적을 사용한다. 각각의 인코딩은 fusion-encoder-based model보다 더 빠른 추론 속도를 가능하게 한다.
3. Experiments
논문에서는 VLMo를 대규모 image-text 쌍을 사용하여 pre-train 하고 visual-linguistic classification & retrieval task에서 평가하였다. 사용된 pre-training 데이터로는 총 4개의 image captioning 데이터셋이 사용되었다: Conceptual Captions(CC), SBU Captions, COCO, VIsual Genome(VG).
3-1. Training on Larget-scale Datasets
논문에서는 VLMo-Large를 큰 배치 사이즈를 사용하는 10억 개의 noisy web image-text 쌍에서 학습함으로써 vision-language representation learning의 규모를 늘렸다.
3-2. Evaluation on Vision-Language Classification Tasks
논문에서는 두 개의 널리 사용되는 분류 데이터셋에서 fine-tuning 실험을 진행하였다: VQA & NLVR2. 모델은 더 깊은 상호작용을 위해 fusion encoder로 fine-tune 되었다. 각 task에 대한 설명은 생략하고 VLMo에서 사용된 방법에 대해 자세하게 다루도록 하겠다.
Visual Question Answering(VQA) [I_CLS] 토큰의 최종 인코딩 벡터를 image-question 쌍의 representation으로 사용하고, 이를 분류기 레이어에 넣어서 answer를 예측하게 한다.
Natural Language for Visual Reasoning(NLVR2) 2 입력 쌍의 [T_CLS] 토큰의 최종 출력 벡터를 연결한다. 연결된 벡터는 분류기 레이어에 들어가서 라벨을 예측한다.
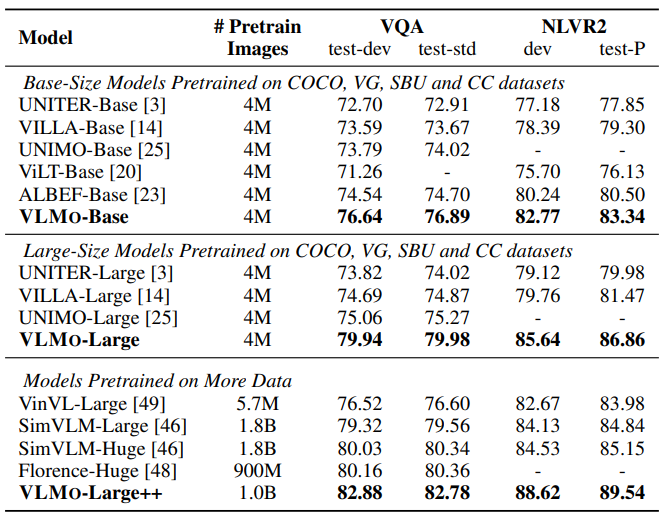
표 1에서는 VL classification task의 결과를 보여주고 있다. VLMo는 SoTA를 달성하고 이전 모델보다 상당히 향상된 성능을 보여주고 있다. 특히 더 많은 파라미터와 데이터로 학습된 모델들보다 더 나은 성능들을 보여주고 있다. 그리고 VLMo는 이미지를 임베딩하기 위해 간단한 linear projection을 사용함으로써 이전의 모델들보다 상당히 빨라진 속도를 보여주고 있다.
3-3. Evaluation on Vision-Language Retrieval Tasks
retrieval task는 image-to-text retrieval과 text-to-image retrieval를 포함하고 있다. 논문에서는 VLMo를 널리 사용되는 COCO와 Flickr30k에서 평가하고, 두 데이터셋에 대해 Karpathy 분할을 사용하였다. VLMo는 retrieval task를 위해 dual encoder로 사용되었다. 논문에서는 이미지와 텍스트를 따로따로 인코딩하고 이들의 유사도 스코어를 이미지 벡터와 텍스트 벡터의 내적으로 계산하였다.
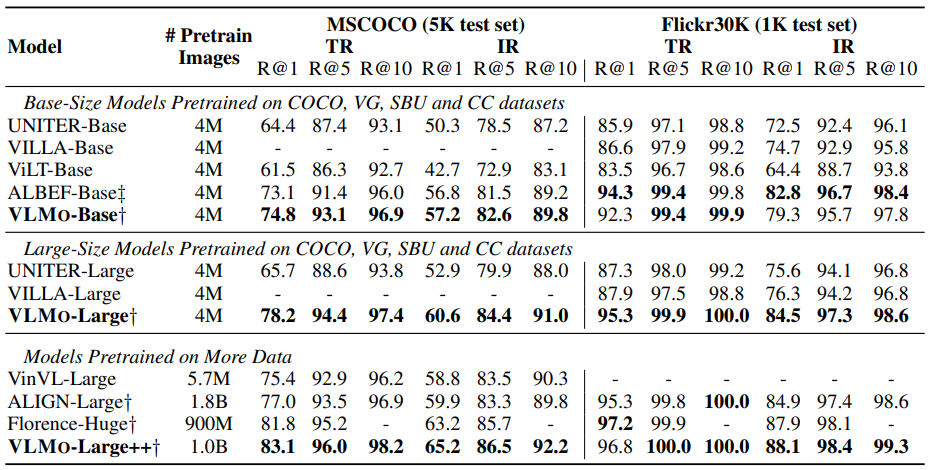
표 2에 나타나 있는 것처럼, VLMo는 이전의 fusion-encoder-based 모델과 견줄 만한 성능을 보여주는 반면 더 빠른 속도를 자랑하였다. fusion-encoder-based 모델은 모든 가능한 image-text 쌍을 유사도 스코어를 계산하기 위해 인코딩해야 해서 더 많은 시간 복잡도를 필요로 한다. 게다가, VLMo large-size model은 더 큰 배치 사이즈를 사용하는 더 많은 데이터에서 학습된 모델보다 좋은 성능을 보여줬다. VLMo pre-training은 효과적으로 대규모 noisy 쌍을 활용할 수 있고 거대한 batch training에서 이익을 볼 수 있다.
3-4. Evaluation on Vision Tasks
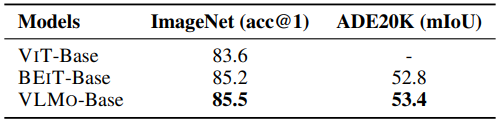
표 3에서 보이는 것처럼, 논문에서는 VLMo를 image-only encoder로 사용해서 이미지 분류(ImageNet)와 semantic segmentation(ADE20K) task에서 평가하였다. VLMo는 유망한 성능을 보여줬고, BEIT보다 살짝 나은 성능을 보여줬다.
3-5. Ablation Studies
Stagewise Pre-training 표 4를 보면 알 수 있듯이, image-only pre-training + text-only pre-training은 vision-language model의 성능을 향상시켰다. stagewise pre-training은 대규모 image-only & text-only corpus를 효과적으로 활용하고, vision-language pre-training을 향상시킨다.

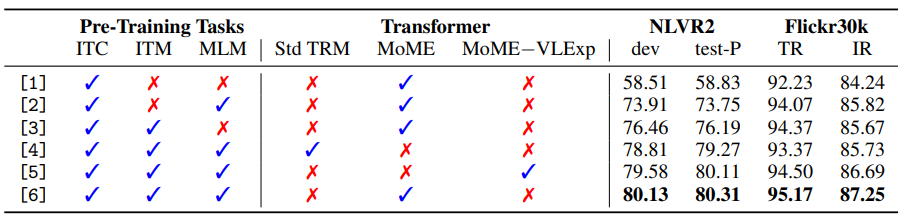
MoME Transformer 표 5에 나타나 있는 것처럼 MoME Transformer를 사용하면 retrieval & 분류 task에서 기존의 Transformer보다 더 나은 성능을 보여준다. 그리고 VL-FFN 또한 성능 향상에 도움을 준다. 추가적으로 MoME Transformer에서 사용되는 공유된 self-attention 모듈은 모델에 도움을 준다.
Global Hard Negative Mining ALBEF와 달리 VLMo는 모든 GPU의 학습 예시를 모음으로써 더 많은 후보자로부터 hard negative mining을 수행한다. 표 6에서 보이는 것처럼 global hard negative mining은 상당한 성능 향상을 불러온다.

출처
https://arxiv.org/abs/2111.02358
VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
We present a unified Vision-Language pretrained Model (VLMo) that jointly learns a dual encoder and a fusion encoder with a modular Transformer network. Specifically, we introduce Mixture-of-Modality-Experts (MoME) Transformer, where each block contains a
arxiv.org
'Paper Reading 📜 > multimodal models' 카테고리의 다른 글
The overview of this paper
논문에서는 modular Transformer를 사용해서 dual encoder와 fusion encoder를 공동으로 학습하는 통합 Vision-Language pretrained Model(VLMO)를 소개하였다. 특히 논문에서는 Mixture-of-Modality-Experts(MoME) Transformer를 소개하였는데, 이것의 각 블록은 modality-specific 한 전문가와 공유된 self-attention layer를 가진다. MoME의 모델링 유연성 덕분에, pretrained VLMo는 vision-language 분류 task를 위해 fusion encoder로 fine-tune 될 수도 있고, 효율적인 image-text retrieval을 위해 dual encoder로 사용될 수도 있다. 게다가, 논문에서는 대규모 image-pnly & text-only image-text 쌍을 효과적으로 활용할 수 있게 해주는 stagewise pre-training 전략을 제안하였다.
Table of Contents
1. Introduction
2. Methods
2-1. Input Representations
2-2. Mixture-of-Modality-Experts Transformer
2-3. Pre-training Tasks
2-4. Stagewise Pre-training
2-5. Fine-Tuning VLMo on Downstream Tasks
3. Experiments
1. Introduction
Vision-Language(VL) pre-training에서는 2개의 주된 아키텍처가 사용되었다.
- dual encoder: 이미지와 텍스트를 따로따로 인코딩. modality 상호작용은 이미지와 텍스트 벡터의 코사인 유사도에 의해 조정됨. retrieval task에 효과적 & 얕은 상호작용으로 인해 복잡한 VL 분류 task에는 부적합
- fusion encoder: image-text 쌍을 모델링하기 위해 cross-modal attention을 사용. 다층 Transformer는 image & text representation을 융합하기 위해 사용. retrieval task를 위해 모든 가능한 image-text 쌍간에 코사인 유사도를 계산해야 하므로 더 많은 시간 복잡도와 느린 추론 속도를 가짐.
이 두 가지 유형의 아키텍처의 장점을 누리기 위해, 논문에서는 dual encoder & fusion encoder를 각 task를 위해 사용 가능한 Vision-Language pretrained Model(VLMo)를 제안하였다. 이는 다양한 modality(image, text, image-text pairs)를 Transformer 블록에서 인코딩할 수 있는 Mixture-of-Modality-Experts의 소개로 인해 가능해졌다. MoME는 기존 Transformer에서 feed-forward network(FFN)을 대체하기 위한 modality expert의 모임을 사용하였다. MoME는 서로 다른 modality expert 간에 스위치를 해서 modality-specific 정보를 얻을 수 있고, 공유된 self-attention을 modality 간에 사용해서 visual & linguistic 정보를 정렬할 수 있다. 이러한 MoME Transformer는 다음의 3가지 expert로 구성되어 있다. 그리고 MoME Transformer의 모델링 유연성 덕분에 서로 다른 목적에 대한 공유된 파라미터와 함께 MoME Transformer를 재사용할 수 있다.
- vision expert: image encoding을 수행
- language expert: text encoding을 수행
- vision-language expert: image-text fusion을 수행
VLMo는 3개의 pre-training task를 사용하여 공동으로 학습되었다: image-text contrastive learning(ITC), image-text matching(ITM), masked language modeling(MLM). 게다가 논문에서는 VLMo pre-training에서 대규모 image-only & text-only corpus & image-text 쌍을 효과적으로 활용하는 stagewise pre-training 전략을 제안하였다. stagewise pre-training 전략의 과정은 다음과 같다.
- vision expert & MoME Transformer의 self-attention을 image-only 데이터에서 MIM을 사용하여 pre-train
- language expert를 text-only 데이터에서 MLM을 사용하여 pre-train
최종적으로 모델은 vision-language pre-training을 초기화하기 위해 사용된다. image-text 쌍의 제한된 크기와 이들의 간단하고 짧은 캡션을 제거함으로써, 대규모의 image-only & text-only 데이터에서 stagewise pre-training은 VLMo가 더욱 일반적인 representation을 학습하도록 도와준다.
논문의 주된 contribution을 요약하면 다음과 같다.
- 분류 task를 위해 fusion encoder가 되기도 하고, retrieval task를 위해 dual encoder로 fine-tune되는 통합 vision-language pre-trained model인 VLMo를 제안 ✨
- general-purpose multi-modal Transformer인 서로 다른 modality를 인코딩하기 위한 MoME Transformer를 소개 ✨
- 대규모의 image-only & text-only 데이터를 사용하는 stagewise pre-training을 보여줌 ➡️ vision-language pre-trained model의 성능을 크게 향상시킴
2. Methods
image-text 쌍이 주어지면, VLMo는 MoME Transformer 네트워크로부터 image-only, text-only, image-text 쌍 representation을 얻게 된다. 그림 1에서 보이는 것처럼 통합 pre-training은 공유된 MoME Transformer를 image-only & text-only representation에서 ITC를 사용하여 최적화하고, image-text representation에서는 ITM을 사용하여 최적화한다. VLMo의 모델링 유연성 덕분에 다음과 같은 작업이 가능하다.
- dual encoder로 사용: retrieval task를 위해 fine-tuning 중에 이미지와 텍스트를 개별적으로 인코딩
- fusion encoder로 사용: 분류 task를 위해 이미지와 텍스트의 더 깊은 상호작용을 모델링
2-1. Input Representations
image-text 쌍이 주어지면, 논문에서는 이 쌍을 이미지, 텍스트, image-text 쌍 representation으로 인코딩한다. 이러한 representation들은 문맥화된 representation을 학습하고 이미지 feature vecotr와 텍스트 feature vecotr를 정렬하기 위해 MoME Transformer에 들어가게 된다.
Image Representations vision Transformer의 방식을 따라서 이미지를 패치화해서 벡터로 flatten 하고 linear projection을 사용해서 패치 임베딩을 얻었다. 그리고 패치 임베딩 앞에 학습 가능한 스페셜 토큰 [I_CLS]를 추가하였다. 마지막으로 패치 임베딩과 학습 가능한 1D position embedding과 image type embedding을 추가해서 가능과 같은 image input representation을 얻게 된다.
Text Representations BERT를 따라서 WordPiece tokenizer를 사용해서 텍스트를 subword로 토큰화하였다. 시퀀스의 시작을 알려주는 토큰 [T_CLS]와 스페셜 경계 토큰 [T_SEP]를 텍스트 시퀀스에 추가하였다. text input representation은 word embedding과 text position embedding, text type embedding을 합쳐서 다음과 같이 나온다.
Image-Text Representations 논문에서는 image-text input representation $\textbf{H}_{0}^{vl} = [\textbf{H}_{0}^{w};\textbf{H}_{0}^{v}]$을 형성하기 위해 이미지 입력 벡터와 텍스트 입력 벡터를 연결하였다.
2-2. Mixture-of-Modality-Experts Transformer
논문에서는 vision-language task를 위한 general-purpose multi-modal Transformer인 MoME Transformer를 제안하였다. MoME Transformer는 modality expert의 모음을 기존 Transformer의 feed forward network(FFN)을 대체하기 위해 소개하였다. 이전 레이어의 출력 벡터 $\textbf{H}_{L-1}, l \in [1, L]$이 주어지면, 각각의 expert는 visual & linguistic contents를 정렬하기 위해 multi-head self-attention(MSA)를 modality 간에 사용하였다. 아래 수식에서 LN은 layer normalization의 약자이다. 그림 1의 MoME Transformer의 구조를 보면서 수식을 보면 이해하기 쉽다.
MoME-FFN은 입력 벡터 $\textbf{H}_{l}^{'}$의 modality에 해당하는 입력과 Transformer layer의 인덱스를 처리하기 위해 여러 modality expert 중에서 expert를 선택한다. 여기에는 3개의 modality expert가 있다: vision expert(V-FFN), language expert(L-FFN), vision-language expert(VL-FFN). 상황에 따라서 다른 expert가 사용되는데 그 상황은 다음과 같다.
- 입력이 image-only 또는 text-only 벡터로 이루어져 있으면 ➡️ 이미지 인코딩을 위해 vision expert 사용 또는 텍스트 인코딩을 위해 text expert 사용
- 입력이 여러 modality(image-text 쌍)의 벡터로 이루어져 있으면 ➡️ Transformer layer의 바닥 쪽에서 각각의 modality 벡터를 인코딩하기 위해 vision expert와 text expert 사용. 그다음에 vision-language expert는 위쪽 레이어에서 사용돼서 더 많은 modality 상호작용을 캡처함.
3가지 유형의 입력 벡터가 들어오면, image-only, text-only, image-text 쌍의 문맥화된 representation을 얻게 된다.
2-3. Pre-training Tasks
VLMo는 이미지와 텍스트 representation에서 ITC를 통해, 공유된 파라미터를 사용하는 image-text 쌍 representation에서 MLM과 ITM을 통해 공동으로 pre-train 된다.
VLMo에 사용되는 pre-training task인 ITC, MLM, ITM의 방식은 기존의 방식과 똑같다. 이중에 ITM에서는 기존과 살짝 다른 방식을 사용하였는데, 기존에는 단일 GPU에서 hard negative 샘플을 사용한 반면에, 논문에서는 global hard negative mining을 제안하고 모든 GPU로부터 모여진 더욱 많은 training example로부터 hard negative image-text 쌍을 샘플링하였다. global hard negative mining은 더욱 정보적인 image-text 쌍을 찾을 수 있고 더욱 향상된 모델을 얻을 수 있게 해 준다.
2-4. Stagewise Pre-training
논문에서는 vision-language 모델을 향상시키기 위해 대규모 image-only & text-only corpus를 활용하는 stagewise pre-training을 소개하였다. 그림 2에서 보이는 것처럼, 논문에서는 처음에 image-only 데이터에서 vision pre-training을 수행하고, 그다음에 image & text representation을 학습하기 위해 text-only 데이터에서 language pre-training을 수행하였다. 모델은 visual & linguistic 정보의 정렬을 학습하기 위해 vision-language pre-training을 초기화하기 위해 사용된다. vision pre-training을 위해 MoME Transformer의 vision expert와 attention module을 BEIT로 image-only 데이터에서 학습시켰다. 논문에서는 attention module과 vision expert를 초기화하기 위해 pre-train 된 BEIT의 파라미터를 활용하였다. language pre-training을 위해서, attention module의 파라미터와 vision expert를 동결시켜 놓고 text-only 데이터에서 language expert를 최적화하기 위해 MLM을 활용하였다. image-text 쌍과 비교하여 text-only 데이터는 수집하기 더 쉽다. 게다가, image-text 쌍의 텍스트 데이터는 대게 짧거나 간단하다. 그래서 image-only와 text-only corpus에서 pre-training을 하면 복잡한 쌍에서의 일반화를 향상시켜준다.
2-5 Fine-tuning VLMo on Downstream Tasks
그림 3에 나타나 있는 것처럼, 논문의 모델은 다양한 vision-language retrieval과 분류 task에 적응하기 위해 fine-tune 될 수 있다.
VIsion-Language Classification VQA나 visual reasoning과 같은 분류 task에 대해, VLMo는 이미지와 텍스트의 modality 상호작용을 모델링하기 위해 fusion encoder처럼 사용된다. 논문에서는 토큰 [T_CLS]의 최종 인코딩 벡터를 image-text 쌍의 representation으로 사용하고, 이를 task-specific 분류기 레이어에 넣어서 라벨을 예측한다.
Vision-Language Retrieval retrieval task에 대해, VLMo는 이미지와 텍스트를 따로따로 인코딩하기 위해 dual encoder처럼 사용될 수 있다. fine-tuning 중에 VLMo는 ITC loss에 대해 최적화된다. 추론 중에는 모든 이미지와 텍스트의 representation을 계산하고, 그다음에 모든 가능한 image-text 쌍의 image-to-text & text-to-image 유사도 스코어를 얻기 위해 내적을 사용한다. 각각의 인코딩은 fusion-encoder-based model보다 더 빠른 추론 속도를 가능하게 한다.
3. Experiments
논문에서는 VLMo를 대규모 image-text 쌍을 사용하여 pre-train 하고 visual-linguistic classification & retrieval task에서 평가하였다. 사용된 pre-training 데이터로는 총 4개의 image captioning 데이터셋이 사용되었다: Conceptual Captions(CC), SBU Captions, COCO, VIsual Genome(VG).
3-1. Training on Larget-scale Datasets
논문에서는 VLMo-Large를 큰 배치 사이즈를 사용하는 10억 개의 noisy web image-text 쌍에서 학습함으로써 vision-language representation learning의 규모를 늘렸다.
3-2. Evaluation on Vision-Language Classification Tasks
논문에서는 두 개의 널리 사용되는 분류 데이터셋에서 fine-tuning 실험을 진행하였다: VQA & NLVR2. 모델은 더 깊은 상호작용을 위해 fusion encoder로 fine-tune 되었다. 각 task에 대한 설명은 생략하고 VLMo에서 사용된 방법에 대해 자세하게 다루도록 하겠다.
Visual Question Answering(VQA) [I_CLS] 토큰의 최종 인코딩 벡터를 image-question 쌍의 representation으로 사용하고, 이를 분류기 레이어에 넣어서 answer를 예측하게 한다.
Natural Language for Visual Reasoning(NLVR2) 2 입력 쌍의 [T_CLS] 토큰의 최종 출력 벡터를 연결한다. 연결된 벡터는 분류기 레이어에 들어가서 라벨을 예측한다.
표 1에서는 VL classification task의 결과를 보여주고 있다. VLMo는 SoTA를 달성하고 이전 모델보다 상당히 향상된 성능을 보여주고 있다. 특히 더 많은 파라미터와 데이터로 학습된 모델들보다 더 나은 성능들을 보여주고 있다. 그리고 VLMo는 이미지를 임베딩하기 위해 간단한 linear projection을 사용함으로써 이전의 모델들보다 상당히 빨라진 속도를 보여주고 있다.
3-3. Evaluation on Vision-Language Retrieval Tasks
retrieval task는 image-to-text retrieval과 text-to-image retrieval를 포함하고 있다. 논문에서는 VLMo를 널리 사용되는 COCO와 Flickr30k에서 평가하고, 두 데이터셋에 대해 Karpathy 분할을 사용하였다. VLMo는 retrieval task를 위해 dual encoder로 사용되었다. 논문에서는 이미지와 텍스트를 따로따로 인코딩하고 이들의 유사도 스코어를 이미지 벡터와 텍스트 벡터의 내적으로 계산하였다.
표 2에 나타나 있는 것처럼, VLMo는 이전의 fusion-encoder-based 모델과 견줄 만한 성능을 보여주는 반면 더 빠른 속도를 자랑하였다. fusion-encoder-based 모델은 모든 가능한 image-text 쌍을 유사도 스코어를 계산하기 위해 인코딩해야 해서 더 많은 시간 복잡도를 필요로 한다. 게다가, VLMo large-size model은 더 큰 배치 사이즈를 사용하는 더 많은 데이터에서 학습된 모델보다 좋은 성능을 보여줬다. VLMo pre-training은 효과적으로 대규모 noisy 쌍을 활용할 수 있고 거대한 batch training에서 이익을 볼 수 있다.
3-4. Evaluation on Vision Tasks
표 3에서 보이는 것처럼, 논문에서는 VLMo를 image-only encoder로 사용해서 이미지 분류(ImageNet)와 semantic segmentation(ADE20K) task에서 평가하였다. VLMo는 유망한 성능을 보여줬고, BEIT보다 살짝 나은 성능을 보여줬다.
3-5. Ablation Studies
Stagewise Pre-training 표 4를 보면 알 수 있듯이, image-only pre-training + text-only pre-training은 vision-language model의 성능을 향상시켰다. stagewise pre-training은 대규모 image-only & text-only corpus를 효과적으로 활용하고, vision-language pre-training을 향상시킨다.
MoME Transformer 표 5에 나타나 있는 것처럼 MoME Transformer를 사용하면 retrieval & 분류 task에서 기존의 Transformer보다 더 나은 성능을 보여준다. 그리고 VL-FFN 또한 성능 향상에 도움을 준다. 추가적으로 MoME Transformer에서 사용되는 공유된 self-attention 모듈은 모델에 도움을 준다.
Global Hard Negative Mining ALBEF와 달리 VLMo는 모든 GPU의 학습 예시를 모음으로써 더 많은 후보자로부터 hard negative mining을 수행한다. 표 6에서 보이는 것처럼 global hard negative mining은 상당한 성능 향상을 불러온다.
출처
https://arxiv.org/abs/2111.02358
VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
We present a unified Vision-Language pretrained Model (VLMo) that jointly learns a dual encoder and a fusion encoder with a modular Transformer network. Specifically, we introduce Mixture-of-Modality-Experts (MoME) Transformer, where each block contains a
arxiv.org